
演练:评估
学习评估所有内容的指导性演练
最后更新:2025 年 7 月 9 日评估使用精确率、召回率和相关性等指标来衡量性能,利用大型语言模型或基础事实标签清晰地展示您流水线的优势和劣势。
评估 RAG 系统有助于了解性能瓶颈,并一次优化一个组件,例如检索器或与生成器一起使用的提示。
以下是分步指南,解释了您需要评估的内容、如何评估以及如何使用 Haystack 在评估后改进您的应用程序!
1. 构建您的流水线
根据您的用例选择所需的组件,并创建您的 Haystack 流水线。如果您是初学者,请从📚 教程:使用检索增强创建您的第一个 QA 流水线开始。如果您想使用 Haystack 探索不同的模型提供商、向量数据库、检索技术等,请从🧑🍳 Haystack Cookbooks 中选择一个示例。
2. 人工评估
作为第一步,进行人工评估。测试几个查询(5-10 个查询),并手动评估流水线输出的准确性、相关性、连贯性、格式和整体质量。这将提供对系统性能的初步了解,并突出任何明显的问
要跟踪数据通过每个流水线步骤,请使用 include_outputs_from 参数调试中间组件。此功能对于观察检索到的文档或验证渲染的提示特别有用。通过检查这些中间输出,您可以精确定位可能出现问题的区域,并确定需要改进的具体领域,例如调整提示或尝试不同的模型。
3. 确定指标
评估指标对于衡量流水线的有效性至关重要。常见指标包括:
- 语义答案相似度:评估生成答案与基础事实之间的语义相似度,而不是它们的词汇重叠度。
- 上下文相关性:评估检索到的文档与查询的相关性。
- 忠实度:评估生成答案在多大程度上基于检索到的文档。
- 上下文精度:衡量检索到的文档的准确性。
- 上下文召回率:衡量检索所有相关文档的能力。
一些指标可能需要标记数据,而另一些则可以使用大型语言模型进行评估,而无需标记数据。在评估流水线时,请探索各种指标类型,例如统计和基于模型的指标,或使用 LLMEvaluator 集成自定义指标。
| 检索评估 | 生成评估 | 端到端评估 | |
|---|---|---|---|
| 标记数据 | DocumentMAPEvaluator、DocumentMRREvaluator、DocumentRecallEvaluator | - | AnswerExactMatchEvaluator、SASEvaluator |
| 未标记数据(基于 LLM) | ContextRelevanceEvaluator | FaithfulnessEvaluator | LLMEvaluator** |
** 您需要向 LLM 提供指令和示例来评估您的系统。
除了 Haystack 的内置评估器外,您还可以使用其他评估框架的指标,例如ragas 和DeepEval。有关评估指标的更多详细信息,请参阅 📖 文档:评估。
4. 构建评估流水线
构建包含评估器的流水线。要了解如何使用 Haystack 自有指标进行评估,您可以按照 📚 教程:评估 RAG 流水线 进行操作。
🧑🍳 除了 Haystack 自有的评估指标外,您还可以与许多评估框架集成。请参阅下面的集成和示例 👇
有关分步说明,请观看我们的视频演练 🎥 👇
为了进行全面评估,请务必评估流水线中的特定步骤(例如,检索或生成)以及整个流水线的性能。要获得评估流水线的灵感,请查看 🧑🏼🍳Cookbook:使用 DSPy 进行提示优化,其中解释了提示优化和评估的详细信息,或阅读 📚文章:使用 Prometheus 2 进行 RAG 评估,其中探讨了如何使用开放式 LM 进行自定义指标评估。
如果您正在寻找一种简单高效的 RAG 解决方案,请考虑使用 `EvaluationHarness`,它通过 `haystack-experimental` 在 Haystack 2.3 中引入。您可以通过运行示例 💻 Notebook:使用 EvaluationHarness 评估 RAG 流水线 来了解更多信息。
5. 运行评估
运行评估的目标是衡量流水线的性能并检测任何回归。要跟踪进度,必须使用现成的常用方法(如 BM25 进行关键字检索或“sentence-transformers”模型进行嵌入)来建立基线指标。然后,通过各种参数继续评估您的流水线:调整 `top_k` 值,尝试不同的嵌入模型,调整 `temperature`,并对结果进行基准测试,以确定最适合您用例的方法。如果评估需要标记数据,您可以使用包含基础事实文档和答案的数据集。此类数据集可在Hugging Face 数据集或haystack-evaluation 存储库中找到。
确保您的评估环境已设置,以便轻松测试不同的参数。haystack-evaluation 存储库提供了针对不同数据集的各种架构的示例。
有关通过尝试不同的参数组合优化流水线的更多信息,请参阅 📚 文章:对 Haystack 流水线进行基准测试以获得最佳性能。
6. 分析结果
可视化数据和结果,以对流水线的性能有一个总体了解。
- 使用 EvaluationRunResult.score_report() 创建报告,并将评估结果转换为 Pandas DataFrame,其中包含每个指标的汇总分数。
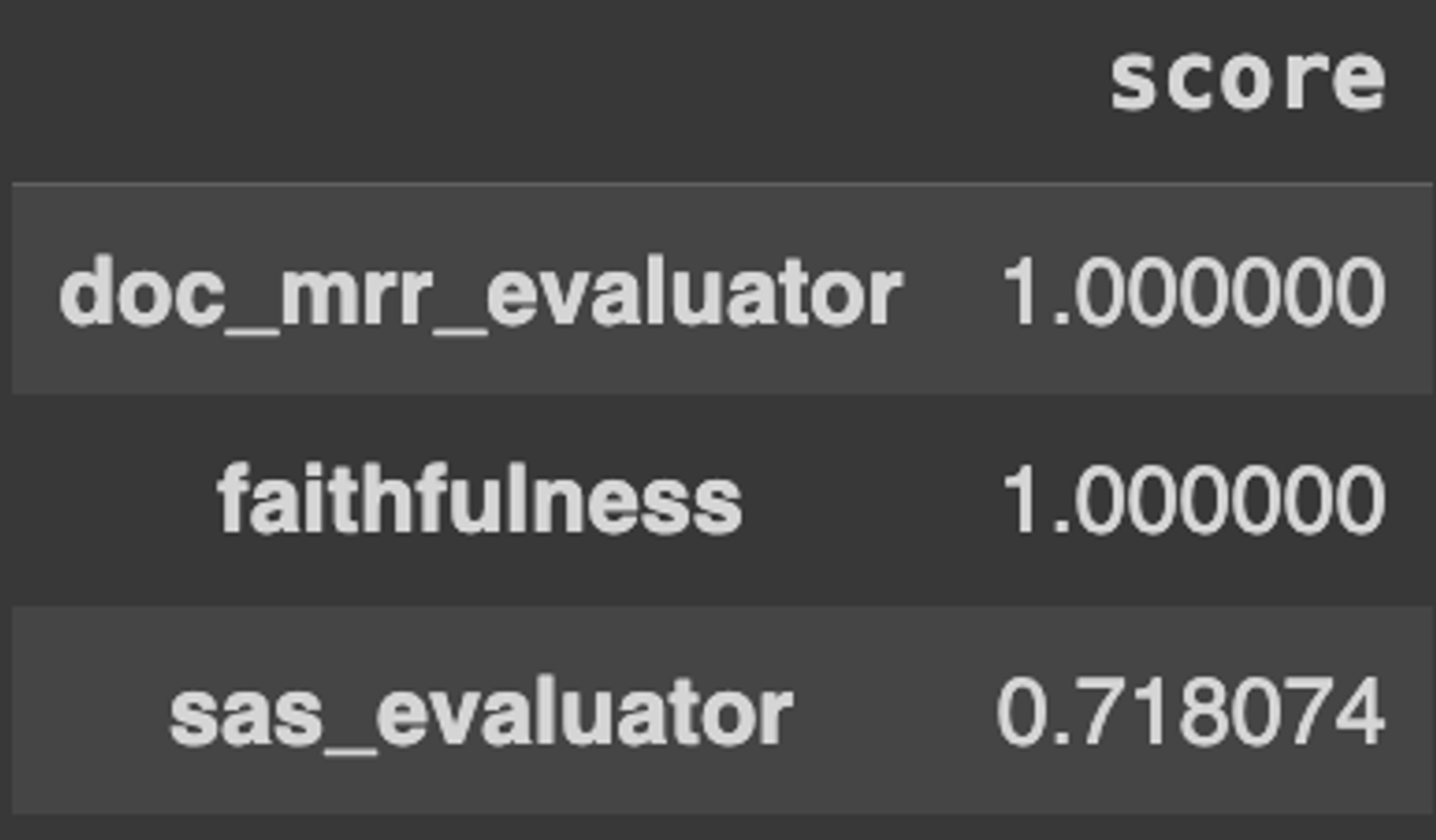
- 使用 Pandas 分析不同参数(`top_k`、`batch_size`、`embedding_model`)的结果,以获得全面的视图。
- 使用 Matplotlib 或 Seaborn 等库直观地表示评估结果。
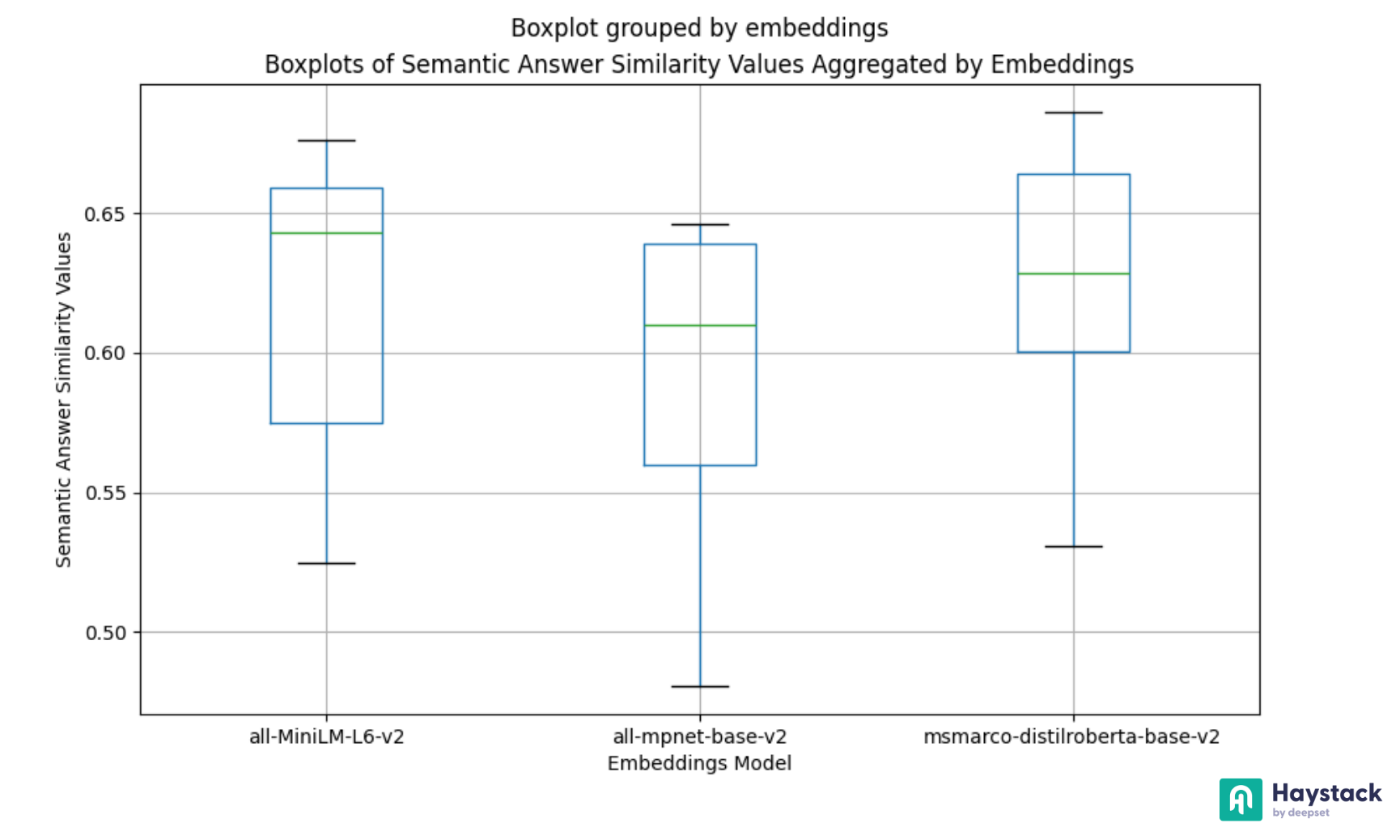
请参阅 📚 对 Haystack 流水线进行基准测试以获得最佳性能:结果分析 或 💻 Notebook:分析 ARAGOG 参数搜索 来可视化评估结果。
7. 改进您的流水线
评估后,分析结果以确定需要改进的领域。以下是一些方法:
改进检索的方法
- 数据清理:在使用 DocumentCleaner 和 DocumentSplitter 进行索引之前,请确保数据干净且结构良好。
- 数据质量:通过嵌入有意义的元数据以及文档内容来丰富文档的语义。
- 元数据过滤:使用元数据过滤器或从查询中提取元数据作为过滤器来限制搜索空间。有关更多详细信息,请阅读 📚从查询中提取元数据以改进检索。
- 不同的嵌入模型:比较来自不同模型提供商的各种嵌入模型。在Embedders 中查找支持的嵌入提供商的完整列表。
- 高级检索技术:利用混合检索、稀疏嵌入或假设文档嵌入 (HYDE) 等技术。
改进生成的方法
- 排序:在将上下文提供给提示之前,将排序机制集成到检索到的文档中。
- 按相似度排序:使用 Hugging Face 的交叉编码器模型和TransformersSimilarityRanker,Cohere 的 Rerank 模型和CohereRanker,或 Jina 的 Rerankers 和JinaRanker,按相似度重新排序检索到的文档。
- 通过排序增加多样性:使用 sentence-transformers 模型和SentenceTransformersDiversityRanker 来最大化上下文中的整体多样性,以帮助提高 LFQA 应用中的语义答案相似度 (SAS)。
- 解决“迷失中间”问题:通过LostInTheMiddleRanker 将最相关的文档放在上下文的开头和结尾,以提高忠实度。
- 不同的生成器:尝试不同的语言模型并进行基准测试。模型提供商的完整列表在Generators 中。
- 提示工程:使用少样本提示或提供更多指令以启用精确匹配。
8. 监控
实施跟踪应用程序部署后部署的策略。通过将LangfuseConnector 集成到您的流水线中,您可以收集查询、文档和答案,并使用它们来持续评估您的应用程序。有关流水线监控的更多信息,请参阅 📚文章:使用 Langfuse 监控和跟踪您的 Haystack 流水线。