

Haystack 流水线基准测试以获得最佳性能
分步说明评估和优化 RAG 流水线性能
2024 年 6 月 24 日在本文中,我们将向您展示如何使用 Haystack 来评估 RAG 流水线的性能。请注意,本文中的代码仅用于说明目的,可能无法直接运行;如果您想运行代码,请参阅 python 脚本。
简介
本文将指导您使用 Haystack 构建检索增强生成 (RAG) 流水线,调整各种参数,并使用 ARAGOG 数据集对其进行评估。该数据集包含问题和答案对,我们的目标是评估 RAG 流水线在检索正确上下文和生成准确答案方面的效率。为此,我们将使用以下评估指标
我们通过依赖三个具有不同目的的 Haystack 流水线进行了此实验:一个用于索引,一个用于 RAG,一个用于评估。我们详细描述了这些流水线中的每一个,并展示了如何将它们组合在一起以评估 RAG 流水线。
本文的组织结构如下:首先描述 ARAGOG 数据集的来源和作者,然后构建流水线。接着演示如何集成所有内容,对数据集进行多次运行并调整参数。这些参数的选择基于我们社区的反馈,反映了用户如何优化他们的流水线。
top_k:检索器返回的最大文档数。对于此实验,我们测试了具有top_k值为[1, 2, 3]的流水线。embedding_model:用于对文档和问题进行编码的模型。在此示例中,我们使用了这些 sentence-transformers 模型all-MiniLM-L6-v2msmarco-distilroberta-base-v2all-mpnet-base-v2
chunk_size:构成要嵌入和索引的文本片段的输入文本中的令牌数。对于此实验,我们测试了具有chunk_size值为[64, 128, 256]的流水线。
最后,我们讨论评估结果并分享一些经验教训。
“ARAGOG:高级 RAG 输出评分”数据集
知识数据以及问题和答案均来自 ARAGOG:高级 RAG 输出评分 论文。该数据是 AI ArXiv 数据集 的一个子集,包含 423 篇围绕 Transformer 和大型语言模型 (LLM) 主题的研究论文。
评估数据集包含 107 个问答对 (QA),这些问答对是在 GPT-4 的协助下生成的。每个 QA 对都经过人工验证和更正,确保评估正确,并准确衡量 RAG 技术在实际应用中的性能。
在本篇文章的范围内,为了降低计算成本,我们只考虑了 16 篇论文,即问题所来自的论文,而不是原始数据集中 423 篇论文。
索引管道
索引流水线负责预处理文档并将它们存储在 DocumentStore 中。我们将定义一个包装流水线的函数,该函数接受嵌入模型和块大小作为参数,并返回一个 DocumentStore 以供将来使用。函数中的流水线首先将 PDF 文件转换为 Document,对其进行清理,将它们拆分成块,然后使用 SentenceTransformers 模型对其进行嵌入。然后将嵌入存储在 InMemoryDocumentStore 中。在 📚 教程:预处理不同文件类型 中了解有关创建索引流水线的更多信息。
在此示例中,我们使用
InMemoryDocumentStore存储文档,但您可以使用 Haystack 支持的任何 其他文档存储。我们按单词拆分文档,但您可以通过更改DocumentSplitter组件中split_by参数的值,按句子或段落进行拆分。
我们需要将 embedding_model 和 chunk_size 参数传递给此索引流水线函数,因为我们希望尝试不同的索引方法。
索引流水线函数定义如下
import os
from haystack import Pipeline
from haystack.document_stores.in_memory import InMemoryDocumentStore
from haystack.components.converters import PyPDFToDocument
from haystack.components.embedders import SentenceTransformersDocumentEmbedder
from haystack.components.preprocessors import DocumentCleaner, DocumentSplitter
from haystack.components.writers import DocumentWriter
from haystack.document_stores.types import DuplicatePolicy
def indexing(embedding_model: str, chunk_size: int):
files_path = "datasets/ARAGOG/papers_for_questions"
document_store = InMemoryDocumentStore()
pipeline = Pipeline()
pipeline.add_component("converter", PyPDFToDocument())
pipeline.add_component("cleaner", DocumentCleaner())
pipeline.add_component("splitter", DocumentSplitter(split_length=chunk_size)) # default splitting by word
pipeline.add_component("writer", DocumentWriter(document_store=document_store, policy=DuplicatePolicy.SKIP))
pipeline.add_component("embedder", SentenceTransformersDocumentEmbedder(embedding_model))
pipeline.connect("converter", "cleaner")
pipeline.connect("cleaner", "splitter")
pipeline.connect("splitter", "embedder")
pipeline.connect("embedder", "writer")
pdf_files = [files_path+"/"+f_name for f_name in os.listdir(files_path)]
pipeline.run({"converter": {"sources": pdf_files}})
return document_store
RAG 流水线
我们使用一个简单的 RAG 流水线,由一个检索器、一个提示构建器、一个语言模型和一个答案构建器组成。首先,我们使用 SentenceTransformersTextEmbedder 来嵌入查询,并使用 InMemoryEmbeddingRetriever 来检索与查询相关的 top-k 个文档。然后,我们依靠 LLM 根据从文档中检索到的上下文和查询问题来生成答案。
在我们的实现中,我们通过 OpenAIGenerator 和 gpt-3.5-turbo 模型使用了 OpenAI API。PromptBuilder 负责使用包含上下文和问题的模板来构建要馈送给 LLM 的提示。最后,AnswerBuilder 负责从 LLM 输出中提取答案并返回。在 📚 教程:使用检索增强创建您的第一个 QA 流水线 中了解有关创建 RAG 流水线的更多信息。
请注意,我们指示 LLM 在上下文为空时明确回答
"None"。这样做是为了避免 LLM 使用其内部知识回答提示。
创建流水线后,我们将其包装在一个函数中,以便使用不同的参数轻松初始化它。我们需要此函数提供 document_store、embedding_model 和 top_k。
RAG 流水线定义如下
from haystack import Pipeline
from haystack.components.builders import PromptBuilder, AnswerBuilder
from haystack.components.embedders import SentenceTransformersTextEmbedder
from haystack.components.generators import OpenAIGenerator
from haystack.components.retrievers import InMemoryEmbeddingRetriever
def rag_pipeline(document_store, embedding_model, top_k=2):
template = """
You have to answer the following question based on the given context information only.
If the context is empty or just a '\\n' answer with None, example: "None".
Context:
{% for document in documents %}
{{ document.content }}
{% endfor %}
Question: {{question}}
Answer:
"""
basic_rag = Pipeline()
basic_rag.add_component("query_embedder", SentenceTransformersTextEmbedder(
model=embedding_model, progress_bar=False
))
basic_rag.add_component("retriever", InMemoryEmbeddingRetriever(document_store, top_k=top_k))
basic_rag.add_component("prompt_builder", PromptBuilder(template=template))
basic_rag.add_component("llm", OpenAIGenerator(model="gpt-3.5-turbo"))
basic_rag.add_component("answer_builder", AnswerBuilder())
basic_rag.connect("query_embedder", "retriever.query_embedding")
basic_rag.connect("retriever", "prompt_builder.documents")
basic_rag.connect("prompt_builder", "llm")
basic_rag.connect("llm.replies", "answer_builder.replies")
basic_rag.connect("llm.meta", "answer_builder.meta")
basic_rag.connect("retriever", "answer_builder.documents")
return basic_rag
评估流水线
我们还需要一个评估流水线,它将负责计算评分指标以衡量 RAG 流水线的性能。您可以在 📚 教程:评估 RAG 流水线 中了解如何构建评估流水线。评估流水线将包含三个评估器
- ContextRelevanceEvaluator 将评估检索到的上下文与回答查询问题的相关性
- FaithfulnessEvaluator 评估生成的答案是否可以从上下文中得出
- SASEvaluator 根据通用嵌入模型,将生成的答案的嵌入与地面真实答案进行比较。
此新函数返回评估结果以及用于运行评估的输入。这些数据对于后续分析和更详细、更精细地理解流水线性能非常有用。我们需要将数据集中 questions 和 answers 传递给函数,以及 RAG 流水线生成的数据,即 retrieved_contexts、predicted_answers 和用于这些结果的 embedding_model。
from haystack import Pipeline
from haystack.components.evaluators import ContextRelevanceEvaluator, FaithfulnessEvaluator, SASEvaluator
def evaluation(questions, answers, retrieved_contexts, predicted_answers, embedding_model):
eval_pipeline = Pipeline()
eval_pipeline.add_component("context_relevance", ContextRelevanceEvaluator(raise_on_failure=False))
eval_pipeline.add_component("faithfulness", FaithfulnessEvaluator(raise_on_failure=False))
eval_pipeline.add_component("sas", SASEvaluator(model=embedding_model))
eval_pipeline_results = eval_pipeline.run(
{
"context_relevance": {"questions": questions, "contexts": retrieved_contexts},
"faithfulness": {"questions": questions, "contexts": retrieved_contexts, "predicted_answers": predicted_answers},
"sas": {"predicted_answers": predicted_answers, "ground_truth_answers": answers},
}
)
results = {
"context_relevance": eval_pipeline_results['context_relevance'],
"faithfulness": eval_pipeline_results['faithfulness'],
"sas": eval_pipeline_results['sas']
}
inputs = {
'questions': sample_questions,
'contexts': retrieved_contexts,
'true_answers': sample_answers,
'predicted_answers': predicted_answers
}
return results, inputs
整合
现在我们已经具备了评估 RAG 流水线的构建块:索引知识数据,使用 RAG 架构生成答案,以及评估结果。但是,我们仍然需要一种方法来运行我们的 RAG 流水线上的问题,并收集所有必要的结果来进行评估。我们将使用一个封装了与 RAG 流水线所有交互的函数。它以 document_store、questions、embedding_model 和 top_k 作为参数,并返回检索到的上下文和预测的答案。
def run_rag(document_store, sample_questions, embedding_model, top_k):
"""
A function to run the basic rag model on a set of sample questions and answers
"""
rag = rag_pipeline(document_store=document_store, embedding_model=embedding_model, top_k=top_k)
predicted_answers = []
retrieved_contexts = []
for q in tqdm(sample_questions):
try:
response = rag.run(
data={"query_embedder": {"text": q}, "prompt_builder": {"question": q}, "answer_builder": {"query": q}})
predicted_answers.append(response["answer_builder"]["answers"][0].data)
retrieved_contexts.append([d.content for d in response['answer_builder']['answers'][0].documents])
except BadRequestError as e:
print(f"Error with question: {q}")
print(e)
predicted_answers.append("error")
retrieved_contexts.append(retrieved_contexts)
return retrieved_contexts, predicted_answers
请注意,我们将 RAG 流水线的调用包装在 try-except 块中,以处理流水线执行期间可能发生的任何错误。例如,如果提示太大(由于上下文很长)导致模型无法生成答案,如果出现网络错误,或者模型因其他任何原因无法生成答案,都可能发生这种情况。
您可以决定基于 LLM 的评估器是否在找到错误时立即停止,或者它们是忽略特定样本的评估并继续进行。例如,在 ContextRelevanceEvaluator 中,查看
raise_on_failure参数。
最后,我们需要在数据集上运行整个查询问题通过流水线,针对 top_k、embedding_model 和 chunk_size 的所有可能组合。这由下一个函数处理。
请注意,对于索引,我们只改变
embedding_model和chunk_size,因为top_k参数不影响索引。
def parameter_tuning(out_path: str):
base_path = "../datasets/ARAGOG/"
with open(base_path + "eval_questions.json", "r") as f:
data = json.load(f)
questions = data["questions"]
answers = data["ground_truths"]
embedding_models = {
"sentence-transformers/all-MiniLM-L6-v2",
"sentence-transformers/msmarco-distilroberta-base-v2",
"sentence-transformers/all-mpnet-base-v2"
}
top_k_values = [1, 2, 3]
chunk_sizes = [64, 128, 256]
# create results directory
out_path = Path(out_path)
out_path.mkdir(exist_ok=True)
for embedding_model in embedding_models:
for chunk_size in chunk_sizes:
print(f"Indexing documents with {embedding_model} model with a chunk_size={chunk_size}")
doc_store = indexing(embedding_model, chunk_size)
for top_k in top_k_values:
name_params = f"{embedding_model.split('/')[-1]}__top_k:{top_k}__chunk_size:{chunk_size}"
print(name_params)
print("Running RAG pipeline")
retrieved_contexts, predicted_answers = run_rag(doc_store, questions, embedding_model, top_k)
print(f"Running evaluation")
results, inputs = evaluation(questions, answers, retrieved_contexts, predicted_answers, embedding_model)
eval_results = EvaluationRunResult(run_name=name_params, inputs=inputs, results=results)
eval_results.score_report().to_csv(f"{out_path}/score_report_{name_params}.csv", index=False)
eval_results.to_pandas().to_csv(f"{out_path}/detailed_{name_params}.csv", index=False)
此函数将结果存储在 out_path 参数指定的目录中。结果将存储在 .csv 文件中。对于每种参数组合,将生成两个文件:一个文件包含所有问题的汇总分数报告(例如:score_report_all-MiniLM-L6-v2__top_k:3__chunk_size:128.csv),另一个文件包含每个问题的详细结果(例如:detailed_all-MiniLM-L6-v2__top_k:3__chunk_size:128.csv)。
请注意,我们使用 EvaluationRunResult 来存储结果并将分数报告和详细结果生成到 .csv 文件中。
在下一节中,我们将展示评估结果并讨论从实验中获得的见解。
结果分析
您可以运行 此笔记本 来可视化和分析结果。所有相关的
.csv文件都可以在 aragog_parameter_search_2024_06_12 文件夹 中找到。
为了便于分析结果,我们将从多个 .csv 文件中加载不同参数组合的所有汇总分数报告到一个 DataFrame 中。为此,我们使用以下代码解析文件内容
import os
import re
import pandas as pd
def parse_results(f_name: str):
pattern = r"score_report_(.*?)__top_k:(\\d+)__chunk_size:(\\d+)\\.csv"
match = re.search(pattern, f_name)
if match:
embeddings_model = match.group(1)
top_k = int(match.group(2))
chunk_size = int(match.group(3))
return embeddings_model, top_k, chunk_size
else:
print("No match found")
def read_scores(path: str):
all_scores = []
for root, dirs, files in os.walk(path):
for f_name in files:
if not f_name.startswith("score_report"):
continue
embeddings_model, top_k, chunk_size = parse_results(f_name)
df = pd.read_csv(path+"/"+f_name)
df.rename(columns={'Unnamed: 0': 'metric'}, inplace=True)
df_transposed = df.T
df_transposed.columns = df_transposed.iloc[0]
df_transposed = df_transposed[1:]
# Add new columns
df_transposed['embeddings'] = embeddings_model
df_transposed['top_k'] = top_k
df_transposed['chunk_size'] = chunk_size
all_scores.append(df_transposed)
df = pd.concat(all_scores)
df.reset_index(drop=True, inplace=True)
df.rename_axis(None, axis=1, inplace=True)
return df
然后,我们可以从 CSV 文件中读取分数并分析结果。
df = read_scores('aragog_results/')
现在我们可以分析单个表中的结果
| context_relevance | faithfulness | sas | embeddings | top_k | chunk_size |
|---|---|---|---|---|---|
| 0.834891 | 0.738318 | 0.524882 | all-MiniLM-L6-v2 | 1 | 64 |
| 0.869485 | 0.895639 | 0.633806 | all-MiniLM-L6-v2 | 2 | 64 |
| 0.933489 | 0.948598 | 0.65133 | all-MiniLM-L6-v2 | 3 | 64 |
| 0.843447 | 0.831776 | 0.555873 | all-MiniLM-L6-v2 | 1 | 128 |
| 0.912355 | NaN | 0.661135 | all-MiniLM-L6-v2 | 2 | 128 |
| 0.94463 | 0.928349 | 0.659311 | all-MiniLM-L6-v2 | 3 | 128 |
| 0.912991 | 0.827103 | 0.574832 | all-MiniLM-L6-v2 | 1 | 256 |
| 0.951702 | 0.925456 | 0.642837 | all-MiniLM-L6-v2 | 2 | 256 |
| 0.909638 | 0.932243 | 0.676347 | all-MiniLM-L6-v2 | 3 | 256 |
| 0.791589 | 0.67757 | 0.480863 | all-mpnet-base-v2 | 1 | 64 |
| 0.82648 | 0.866044 | 0.584507 | all-mpnet-base-v2 | 2 | 64 |
| 0.901218 | 0.890654 | 0.611468 | all-mpnet-base-v2 | 3 | 64 |
| 0.897715 | 0.845794 | 0.538579 | all-mpnet-base-v2 | 1 | 128 |
| 0.916422 | 0.892523 | 0.609728 | all-mpnet-base-v2 | 2 | 128 |
| 0.948038 | NaN | 0.643175 | all-mpnet-base-v2 | 3 | 128 |
| 0.867887 | 0.834112 | 0.560079 | all-mpnet-base-v2 | 1 | 256 |
| 0.946651 | 0.88785 | 0.639072 | all-mpnet-base-v2 | 2 | 256 |
| 0.941952 | 0.91472 | 0.645992 | all-mpnet-base-v2 | 3 | 256 |
| 0.909813 | 0.738318 | 0.530884 | msmarco-distilroberta-base-v2 | 1 | 64 |
| 0.88004 | 0.929907 | 0.600428 | msmarco-distilroberta-base-v2 | 2 | 64 |
| 0.918135 | 0.934579 | 0.67328 | msmarco-distilroberta-base-v2 | 3 | 64 |
| 0.885314 | 0.869159 | 0.587424 | msmarco-distilroberta-base-v2 | 1 | 128 |
| 0.953649 | 0.919003 | 0.664224 | msmarco-distilroberta-base-v2 | 2 | 128 |
| 0.945016 | 0.936916 | 0.68591 | msmarco-distilroberta-base-v2 | 3 | 128 |
| 0.949844 | 0.866822 | 0.613355 | msmarco-distilroberta-base-v2 | 1 | 256 |
| 0.952544 | 0.893769 | 0.662694 | msmarco-distilroberta-base-v2 | 2 | 256 |
| 0.964182 | 0.943925 | 0.62854 | msmarco-distilroberta-base-v2 | 3 | 256 |
我们看到 faithfulness 分数有一些 NaN 值,这是基于 LLM 的评估器。这是由于调用 OpenAI API 时发生了网络错误。
现在让我们看看哪种参数配置产生了最佳的语义相似度答案分数
df.sort_values(by=['sas'], ascending=[False])
| context_relevance | faithfulness | sas | embeddings | top_k | chunk_size |
|---|---|---|---|---|---|
| 0.945016 | 0.936916 | 0.68591 | msmarco-distilroberta-base-v2 | 3 | 128 |
| 0.909638 | 0.932243 | 0.676347 | all-MiniLM-L6-v2 | 3 | 256 |
| 0.918135 | 0.934579 | 0.67328 | msmarco-distilroberta-base-v2 | 3 | 64 |
| 0.953649 | 0.919003 | 0.664224 | msmarco-distilroberta-base-v2 | 2 | 128 |
| 0.952544 | 0.893769 | 0.662694 | msmarco-distilroberta-base-v2 | 2 | 256 |
| 0.912355 | NaN | 0.661135 | all-MiniLM-L6-v2 | 2 | 128 |
| 0.94463 | 0.928349 | 0.659311 | all-MiniLM-L6-v2 | 3 | 128 |
| 0.933489 | 0.948598 | 0.65133 | all-MiniLM-L6-v2 | 3 | 64 |
| 0.941952 | 0.91472 | 0.645992 | all-mpnet-base-v2 | 3 | 256 |
| 0.948038 | NaN | 0.643175 | all-mpnet-base-v2 | 3 | 128 |
| 0.951702 | 0.925456 | 0.642837 | all-MiniLM-L6-v2 | 2 | 256 |
| 0.946651 | 0.88785 | 0.639072 | all-mpnet-base-v2 | 2 | 256 |
| 0.869485 | 0.895639 | 0.633806 | all-MiniLM-L6-v2 | 2 | 64 |
| 0.964182 | 0.943925 | 0.62854 | msmarco-distilroberta-base-v2 | 3 | 256 |
| 0.949844 | 0.866822 | 0.613355 | msmarco-distilroberta-base-v2 | 1 | 256 |
| 0.901218 | 0.890654 | 0.611468 | all-mpnet-base-v2 | 3 | 64 |
| 0.916422 | 0.892523 | 0.609728 | all-mpnet-base-v2 | 2 | 128 |
| 0.88004 | 0.929907 | 0.600428 | msmarco-distilroberta-base-v2 | 2 | 64 |
| 0.885314 | 0.869159 | 0.587424 | msmarco-distilroberta-base-v2 | 1 | 128 |
| 0.82648 | 0.866044 | 0.584507 | all-mpnet-base-v2 | 2 | 64 |
| 0.912991 | 0.827103 | 0.574832 | all-MiniLM-L6-v2 | 1 | 256 |
| 0.867887 | 0.834112 | 0.560079 | all-mpnet-base-v2 | 1 | 256 |
| 0.843447 | 0.831776 | 0.555873 | all-MiniLM-L6-v2 | 1 | 128 |
| 0.897715 | 0.845794 | 0.538579 | all-mpnet-base-v2 | 1 | 128 |
| 0.909813 | 0.738318 | 0.530884 | msmarco-distilroberta-base-v2 | 1 | 64 |
| 0.834891 | 0.738318 | 0.524882 | all-MiniLM-L6-v2 | 1 | 64 |
| 0.791589 | 0.67757 | 0.480863 | all-mpnet-base-v2 | 1 | 64 |
关注语义答案相似度
- 使用
msmarco-distilroberta-base-v2嵌入模型,top_k=3和chunk_size=128可获得最佳结果。 - 在此评估中,检索具有
top_k=3的文档通常会比top_k=1或top_k=2产生更高的语义相似度分数 - 此外,似乎无论
top_k和chunk_size如何,最佳语义相似度分数均来自使用嵌入模型all-MiniLM-L6-v2和msmarco-distilroberta-base-v2。
让我们在语义答案相似度方面检查每个嵌入模型的得分如何相互比较。为此,我们将结果按嵌入列分组,并使用箱形图绘制分数。
from matplotlib import pyplot as plt
fig, ax = plt.subplots(figsize=(10, 6))
df.boxplot(column='sas', by='embeddings', ax=ax)
plt.xlabel("Embeddings Model")
plt.ylabel("Semantic Answer Similarity Values")
plt.title("Boxplots of Semantic Answer Similarity Values Aggregated by Embeddings")
plt.show()
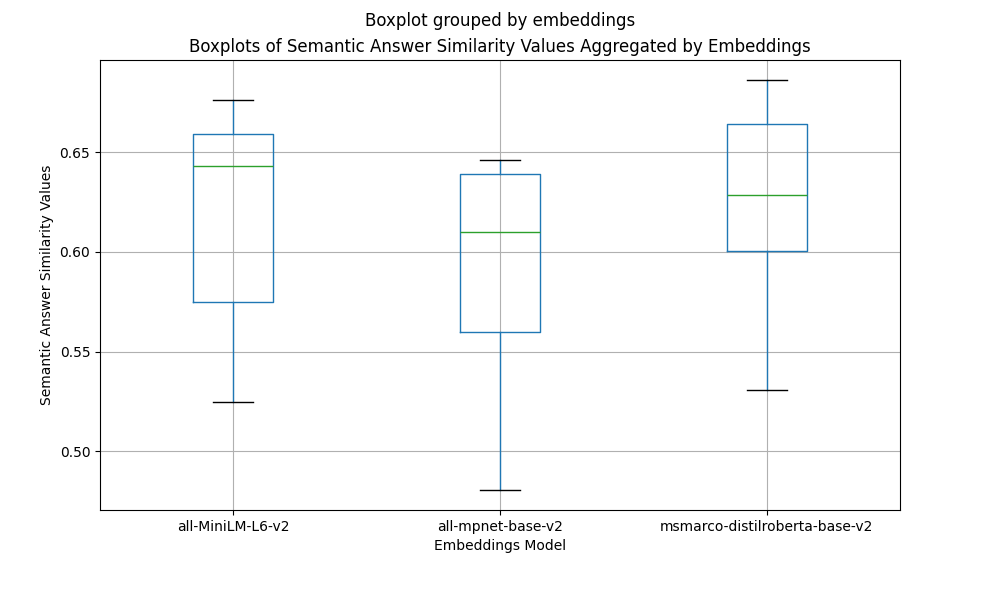
上面的箱形图显示
all-MiniLM-L6-v2和msmarco-distilroberta-base-v2嵌入模型优于all-mpnet-base-v2。msmarco-distilroberta-base-v2分数的方差较小,这表明与其它模型相比,该模型对于top_k和chunk_size参数变化更稳定。- 所有三个嵌入模型都有一个异常值,对应于得分最高和得分最低的参数组合。
- 不出所料,所有最低分数的异常值都对应于
top_k=1和chunk_size=64。 - 最高分数的异常值对应于
top_k=3和chunk_size为128或256。
由于我们有地面真实答案,我们专注于语义相似度答案,但我们也来看看忠实度和上下文相关性分数。为此,我们需要加载详细分数。
detailed_best_sas_df = pd.read_csv("results/aragog_results/detailed_all-MiniLM-L6-v2__top_k:3__chunk_size:128.csv")
def inspect(idx):
print("Question: ")
print(detailed_best_sas_df.loc[idx]['questions'])
print("\nTrue Answer:")
print(detailed_best_sas_df.loc[idx]['true_answers'])
print()
print("Generated Answer:")
print(detailed_best_sas_df.loc[idx]['predicted_answers'])
print()
print(f"Context Relevance : {detailed_best_sas_df.loc[idx]['context_relevance']}")
print(f"Faithfulness : {detailed_best_sas_df.loc[idx]['faithfulness']}")
print(f"Semantic Similarity: {detailed_best_sas_df.loc[idx]['sas']}")
让我们看看问题 6
inspect(6)
Question:
How does BERT's performance on the GLUE benchmark compare to previous state-of-the-art models?
True Answer:
BERT achieved new state-of-the-art on the GLUE benchmark (80.5%), surpassing the previous best models.
Generated Answer:
BERT's performance on the GLUE benchmark significantly outperforms previous state-of-the-art models, achieving 4.5% and 7.0% respective average accuracy improvement over the prior state of the art.
Context Relevance : 1.0
Faithfulness : 1.0
Semantic Similarity: 0.9051246047019958
Contexts:
recent work in this area.
Since its release, GLUE has been used as a testbed and showcase by the developers of several
influential models, including GPT (Radford et al., 2018) and BERT (Devlin et al., 2019). As shown
in Figure 1, progress on GLUE since its release has been striking. On GLUE, GPT and BERT
achieved scores of 72.8 and 80.2 respectively, relative to 66.5 for an ELMo-based model (Peters
et al., 2018) and 63.7 for the strongest baseline with no multitask learning or pretraining above the
word level. Recent models (Liu et al., 2019d; Yang et al., 2019) have clearly surpassed estimates of
non-expert human performance on GLUE (Nangia and Bowman, 2019). The success of these models
on GLUE has been driven by ever-increasing model capacity, compute power, and data quantity, as
well as innovations in
---------
56.0 75.1
BERT BASE 84.6/83.4 71.2 90.5 93.5 52.1 85.8 88.9 66.4 79.6
BERT LARGE 86.7/85.9 72.1 92.7 94.9 60.5 86.5 89.3 70.1 82.1
Table 1: GLUE Test results, scored by the evaluation server ( https://gluebenchmark.com/leaderboard ).
The number below each task denotes the number of training examples. The “Average” column is slightly different
than the official GLUE score, since we exclude the problematic WNLI set.8BERT and OpenAI GPT are single-
model, single task. F1 scores are reported for QQP and MRPC, Spearman correlations are reported for STS-B, and
accuracy scores are reported for the other tasks. We exclude entries that use BERT as one of their components.
We use a batch size of 32 and fine-tune for 3
epochs over the data for all GLUE tasks. For each
task, we selected the best fine-tuning learning rate
(among 5e-5,
---------
4e-5, 3e-5, and 2e-5) on the Dev set.
Additionally, for BERT LARGE we found that fine-
tuning was sometimes unstable on small datasets,
so we ran several random restarts and selected the
best model on the Dev set. With random restarts,
we use the same pre-trained checkpoint but per-
form different fine-tuning data shuffling and clas-
sifier layer initialization.9
Results are presented in Table 1. Both
BERT BASE and BERT LARGE outperform all sys-
tems on all tasks by a substantial margin, obtaining
4.5% and 7.0% respective average accuracy im-
provement over the prior state of the art. Note that
BERT BASE and OpenAI GPT are nearly identical
in terms of model architecture apart from the at-
tention masking. For the largest and most widely
reported GLUE task, MNLI, BERT obtains a 4.6%
absolute accuracy improvement. On the official
GLUE leaderboard10, BERT LARGE obtains a score
of
---------
在此示例中,上下文相关性和忠实度分数均为 1.0。这表明上下文与问题相关,我们的 RAG LLM 使用该上下文生成了与正确(地面真实)答案语义相似的答案。
让我们来看另一个例子
inspect(44)
Question:
How should future language model benchmarks be structured to ensure a holistic assessment of models' capabilities and knowledge breadth?
True Answer:
Future benchmarks should integrate a broader spectrum of subjects and cognitive skills, emphasizing the inclusion of tasks that test models' ethical reasoning, understanding of human values, and ability to perform complex problem-solving, beyond the mere scale of data and parameters.
Generated Answer:
Future language model benchmarks should be structured to measure knowledge acquired during pretraining by evaluating models exclusively in zero-shot and few-shot settings across a diverse set of subjects that humans learn. The benchmark should cover a wide range of subjects across STEM, humanities, social sciences, and more, ranging in difficulty from elementary to advanced professional levels. It should test both world knowledge and problem-solving ability, ensuring a holistic assessment of models' capabilities and knowledge breadth.
Context Relevance : 0.6
Faithfulness : 1.0
Semantic Similarity: 0.6483339071273804
Contexts:
learning model
usage should be developed for guiding users to learn ‘Dos’
and Dont’ in AI. Detailed policies could also be proposed
to list all user’s responsibilities before the model access.
C. Language Models Beyond ChatGPT
The examination of ethical implications associated with
language models necessitates a comprehensive examina-
tion of the broader challenges that arise within the domainof language models, in light of recent advancements in
the field of artificial intelligence. The last decade has seen
a rapid evolution of AI techniques, characterized by an
exponential increase in the size and complexity of AI
models, and a concomitant scale-up of model parameters.
The scaling laws that govern the development of language
models,asdocumentedinrecentliterature[84,85],suggest
thatwecanexpecttoencounterevenmoreexpansivemod-
els that incorporate multiple modalities in the near future.
Efforts to integrate multiple modalities into a single model
are driven by the ultimate goal of realizing the concept of
foundation models [86].
---------
language models are
at learning and applying knowledge from many domains.
To bridge the gap between the wide-ranging knowledge that models see during pretraining and the
existing measures of success, we introduce a new benchmark for assessing models across a diverse
set of subjects that humans learn. We design the benchmark to measure knowledge acquired during
pretraining by evaluating models exclusively in zero-shot and few-shot settings. This makes the
benchmark more challenging and more similar to how we evaluate humans. The benchmark covers
57subjects across STEM, the humanities, the social sciences, and more. It ranges in difficulty from
an elementary level to an advanced professional level, and it tests both world knowledge and problem
solving ability. Subjects range from traditional areas, such as mathematics and history, to more
1arXiv:2009.03300v3 [cs.CY] 12 Jan 2021Published as a conference paper at
---------
a
lack of access to the benefits of these models for people
who speak different languages and can lead to biased or
unfairpredictionsaboutthosegroups[14,15].Toovercome
this, it is crucial to ensure that the training data contains
a substantial proportion of diverse, high-quality corpora
from various languages and cultures.
b) Robustness: Another major ethical consideration
in the design and implementation of language models is
their robustness. Robustness refers to a model’s ability
to maintain its performance when given input that is
semantically or syntactically different from the input it
was trained on.
Semantic Perturbation: Semantic perturbation is a type
of input that can cause a language model to fail [40, 41].
This input has different syntax but is semantically similar
to the input used for training the model. To address this,
it is crucial to ensure that the training data is diverse and
representative of the population it will
---------
对于这个问题,内容似乎不完全相关(上下文相关性 = 0.6),并且只使用了第二个上下文来生成答案。
运行您自己的实验
如果您想自己运行此实验,请按照 evaluation_aragog.py 的 Python 代码在 haystack-evaluation 存储库中进行操作。
首先克隆存储库
git clone https://github.com/deepset-ai/haystack-evaluation
cd haystack-evaluation
cd evaluations
接下来,运行 Python 脚本
usage: evaluation_aragog.py [-h] --output_dir OUTPUT_DIR [--sample SAMPLE]
您可以指定输出目录来保存结果和样本大小,即:使用多少个问题进行评估。
不要忘记在环境变量
OPENAI_API_KEY中定义您的 Open AI API 密钥。
OPENAI_API_KEY=<your_key> python evaluation_aragog.py --output-dir experiment_a --sample 10
执行时间和成本
注意:所有报告的数字均在配备 36GB RAM 的 Mac Book Pro Apple M3 Pro 上运行,使用 Haystack 2.2.1 和 Python 3.9。
索引
索引流水线需要考虑以下参数组合
- 3 种不同的
embedding_model值 - 3 种不同的
chunk_size值
因此,索引总共运行 9 次。
RAG 管道
RAG 流水线需要运行 27 次,因为以下参数会影响检索过程
- 3 种不同的
embedding_model值 - 3 种不同的
top_k值 - 3 种不同的
chunk_size值
这需要针对 107 个问题中的每一个运行,因此,RAG 流水线总共将运行2,889 次(3 x 3 x 3 x 107),并产生2889 次 OpenAI API 调用。
评估流水线
评估流水线也运行 27 次,因为需要为 107 个问题中的每一个评估所有参数组合。但是,请注意,评估流水线包含两个依赖于 OpenAI API 的 LLM 的评估器,因此该流水线将运行2,889 次。但是,由于 Faithfulness 和 ContextRelevance 评估器,它将产生5,778 次(2 x 2.889)OpenAI API 调用。
您可以在 基准测试时间电子表格 中查看每个参数组合的详细运行时间。
定价
有关详细的定价信息,请访问 OpenAI 定价 💸
经验教训
在本文中,我们展示了如何使用 Haystack 的 评估器 来查找可获得最佳 RAG 流水线性能的最佳参数组合,而不是仅使用默认参数。
特别是对于 ARAGOG 数据集,使用 msmarco-distilroberta-base-v2 嵌入模型而不是默认模型(sentence-transformers/all-mpnet-base-v2),以及 top_k=3 和 chunk_size=128,可以获得最佳性能。
有几点重要的学习经验
- 通过外部 API 使用 LLM 时,请务必考虑潜在的网络错误或其他问题。在您的实验期间,请确保运行 RAG 流水线的查询或评估结果不会因错误而崩溃,例如,通过将调用包装在
try/except代码块中。 - 在开始实验之前,请估算成本和时间。如果您计划通过 API 使用外部 LLM,请估算运行 RAG 流水线查询所需的 API 调用次数,并评估您是否使用基于 LLM 的评估器。这将帮助您了解实验所需的总成本和时间。
- 根据数据集大小和运行时间,Python 笔记本可能不是运行实验的最佳方法;Python 脚本可能是一种更可靠的解决方案。
- 注意哪些参数会影响哪些组件。例如,对于索引,只有
embedding_model和chunk_size是重要的 - 这可以减少您需要进行的实验数量。
通过访问 GitHub 上的 haystack-evaluation 存储库,探索针对不同用例和数据集的各种评估示例。
