
高级 RAG:查询分解与推理
分解伪装成单一问题的多个问题,并让 LLM 推理最终答案。
2024 年 9 月 30 日这是 **高级用例** 系列的第一部分
1️⃣ 从查询中提取元数据以改进检索
2️⃣ 查询扩展
3️⃣ 查询分解
4️⃣ 自动化元数据丰富
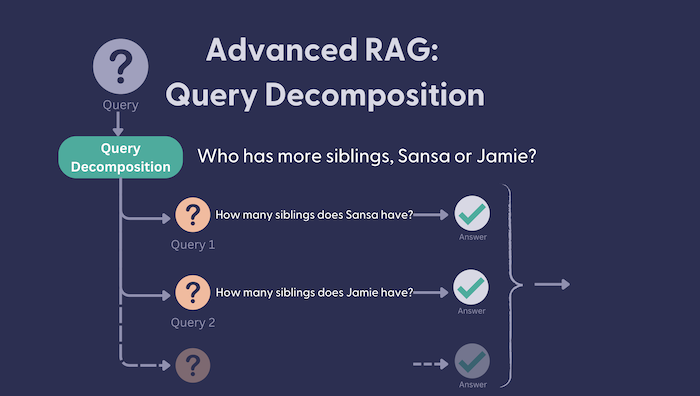
有时一个问题实际上是多个问题的伪装。例如:“微软还是谷歌去年赚的钱多?”。要得到这个看似简单的问题的正确答案,我们实际上需要将其分解:“谷歌去年赚了多少钱?”和“微软去年赚了多少钱?”。只有当我们知道这两个问题的答案时,我们才能推理出最终答案。
这就是查询分解的用武之地。这是一种检索增强生成(RAG)AI 应用的技术,其方法很简单:
- 将原始问题分解成可以独立回答的更小问题。在此之后,我们将这些问题称为“子问题”。
- 根据每个子问题的答案,推理出原始问题的最终答案。
虽然对于许多查询/数据集组合来说,这可能不是必需的,但对于某些组合来说,它可能非常有用。归根结底,通常一个查询会产生一个检索步骤。如果在这个单一的检索步骤中,我们无法让检索器返回微软去年赚的钱和谷歌赚的钱,那么系统将难以产生准确的最终响应。
此方法可确保我们
- 为每个子问题检索相关上下文。
- 根据为每个子问题检索到的上下文,推理出每个答案的最终答案。
在本文中,我将介绍实现此目的的一些关键步骤。您可以在我们 cookbook 中找到链接的配方中的完整工作示例和代码。在这里,我将只展示代码中最相关的部分。
🚀 我将在此文章中悄悄加入一些额外内容。我看到了使用 OpenAI 的结构化输出功能(目前处于测试阶段)来创建此示例的机会。为此,我扩展了 Haystack 中的 OpenAIGenerator,使其能够与 Pydantic 模式一起工作。更多内容将在下一步介绍。
让我们尝试构建一个充分利用查询分解和推理的完整管道。我们将使用一个关于《权力的游戏》(Haystack 的经典案例)的数据集,您可以在 Hugging Face Datasets 的 Tuana/game-of-thrones 上找到预处理和分块后的数据。
定义我们的问题结构
我们的第一步是创建一个结构,我们可以在其中包含子问题及其各自的答案。这将由我们的 OpenAIGenerator 用于生成结构化输出。
from pydantic import BaseModel
class Question(BaseModel):
question: str
answer: Optional[str] = None
class Questions(BaseModel):
questions: list[Question]
结构很简单,我们有由 Question 列表组成的 Questions。每个 Question 都有 question 字符串以及该问题的可选 answer。
定义查询分解的提示
接下来,我们需要让 LLM 分解一个问题并生成多个问题。在这里,我们将开始使用我们的 Questions 模式。
splitter_prompt = """
You are a helpful assistant that prepares queries that will be sent to a search component.
Sometimes, these queries are very complex.
Your job is to simplify complex queries into multiple queries that can be answered
in isolation to eachother.
If the query is simple, then keep it as it is.
Examples
1. Query: Did Microsoft or Google make more money last year?
Decomposed Questions: [Question(question='How much profit did Microsoft make last year?', answer=None), Question(question='How much profit did Google make last year?', answer=None)]
2. Query: What is the capital of France?
Decomposed Questions: [Question(question='What is the capital of France?', answer=None)]
3. Query: {{question}}
Decomposed Questions:
"""
builder = PromptBuilder(splitter_prompt)
llm = OpenAIGenerator(model="gpt-4o-mini", generation_kwargs={"response_format": Questions})
回答每个子问题
首先,让我们构建一个使用 splitter_prompt 分解我们问题的管道
query_decomposition_pipeline = Pipeline()
query_decomposition_pipeline.add_component("prompt", PromptBuilder(splitter_prompt))
query_decomposition_pipeline.add_component("llm", OpenAIGenerator(model="gpt-4o-mini", generation_kwargs={"response_format": Questions}))
query_decomposition_pipeline.connect("prompt", "llm")
question = "Who has more siblings, Jamie or Sansa?"
result = query_decomposition_pipeline.run({"prompt":{"question": question}})
print(result["llm"]["structured_reply"])
这将产生以下 Questions(List[Question])
questions=[Question(question='How many siblings does Jamie have?', answer=None),
Question(question='How many siblings does Sansa have?', answer=None)]
现在,我们必须填写 answer 字段。为此,我们需要一个单独的提示和两个自定义组件
CohereMultiTextEmbedder,它可以接受多个问题,而不是像CohereTextEmbedder那样只接受一个问题。MultiQueryInMemoryEmbeddingRetriever,它可以接受多个问题及其嵌入,返回question_context_pairs。每对包含question以及与该问题相关的documents。
接下来,我们需要构建一个提示,指示模型回答每个子问题
multi_query_template = """
You are a helpful assistant that can answer complex queries.
Here is the original question you were asked: {{question}}
And you have split the task into the following questions:
{% for pair in question_context_pairs %}
{{pair.question}}
{% endfor %}
Here are the question and context pairs for each question.
For each question, generate the question answer pair as a structured output
{% for pair in question_context_pairs %}
Question: {{pair.question}}
Context: {{pair.documents}}
{% endfor %}
Answers:
"""
multi_query_prompt = PromptBuilder(multi_query_template)
让我们构建一个能够回答每个单独子问题的管道。我们将称之为 query_decomposition_pipeline
query_decomposition_pipeline = Pipeline()
query_decomposition_pipeline.add_component("prompt", PromptBuilder(splitter_prompt))
query_decomposition_pipeline.add_component("llm", OpenAIGenerator(model="gpt-4o-mini", generation_kwargs={"response_format": Questions}))
query_decomposition_pipeline.add_component("embedder", CohereMultiTextEmbedder(model="embed-multilingual-v3.0"))
query_decomposition_pipeline.add_component("multi_query_retriever", MultiQueryInMemoryEmbeddingRetriever(InMemoryEmbeddingRetriever(document_store=document_store)))
query_decomposition_pipeline.add_component("multi_query_prompt", PromptBuilder(multi_query_template))
query_decomposition_pipeline.add_component("query_resolver_llm", OpenAIGenerator(model="gpt-4o-mini", generation_kwargs={"response_format": Questions}))
query_decomposition_pipeline.connect("prompt", "llm")
query_decomposition_pipeline.connect("llm.structured_reply", "embedder.questions")
query_decomposition_pipeline.connect("embedder.embeddings", "multi_query_retriever.query_embeddings")
query_decomposition_pipeline.connect("llm.structured_reply", "multi_query_retriever.queries")
query_decomposition_pipeline.connect("llm.structured_reply", "embedder.questions")
query_decomposition_pipeline.connect("multi_query_retriever.question_context_pairs", "multi_query_prompt.question_context_pairs")
query_decomposition_pipeline.connect("multi_query_prompt", "query_resolver_llm")
使用原始问题“詹米或珊莎的兄弟姐妹更多?”运行此管道,会得到以下结构化输出
question = "Who has more siblings, Jamie or Sansa?"
result = query_decomposition_pipeline.run({"prompt":{"question": question},
"multi_query_prompt": {"question": question}})
print(result["query_resolver_llm"]["structured_reply"])
questions=[Question(question='How many siblings does Jamie have?', answer='2 (Cersei Lannister, Tyrion Lannister)'),
Question(question='How many siblings does Sansa have?', answer='5 (Robb Stark, Arya Stark, Bran Stark, Rickon Stark, Jon Snow)')]
推理最终答案

我们必须采取的最后一步是推理出原始问题的最终答案。同样,我们创建一个提示来指导 LLM 完成此任务。考虑到我们有包含每个子 question 和 answer 的 questions 输出,我们将这些作为输入提供给此最终提示。
reasoning_template = """
You are a helpful assistant that can answer complex queries.
Here is the original question you were asked: {{question}}
You have split this question up into simpler questions that can be answered in
isolation.
Here are the questions and answers that you've generated
{% for pair in question_answer_pair %}
{{pair}}
{% endfor %}
Reason about the final answer to the original query based on these questions and
aswers
Final Answer:
"""
resoning_prompt = PromptBuilder(reasoning_template)
为了能够使用问题-答案对来增强此提示,我们将不得不扩展我们之前的管道,并将上一个 LLM 的 structured_reply 连接到此提示的 question_answer_pair 输入。
query_decomposition_pipeline.add_component("reasoning_prompt", PromptBuilder(reasoning_template))
query_decomposition_pipeline.add_component("reasoning_llm", OpenAIGenerator(model="gpt-4o-mini"))
query_decomposition_pipeline.connect("query_resolver_llm.structured_reply", "reasoning_prompt.question_answer_pair")
query_decomposition_pipeline.connect("reasoning_prompt", "reasoning_llm")
现在,让我们运行这个最终管道,看看我们得到什么结果
question = "Who has more siblings, Jamie or Sansa?"
result = query_decomposition_pipeline.run({"prompt":{"question": question},
"multi_query_prompt": {"question": question},
"reasoning_prompt": {"question": question}},
include_outputs_from=["query_resolver_llm"])
print("The original query was split and resolved:\n")
for pair in result["query_resolver_llm"]["structured_reply"].questions:
print(pair)
print("\nSo the original query is answered as follows:\n")
print(result["reasoning_llm"]["replies"][0])
🥁 请响起鼓掌声
The original query was split and resolved:
question='How many siblings does Jaime have?' answer='Jaime has one sister (Cersei) and one younger brother (Tyrion), making a total of 2 siblings.'
question='How many siblings does Sansa have?' answer='Sansa has five siblings: one older brother (Robb), one younger sister (Arya), and two younger brothers (Bran and Rickon), as well as one older illegitimate half-brother (Jon Snow).'
So the original query is answered as follows:
To determine who has more siblings between Jaime and Sansa, we need to compare the number of siblings each has based on the provided answers.
From the answers:
- Jaime has 2 siblings (Cersei and Tyrion).
- Sansa has 5 siblings (Robb, Arya, Bran, Rickon, and Jon Snow).
Since Sansa has 5 siblings and Jaime has 2 siblings, we can conclude that Sansa has more siblings than Jaime.
Final Answer: Sansa has more siblings than Jaime.
总结
在正确的指导下,LLM 能够很好地分解任务。查询分解是我们可以确保为伪装成单一问题的多个问题执行此操作的好方法。
在本文中,您学会了如何实现这项技术,并带有一点小变化 🙂 让我们知道您对在这些用例中使用结构化输出的看法。并查看 Haystack experimental repo,了解我们正在开发哪些新功能。
