

什么是大型语言模型 (LLM)?
LLM 简介以及如何使用 Haystack 在您自己的应用程序中利用它们
2023 年 6 月 23 日人工智能已成定局。虽然自动驾驶甚至图像生成等应用目前只触及了少数人的生活,但以高质量聊天机器人形式出现的生成式人工智能却席卷了全球。ChatGPT 等工具能够提供信息丰富、富有创意,有时甚至令人难以置信的流畅回复,这得益于一种名为大型语言模型 (LLM) 的新技术。
在本文中,我们将讨论 LLM 是什么以及它们是如何产生的,存在哪些类型的 LLM,以及它们是否仅仅是由于大小才与其他语言模型区分开来。最后,我们将展示如何使用 Haystack(我们用于自然语言处理的开源框架)来利用 LLM。
什么是大型语言模型?
与大多数开创性技术一样,LLM 的出现并非一蹴而就。相反,它们是过去几年中自然语言处理领域长期发展趋势的一部分。自 BERT 推出以来,最先进的语言模型一直遵循相同的架构范例,从而不断加深对自然(即人类)语言的细微差别和细微之处的理解。
开发人员将这种新发现的语言处理能力提升到了一个新的水平,构建了规模越来越大的语言模型,这些模型在训练期间需要惊人的计算能力:LLM 就此诞生。除了它们的规模(以可训练参数的数量计算)之外,这些模型在训练时还必须摄入海量数据。

所以,从技术上讲,大型语言模型就是一个大型语言模型。但在实践中,“LLM”一词已具有更具体的含义:它通常指那些能够根据用户指令生成连贯、类人输出的大型模型。因此,在本文中,我们将重点关注满足此定义的模型,而忽略其他 LLM。
LLM 是如何创建的?
与大多数现代机器学习模型一样,LLM 是通过将一个复杂的神经网络架构与代表模型需要学习的领域的数据相结合来创建的。因此,计算机视觉模型摄入图像数据,而语言模型在训练期间需要看到文本数据。请参阅我们关于 语言模型的入门讨论,了解更多信息。
预训练 LLM
在第一个训练阶段,LLM 通过文本补全来学习数据的表示。在看到一连串单词后,其训练目标是生成最有可能的下一个单词。通过这种技术,它学会了模仿我们自身的语言直觉。然而——“大型”部分在此真正发挥了作用——虽然小型模型能够形成语法正确、结构良好的响应,但 LLM 走得更远。这些模型拥有如此多的参数,以至于它们可以轻松地学习数据中包含的世界知识的表示。
让我们通过一些例子来更清楚地说明这一点。以下是小型语言模型与 LLM 所学到的直觉的对比:
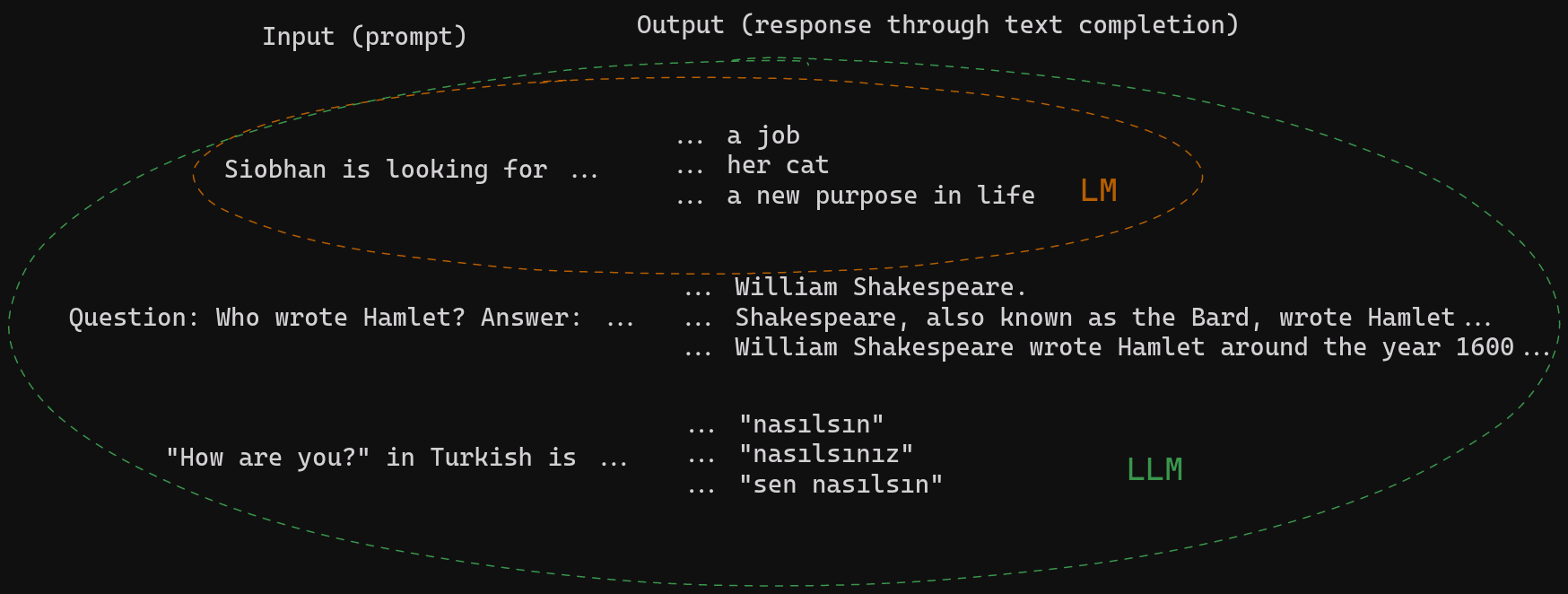
当指令正确时,大型模型可以以生成连贯且信息丰富的答案、翻译、摘要等方式来补全文本。这就是为什么提示或提示工程在处理这些模型时如此重要。请参阅我们关于 LLM 提示的文章,了解更多信息。
显然,LLM 不仅知道语言如何运作。它还知道世界如何运作——至少是其在训练数据中有所体现的部分。这些训练数据由从互联网(例如 Common Crawl 语料库)和其他来源收集的海量文本组成。
到目前为止,我们只讨论了训练语言模型的第一步——无论是小型、中型还是大型。然而,对于 ChatGPT 和其他类似的指令遵循 LLM,开发人员添加了额外的复杂训练步骤,才达到了这些模型令人印象深刻的对话能力。
微调 LLM
总而言之,预训练的 LLM 可以使用语言直觉以及世界知识来补全文本提示。然而,这种文本补全仍然可以采取多种形式。想象一下输入提示“向 6 岁的孩子解释登月”。对于预训练模型来说,以下两个输出都是同样好的补全:
-
“很多年前,一群人首次登陆了月球……”
-
“向 5 岁的孩子解释重力。”
(示例 改编自 OpenAI)
对于我们知道对话是什么样的人来说,第二个答案听起来就像模型在戏弄我们。因此,在微调阶段,研究人员需要教会 LLM 如何进行适当的问答交流。为此,他们创建了一个包含人类生成答案的数据集,以响应一组提示,并在该数据上微调模型。此步骤称为“监督微调”(SFT)。
LLM 现在已经掌握了对人类语言交互的基本理解。但正如我们都知道的那样,这种交互并非总是恰当的,尤其是在您试图模仿聊天机器人的中立代理时。由于模型在训练过程中摄入了大量的互联网内容——包括聊天论坛和其他未经审查的内容——它仍然容易生成冒犯性、不合格甚至有害的答案。
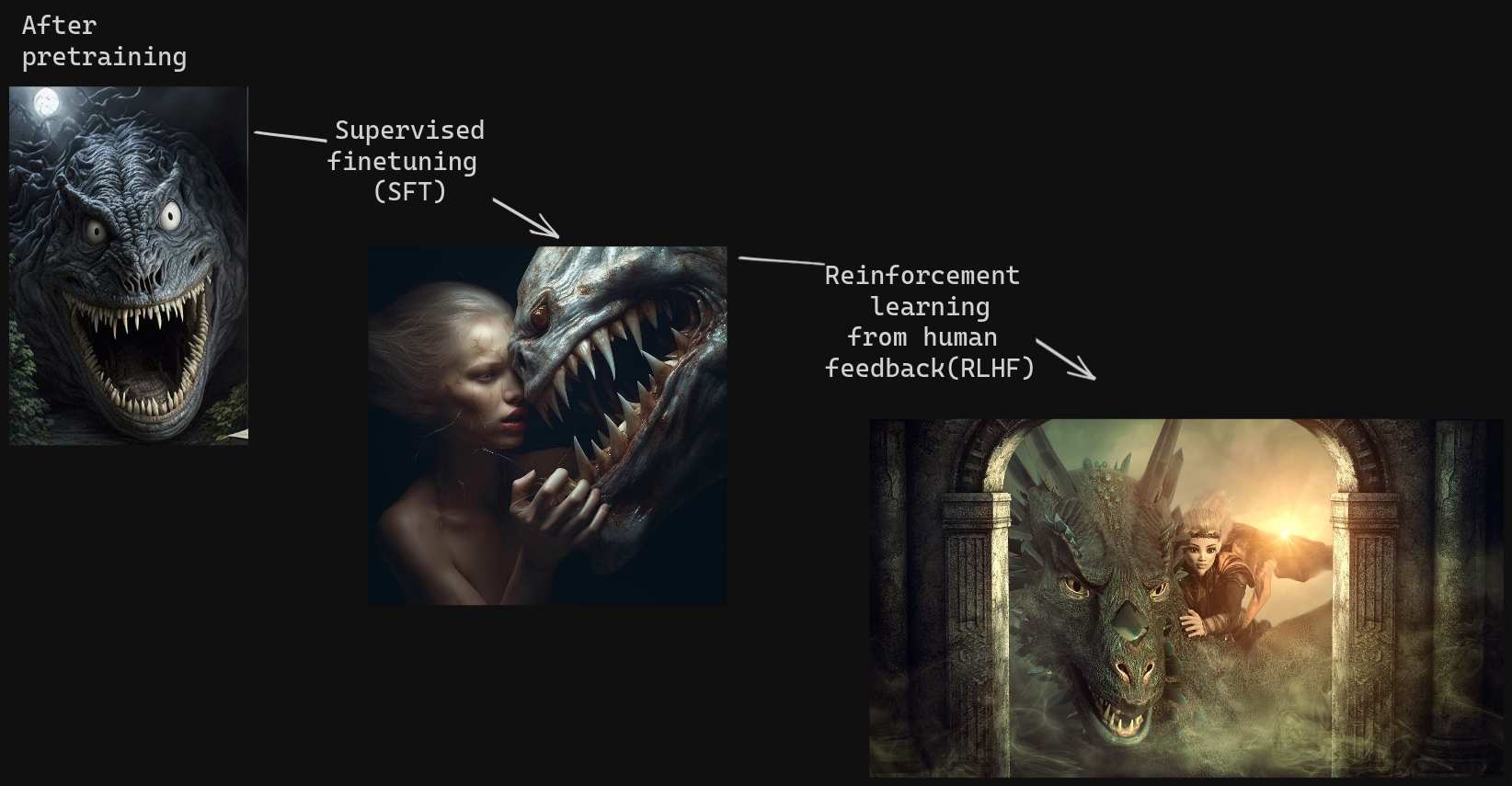
为了创建一个真正有用的聊天机器人,ChatGPT 的开发人员因此引入了第二步训练,该训练使用“强化学习”——一种经典的机器学习方法——来引导模型获得更优的答案。基于人类对同一提示的不同答案的排名,他们训练了一个辅助模型来区分好与坏的输出。
因此,在达到我们所知的 ChatGPT 的最后一步中,这个辅助模型被用来教会 LLM 更好地满足用户的期望,并提供信息丰富、中立且政治正确的答案。这个最后的微调步骤称为“人类反馈强化学习”(RLHF)。
LLM 的世界:大小与速度
虽然 ChatGPT 的发布标志着公众了解大型语言模型及其能力的时间点,但 LLM 在此之前就已经在开发中了——而且不仅仅是由 OpenAI。谷歌的 LaMDA(1370 亿参数)、英伟达和微软的 MT NLG(5300 亿参数)以及中国的 BAAI 的 WuDao 2.0 模型(1.75 万亿参数)都遵循“越大越好”的原则。
所有这些都是专有模型:其中一些可以通过 API 使用(并收费),而另一些仍然完全被严格控制。这与 NLP 中的一个广泛标准背道而驰,即共享语言模型的训练权重以实现公平的通用使用。(例如,谷歌的 BERT 和 Meta 的 RoBERTa 从一开始就开源了,可以开箱即用或由任何人进行微调。)
另一方面,闭源模型比其他神经网络更像一个黑箱:没有人确切知道这些模型使用了哪些数据,也不知道它们的输出是如何过滤的。就 GPT-4 而言,甚至不清楚模型究竟有多大。更重要的是,这些模型是在大量公开的互联网数据上训练的,它们只能通过数据共享实践才得以实现。
但是,NLP 社区以闪电般的速度回应了公司的专有野心,训练并开源了它们自己的大型语言模型。您可以在 Hugging Face 上查看 Open LLM Leaderboard,或者查看 Chatbot Arena,该竞技场在实验期间隐藏了预测模型的身份,以了解该领域性能最佳的模型。
开源模型的改进速度如此之快,是因为它们可以互相借鉴成功经验。像 Falcon、Vicuna 和 Alpaca 这样的 LLM 在公开可用的数据集上进行了透明的训练。尽管它们的规模远小于闭源模型,但这些模型的输出质量也开始迎头赶上。
LLM + Haystack = 🚀
自然,LLM 对 NLP 世界产生了巨大影响。提示工程和幻觉等全新研究领域应运而生,引发了激烈的辩论和加速的开发速度,每天都带来创新。
Haystack,我们用于 NLP 的 OSS Python 框架,允许您通过将代理、提示节点和您选择的大型语言模型(无论是闭源还是开源)集成到面向用户的应用程序中,来构建自己的 LLM 驱动的系统。
得益于 Haystack 的模块化结构,只需更改一行代码即可在模型之间进行切换。在不同平台上尝试各种模型,看看哪些最适合您的用例。一旦下一个强大的 OSS LLM 出现,您就可以立即将其集成到您的 Haystack 管道中并开始使用。有了 Haystack,您就为未来做好了准备 🚀
您喜欢学习有关 NLP 的所有内容吗?我们在 Discord 上 托管了一个服务器,我们在这里回答问题并定期组织关于自然语言处理领域有趣话题的讨论。一定要过来看看——如果您对 LLM 的最新研究感兴趣,请在那里查看 nlp-discussions 频道!
我们希望很快能欢迎您加入我们不断壮大的 NLP 爱好者社区!🙂
