

BERT 模型终极指南
BERT 语言模型极大地提高了语言模型的标准。本文将解释 BERT 的历史及其衍生的语言模型。
2023 年 1 月 16 日任何研究过自然语言处理(NLP)的人都能告诉你,最先进的技术发展速度非常快。像 Google、Facebook 或 OpenAI 这样的巨头拥有庞大的专家团队,致力于提出新的解决方案,使计算机更接近对人类语言的理解。这导致模型架构和其他方法迅速过时,六个月前被认为是尖端技术的东西,今天可能看起来已经过时了。然而,有些模型的影响如此之大,以至于即使被后继模型所取代,它们仍然成为基础知识。
BERT(**B**idirectional **E**ncoder **R**epresentations from **T**ransformers 的缩写,这个拗口的名字几乎可以肯定是为了便于记忆而起的)的模型架构就是这种情况。尽管第一个 BERT 模型——诞生于 2018 年底——如今很少以其原始形式使用,但该模型架构在任务、语言甚至大小方面的适应性意味着直接的 BERT 后继模型仍在各个领域蓬勃发展。
在快速变化的语言模型领域,跟上步伐并为您的项目找到最佳选择可能很困难。本文旨在更新您对 BERT 的了解,概述各种已超越 BERT 基线的模型,并帮助您找到适合您的 BERT 类模型。
什么是 BERT?
Google 研究人员将 BERT 设计为一个通用语言模型,并采用了 Transformer 架构,该架构在一年前就已经对 NLP 领域产生了巨大影响。除了通过其对语义的深度理解来改进 Google 的搜索结果之外,BERT 的主要功能是作为特定“下游”任务(如问答或情感分析)的基础。这是因为其以近乎人类的水平处理书面语言的能力极大地帮助了 BERT 语言模型解决其他基于语言的任务。
BERT 在 2018 年对 NLP 领域的影响是巨大的。在原始论文中,基于 BERT 的预训练架构的模型被证明在许多不同任务上优于竞争对手后,行业观察家预测这种新的模型范式将是一个游戏规则的改变者,一篇博文甚至称 BERT 是“统治一切的模型”。
是什么让 BERT 与众不同?
要理解 BERT 的巨大成功,我们需要回顾一下语言建模的历史。在 Transformer 之前,语言模型基于循环神经网络(RNN)。RNN 相较于之前的“静态”文本嵌入(如 Doc2Vec)有一个主要优势,那就是它们能够捕获上下文中的词语含义。
然而,基于 RNN 的语言模型仍然存在严重缺陷。它们是严格顺序的,这意味着它们逐个令牌处理输入,而不是一次性处理。此外,RNN 在处理长序列时表现较弱,这促使研究人员在长短期记忆(LSTM)网络中实现补救措施,例如“记忆单元”,并对输入字符串进行两次处理:一次从左到右,一次从右到左。ELMo,通常被认为是 BERT 的直接前身,就是这种双向 LSTM 模型的一个例子。
相比之下,BERT 遵循 Transformer 架构,该架构在 2017 年的开创性论文中被引入。Transformer 基于自注意力机制,这是一种用于检测模式的新核心算法,使模型能够学习输入序列中各个令牌之间的上下文关系。因此,由自注意力驱动的 Transformer 生成的嵌入是高度动态的,并且可以轻松区分机器通常难以理解的语言,例如同形异义词或行话。此外,自注意力可以一次性处理输入序列,而不是顺序处理,从而加快了训练过程。
然而,在深度学习中,模型架构本身只是促成模型成功的一个因素——另一个因素是训练任务和它使用的数据。用于帮助 BERT 掌握语言的训练任务之一是“掩码语言模型”(MLM)。在训练过程中,训练输入中的单个令牌被掩盖,然后根据 BERT 预测这些令牌的能力来计算损失。这项任务如此有用的原因在于,它的训练数据可以以一种微不足道的方式生成:只需在源序列中隐藏一个随机令牌,并将同一个令牌作为预测目标。不需要昂贵的数据标注。
Transformer 的其他方向
BERT 的基本架构并不是使用 Transformer 的自注意力发展的唯一方法。众所周知的生成式预训练 Transformer(GPT)系列模型使用了与 BERT 相同的基线自注意力模块,但包含一个能够根据输入生成文本的解码器层。
请注意,尽管 GPT 获得了大量公众关注,但 BERT 缺乏“解码器”组件并不意味着 GPT 就更好。BERT 是一个更轻量级的模型,我们不将其用于需要语言生成任务。
BERT 系列
基本 BERT 模型的成功催生了大量流行的变体。更新、更强大的模型很快出现,BERT 在各种语言中都有了“兄弟姐妹”——有些甚至支持多语言——研究人员将 BERT 用作基础模型,通过微调来适应不同的任务和语言领域。最近,我们看到 Transformer 模型(如 BERT)正朝着越来越小、越来越高效的方向发展。
下面,我们将分解 BERT 系列中的一些广泛类别。您可以在Hugging Face 模型中心上探索所有不同的 BERT 模型,并使用搜索和筛选选项找到适合您需求的模型。
RoBERTa:过度勤奋的大姐姐
2019 年,Facebook 的工程师开发了一个功能明显更强大的 BERT 版本,使用了相同的模型架构。通过优化超参数并向模型输入更多数据,他们在保持资源大小和推理复杂性的同时,对基本 BERT 模型进行了大幅改进。另一个大步是转向动态 MLM,提供不同的句子掩码以提高学习的鲁棒性。
由此产生的架构被命名为 RoBERTa,并迅速被采纳为 BERT 的标准基线。如今 RoBERTa 仍然常被用作基线,例如在我们标准的英语问答模型中。
多语种 BERT
维基百科是许多语言训练集的宝贵资源,因此,如果存在足够大的维基百科,相对容易地用其他语言重新训练基本 BERT 模型。
在 deepset,我们很自豪能够为 NLP 社区贡献一些性能最好的德语 BERT 模型。请务必在我们的网站上查看各种英语和德语语言模型。德语 BERT 与大型国际模型家族并列,该家族包含AraBERT、CamemBERT和RuBERT等成员。
许多人还依赖多语言 BERT 模型来获取通用的语义上下文。BERT 最令人印象深刻的后继模型之一是由 Google 开发的多语言 BERT,该模型在 104 种不同语言上进行了训练,能够实现对新语言领域的“零样本”适应。这可能是通用语言建模的快速而简洁的解决方案,但当您需要特定的语义模型时,没有什么比自己训练它更好了(正如我们用德语 BERT所展示的)。
BERT 在现实世界中的应用:微调
通用语言模型之所以优秀,不是因为它们本身特别有用,而是因为它们能深入理解语言的语义,从而可以用于下游任务。这些任务的模型是通过微调产生的。
在微调中,预训练模型(如 BERT 或 RoBERTa)的核心架构会略作修改,以实现不同的目标输出。然后,它会在特定于下游任务的数据上进行训练:对于问答模型,这可能是一个包含问题和答案的数据集,如 SQuAD;对于摘要模型,则是长短篇文档对的数据集。这些专业化的优势在于,预训练基础模型只需要少得多的特定数据和少得多的训练时间,就可以在特定领域内表现出色。
微调是一种迁移学习方法,它使 BERT 模型能够完成各种任务,例如检测“有毒”语言、文本摘要、命名实体识别、问答等。
BERT 如何获得“博士学位”:领域适应
语言在不同领域之间存在着显著的差异。即使方言没有正式区分,即使是少量行话、术语或过时的用法,也可能影响语言模型在特定应用中的有效性。领域适应是将通用语言模型定向到更专业的语言术语的实践。
以下是一些已适应不同领域的 BERT 模型示例,用于特定的业务应用:
- BioBERT:一个在生物医学语料库上重新训练的 BERT 模型,支持此命名实体识别模型等应用,该模型可以对文本中晦涩的术语进行上下文化处理。
- SciBERT:一个类似的模型,但它是在一百多万篇已发表的文章上训练的。在计算机科学文章方面达到了最先进水平。
- BERTweet:一个在 8.5 亿条推文中训练的 RoBERTa 模型,被用于分析关于新型电子烟技术的公众讨论。
- FinBERT:一个模型,首先被改编为金融领域,然后针对金融新闻片段的情感分析这一特别棘手的任务进行了微调。
如今的 BERT:小型、快速模型的探索之旅
如今使用 BERT(和其他最先进模型)的一个主要限制是推理任务的速度和流畅性。这些模型的大部分活跃开发都致力于使其更快,以提供更好的客户体验,甚至缩小到足以安装在智能手机上并本地运行。
因此,BERT 研究的一个当前焦点是模型蒸馏:利用大型、高性能的模型来指导小型、更高效的模型训练。较小的、蒸馏后的模型学习模仿大型模型的大部分学习成果——这些知识对于较小的模型来说,在它们自己的训练过程中是无法获得的。
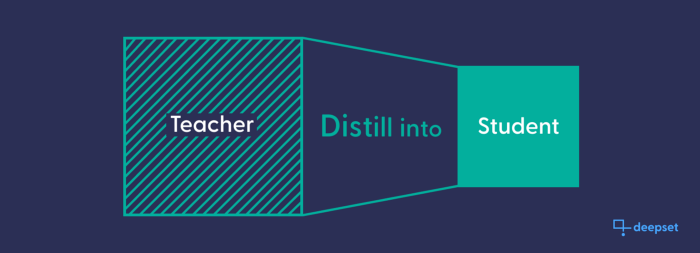
一个大型预训练模型充当一个未经训练的较小模型的老师,而较小的模型则被训练来模仿老师。结果是得到一个压缩的、资源消耗更少的模型,但效果相似。
BERT 的下一步是什么?
随着我们缩小 BERT 的能力不断提高,研究人员热衷于扩展原始模型的范围和能力。BERT 开发中的大部分创新都发生在对 BERT 学习的训练任务的改变上。
目前的大部分研究集中在寻找重要的替代训练任务,而不是创新 BERT 的核心架构。人们认为,增加更多样化的训练任务将特别有助于改进 BERT 作为可以进行微调的基础模型。这种多任务学习——一个能够解决多个任务的单一模型——可能具有更好的语义泛化能力,从而在单个任务上获得更好的性能。
为了突破界限,一些研究方向正在开发多模态 BERT 模型。使用修改后的 BERT 作为核心语义嵌入,可以训练模型将字符串转换为其他媒体,例如我们语义图像搜索教程。
结论
如果您想通过亲自动手来进一步了解 BERT 模型,我们的Haystack 框架是一个用于设置项目的无缝工具。您可以立即通过这个关于OpenAI 的 GPT 模型用于文本生成的教程开始。
如果您想咨询关于 BERT 的教程,或者只是想与 NLP 前沿的开发人员交流,我们的 Discord里挤满了友好的 BERT 专家,随时准备与您交流。
