

使用 KEDA 和 Haystack 扩展 NLP 索引管道 — 第一部分:应用程序
通过 LLM 实现检索增强生成式问答
2023年5月1日大型语言模型是最近备受吹捧的技术之一。通过将它们与充当长期记忆或文档存储的向量数据库结合起来,您可以使用其他上下文来改进提示。使用此技术的应用程序,例如 ChatGPT 插件和 Google 的 Magi 项目,正在迅速普及。对于许多业务用户来说,能够通过私有或最新数据来增强提示,是 区分原型和生产就绪的 NLP 应用程序的关键。
但是,我们如何创建一个可以将文件转化为可搜索文档的服务呢?以及我们如何有效地扩展这些应用程序来索引数百万个文件?
本文的目标是构建一个系统,该系统能够为大规模生产 NLP 应用程序运行用例特定的索引管道。 它将重点介绍 如何使用 Haystack 和 KEDA 创建、部署和动态扩展这些应用程序。第一部分介绍了使用 Haystack 创建 Python 应用程序。第二部分详细介绍了如何使用 KEDA 在 Kubernetes 上部署和扩展该应用程序。
本教程仅涵盖将文件转换为文本片段、嵌入或任意预处理数据。我们不会涵盖增强的 LLM 应用程序本身。如果您有兴趣创建此类应用程序,请随意使用本教程:使用 GPT-3 构建搜索引擎
自然语言处理基础
使用文档进行搜索的原理是填补模型知识的空白,例如最新新闻。这被称为检索增强生成 (RAG),这意味着除了模型自身的知识之外,模型还会使用您提供的文档来生成答案。您可以通过本教程 此处 找到有关如何创建使用预处理文档的搜索引擎的详细分步教程。
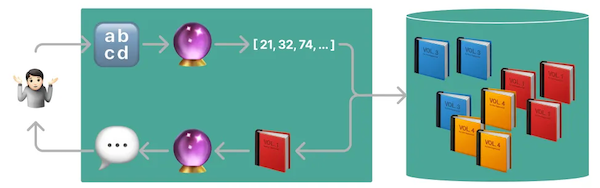
该图说明了将文本文件 (🔡) 通过模型 (🔮) 进行处理的过程,该模型生成向量并将其存储在向量数据库中,例如 Opensearch、Pinecone 或 Weaviate。之后,这些文档将被输入模型,然后将生成的输出提供给用户。
现在,让我们讨论如何有效地生成这些文档并将其输入向量数据库。
如何扩展索引应用程序
对于概念验证,工程师通常在具有 GPU 的虚拟机上创建嵌入,并将它们作为一次性作业添加到向量数据库中。一旦进入生产环境,我们将需要 定期 或 按需 运行这些作业,只要有新文件需要添加到模型的知识库中。有两个主要因素是我们想要优化的
- 吞吐量 — 在给定时间段内我们可以索引的最大文件数是多少?
- 延迟 — 文件添加后需要多长时间才能用于检索?
我们将使用用 Python 编写的无状态索引消费者,并学习如何使用 KEDA 在 Kubernetes 上进行自动扩展。这将实现吞吐量的水平扩展和延迟的按需启动。让我们深入了解架构设计!
架构
我们将要探索的架构背后的主要思想是将索引请求排队,然后启动处理这些任务的消费者。每个消费者接收逐个文件的消息并创建文档。我们使用以下概念
- 批处理 — 提高吞吐量并优化 GPU 利用率。
- 队列和处理的解耦 — 实现稳定且可扩展的长期运行流程。
- 自动扩展 — 通过根据待处理文件的数量进行扩展来提高吞吐量。
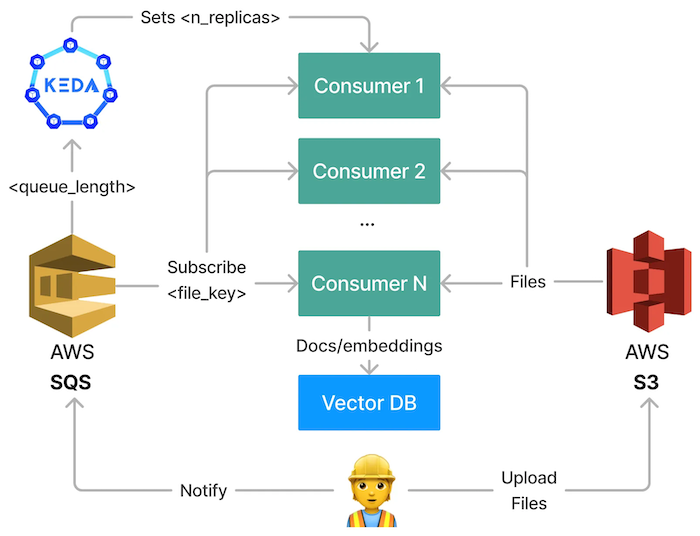
有各种技术可供我们实现这一点。我们将使用
- AWS S3 (简单存储服务) — 用于存储将用于搜索的原始文件
- AWS SQS (简单队列服务) - 用于解耦队列、处理和批处理
- Kubernetes — 用于运行我们的容器化应用程序
- 索引管道 (Haystack) - “消费者”应用程序,它订阅队列并从 S3 获取文件
- KEDA (Kubernetes 事件驱动的自动扩展) — 用于自动扩展我们的索引管道
您可以在 此存储库 中找到本文中使用的所有代码片段和配置文件。您可以使用它们从头开始重建此项目。 存储库链接: https://github.com/ArzelaAscoIi/haystack-keda-indexing
索引消费者
本章将引导您完成一个应用程序的创建过程,该应用程序将不断从 SQS 队列中拉取上传文件通知进行处理。收到新消息后,应用程序将从 S3 获取相应的文件,并将其转换为带有嵌入的多个文档。
这些“消费者”是我们架构的核心服务。我们将它们部署到 Kubernetes 并使用 KEDA 基于队列长度对其进行扩展。
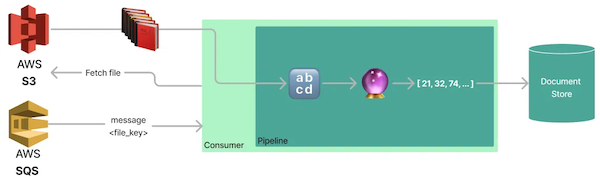
如果您只对使用 KEDA 扩展这些应用程序感兴趣,而不需要了解此服务的详细信息,那么您可以在下一部分中使用 Docker 镜像 arzelaascoli/keda-haystack-consumer:latest,然后跳过编写 Python 代码。
我们将从创建一个接收本地已下载文件的列表并将其转换为文档的代码片段开始。
索引管道
Haystack 使用 YAML 文件提供了一种创建管道的简单方法。在此示例中,我们将使用一个 标准模板,但我们将对其进行少量简化以满足我们的需求。
# pipeline yaml from Haystack: https://github.com/deepset-ai/templates/blob/69519af7178095d53cb5e879c8ac696d77c96aed/pipelines/GenerativeQuestionAnswering_gpt.yaml#L6
version: "1.15.1"
components:
## Uncomment if you have running an OpenSearch instance
# - name: DocumentStore
# type: OpenSearchDocumentStore
# params:
# user: <your-opensearch-user>
# password: <your-opensearch-password>
- name: Retriever
type: EmbeddingRetriever
params:
# document_store: DocumentStore # uncomment to connect the retriever to an OpenSearch instance
embedding_model: sentence-transformers/multi-qa-mpnet-base-dot-v1
model_format: sentence_transformers
top_k: 3
- name: AnswerGen
type: OpenAIAnswerGenerator
params:
model: text-davinci-003
api_key: <your-openai-api-key>
max_tokens: 200
temperature: 0.8
frequency_penalty: 0.1
presence_penalty: 0.1
top_k: 3
- name: FileTypeClassifier
type: FileTypeClassifier
- name: TextConverter
type: TextConverter
- name: PDFConverter
type: PDFToTextConverter
- name: Preprocessor
type: PreProcessor
params:
split_by: word
split_length: 250
split_overlap: 20
language: en
split_respect_sentence_boundary: True
pipelines:
# not required in our case, but can be used to query the document store
# with Haystack
- name: query
nodes:
- name: Retriever
inputs: [Query]
- name: AnswerGen
inputs: [Retriever]
- name: indexing
nodes:
- name: FileTypeClassifier
inputs: [File]
- name: TextConverter
inputs: [FileTypeClassifier.output_1]
- name: PDFConverter
inputs: [FileTypeClassifier.output_2]
- name: Preprocessor
inputs: [TextConverter, PDFConverter]
- name: Retriever
inputs: [Preprocessor]
## Uncomment if you have a running a document store.
## For this tutorial, we will generate embeddings and documents,
## but not store them in a document store to keep it generic.
## You can use any of Haystack's document stores here.
## Docs: https://docs.haystack.com.cn/docs/document_store
# - name: DocumentStore
# inputs: [Retriever]
此模板分为索引和查询管道。让我们先回顾一下索引管道的步骤
- FileTypeClassifier — 检查
.txt或.pdf文件的文件类型 - TextConverter — 从
.txt文件中提取文本 - PDFConverter — 从
.pdf文件中提取文本 - Preprocessor — 将文件中的文本分割成大小为 250 个字符的小块
- Retriever — 通过运行来自 Hugging Face 的模型
sentence-transformers/multi-qa-mpnet-base-dot-v1来计算分块文本的嵌入 - DocumentStore (已禁用) — 此节点将创建的文档(包括向量)发送到选定的数据库。出于本教程的目的,我们将跳过此步骤。但是,对于可扩展系统,您需要设置一个高度可扩展的向量数据库。一些合适的选项可能包括 OpenSearch、Weaviate、Qdrant 或其他。Haystack 支持许多不同的 文档存储客户端。
由于我们只关注索引文件,因此我们不会加载和运行查询管道。尽管如此,此管道只有两个步骤
- Retriever — 执行 k-近邻搜索以查找与您的提示匹配的文档。
- AnswerGen — OpenAI 的
text-davinci-003模型接收一个提示,该提示包含来自步骤 1 的检索到的文本,并生成一个答案作为响应。
在下一步中,我们将加载管道,以便我们可以运行本地文件的索引。
# pipeline.py
# link to file: https://github.com/ArzelaAscoIi/haystack-keda-indexing/blob/main/pipeline.py
from haystack import Pipeline
def get_pipeline(yaml_path: str) -> Pipeline:
return Pipeline.load_from_yaml(yaml_path, pipeline_name="indexing")
## example usage
# pipeline = get_pipeline("./pipelines/pipeline.yaml")
# documents = pipeline.run(file_paths=[Path(".your-file.txt")])
现在我们已经能够为本地文件生成文档,我们需要编写“粘合代码”,将我们的索引管道与 SQS 中的消息和 S3 中的文件连接起来。为了测试目的,我们还创建了一个代码片段来对文件进行索引排队。
使用 SQS 和 S3 进行索引的粘合代码
让我们从创建一个 S3Client 类开始,该类可以上传和下载文件到 Amazon S3 服务。AWS 通过 boto3 提供了一种便捷的与资源通信的方式。我们将使用这个库并为其方法编写简单的包装器。
# aws_service.py
# link to file: https://github.com/ArzelaAscoIi/haystack-keda-indexing/blob/main/aws_service.py
class S3Client:
def __init__(self, bucket_name: str, local_dir: str) -> None:
self.s3 = boto3.client(
"s3",
endpoint_url=AWS_ENDPOINT, # allows using localstack
region_name=AWS_REGION, # allows using localstack
)
self.bucket_name = bucket_name
self.local_dir = local_dir
def upload_file(self, local_path: Path) -> None:
"""
Upload file to s3 with the same name as the file on local filesystem.
:param local_path: Path to file on local filesystem
"""
file_name = os.path.basename(local_path)
self.s3.upload_file(
str(local_path),
self.bucket_name,
file_name,
ExtraArgs={"ACL": "public-read"},
)
def download_files(self, s3_keys: List[str]) -> List[Path]:
"""
Download files from s3 to local directory.
TODO: Make this async to speed up the upload process
TODO: delete files from local directory after processing
:param s3_keys: List of keys on s3
:returns List of paths to downloaded files
"""
paths: List[Path] = []
for s3_key in s3_keys:
response = self.s3.get_object(Bucket=self.bucket_name, Key=s3_key)
file_name = os.path.basename(s3_key)
local_path = os.path.join(self.local_dir, file_name)
paths.append(Path(local_path))
with open(local_path, "wb") as f:
f.write(response["Body"].read())
return paths
在实现文件上传和下载功能后,我们需要使消费者能够获取已排队等待索引的待处理 S3 密钥。为此,我们创建了一个 SQSClient 类,该类可以向 Amazon SQS 服务发布和接收消息。与 S3Client 类似,boto3 为此目的提供了一些简单的方法。
class SQSClient:
def __init__(self, queue_name: str) -> None:
self.sqs = boto3.client(
"sqs",
endpoint_url=AWS_ENDPOINT, # allows using localstack
region_name=AWS_REGION, # allows using localstack
)
self.queue_name = queue_name
self.queue = self.sqs.get_queue_url(QueueName=self.queue_name)
def publish_key(self, key: str) -> None:
"""
Publish key to SQS queue
:param key: s3 Key to publish
"""
self.sqs.send_message(QueueUrl=self.queue["QueueUrl"], MessageBody=key)
@contextmanager
def fetch_keys(self) -> Generator[List[str], None, None]:
"""
Fetch messages from defined queue
:returns List of keys on s3
"""
# receive up to 10 messages at once from sqs
response = self.sqs.receive_message(
QueueUrl=self.queue["QueueUrl"],
MaxNumberOfMessages=10,
WaitTimeSeconds=0,
)
# get s3 keys from sqs messages
messages = response.get("Messages", [])
s3_keys = [message["Body"] for message in messages]
try:
# We are using a context manager to ensure the messages
# are deleted from the queue after handling them was
# successful.
yield s3_keys
# This will be run after the message was processed
for message in messages:
self.sqs.delete_message(
QueueUrl=self.queue["QueueUrl"],
ReceiptHandle=message["ReceiptHandle"],
)
except Exception as error:
raise error
我们将把这两个客户端连接到一个具有两个方法的服务
get_files- 此方法从 SQS 获取文件消息,从 S3 下载相应的文件,并返回本地路径。upload_file- 此方法将本地路径的文件上传到 S3,并将密钥发布到 SQS,供索引消费者稍后拾取。
# aws_service.py
# link to file: https://github.com/ArzelaAscoIi/haystack-keda-indexing/blob/main/aws_service.py
class AWSService:
def __init__( self, queue_name: str, bucket_name: str, local_download_dir: str ) -> None:
self.sqs_client = SQSClient(queue_name)
self.s3_client = S3Client(bucket_name, local_download_dir)
def get_files(self) -> List[Path] | None:
with self.sqs_client.fetch_keys() as messages:
if not messages:
return
paths = self.s3_client.download_files(messages)
return paths
def upload_file(self, local_path: Path) -> None:
self.s3_client.upload_file(local_path)
self.sqs_client.publish_key(local_path.name)
使用 LocalStack 设置本地 AWS 环境
我们使用 LocalStack 来简化开发过程,并避免使用真实的 AWS 基础设施。要启动 LocalStack,请在终端中使用 docker-compose.yaml 文件运行 docker-compose up。
# docker-compose.yaml
# link to file:https://github.com/ArzelaAscoIi/haystack-keda-indexing/blob/main/docker-compose.yaml
version: "3"
services:
localstack:
image: localstack/localstack:1.4.0
ports:
- "127.0.0.1:4566:4566" # LocalStack Gateway
- "127.0.0.1:4510-4559:4510-4559" # external services port range
environment:
- SERVICES=s3,sqs
- AWS_ACCESS_KEY_ID=test
- AWS_SECRET_ACCESS_KEY=test
volumes:
# startup script to create a sqs queue and a s3 bucket
# https://github.com/ArzelaAscoIi/haystack-keda-indexing/blob/main/scripts/sqs_bucket_bootstrap.sh
- ./scripts:/docker-entrypoint-initaws.d/ # startup script found here
启动后,我们将运行 一个脚本,该脚本创建一个 test-queue 和一个 test-bucket,我们可以使用它们来测试我们的应用程序。在接下来的步骤中,我们将创建 AWS 客户端以从 SQS 读取消息并从 S3 下载文件。
运行消费者
现在我们能够运行管道、上传和下载文件以及设置我们的本地 AWS 环境,我们需要编写主服务。在代码层面,我们只需要实现一个简单的循环来不断拉取消息并运行索引。
# consumer.py
# link to file:https://github.com/ArzelaAscoIi/haystack-keda-indexing/blob/main/consumer.py
# To learn more about logging in python check out my other article
# about structolg! https://medium.com/@ArzelaAscoli/writing-professional-python-logs-e1f31635b60b
logger = structlog.get_logger(__name__)
# Initialize AWS service
aws_service = AWSService(SQS_QUEUE, S3_BUCKET, LOCAL_DOWNLOAD_DIR)
# load pipeline
pipeline = get_pipeline("./pipelines/pipeline.yaml")
while True:
# fetch files from aws
files: List[Path] = aws_service.get_files()
if not files:
logger.info("No files to process")
sleep(5)
continue
# process files if found
logger.info("Found files", files=files)
# run indexing for downloaded files
documents = pipeline.run(file_paths=files)
logger.info("Processed files", documents=documents)
我们现在将使用 Haystack GPU 基础映像创建一个应用程序映像,该映像已预装了我们的大部分依赖项。
# Dockerfile
# link to file: https://github.com/ArzelaAscoIi/haystack-keda-indexing/blob/main/Dockerfile
FROM deepset/haystack:base-gpu-v1.15.0
WORKDIR /home/user
COPY . .
RUN pip3 install -r requirements.txt
CMD ["python3", "consumer.py"]
通过将启动配置添加到 docker-compose,我们不仅可以运行 LocalStack,还可以在 Docker 中运行我们的应用程序,方法是调用 docker-compose up。
# docker-compose.yaml
# link to file: https://github.com/ArzelaAscoIi/haystack-keda-indexing/blob/main/docker-compose.yaml
...
consumer:
build:
context: .
dockerfile: Dockerfile
environment:
- AWS_ENDPOINT=http://localstack:4566
- AWS_REGION=eu-central-1
- AWS_ACCESS_KEY_ID=test
- AWS_SECRET_ACCESS_KEY=test
我们现在准备通过上传文件并检查日志以获取生成的文档来测试我们的应用程序。
使用 Docker Compose 进行测试
要启动我们的 Docker Compose 堆栈,我们使用命令 docker-compose up。此外,我们提供了一个文件上传的代码片段。
# upload.py
# link to file: <https://github.com/ArzelaAscoIi/haystack-keda-indexing/blob/main/upload.py>
aws_service = AWSService(SQS_QUEUE, S3_BUCKET, LOCAL_DOWNLOAD_DIR)
aws_service.upload_file(Path("./data/test.txt"))
如果我们现在运行 python3 upload.py upload.py,我们将在 Docker 控制台中看到以下输出。
haystack-keda-indexing-localstack-1 | 2023-04-22T09:55:44.981 INFO --- [ asgi_gw_1] localstack.request.aws : AWS s3.GetObject => 200
haystack-keda-indexing-localstack-1 | 2023-04-22T09:55:45.007 INFO --- [ asgi_gw_0] localstack.request.aws : AWS sqs.DeleteMessage => 200
haystack-keda-indexing-consumer-1 | 2023-04-22 09:55:45 [info ] Found files files=[PosixPath('/tmp/test.txt')]
Converting files: 100%|██████████| 1/1 [00:00<00:00, 81.28it/s]
Preprocessing: 100%|██████████| 1/1 [00:00<00:00, 35.10docs/s]
Batches: 100%|██████████| 1/1 [00:03<00:00, 3.18s/it]
haystack-keda-indexing-consumer-1 | 2023-04-22 09:55:48 [info ] Processed files documents={'documents': [<Document: {'content': 'this is text', 'content_type': 'text', 'score': None, 'meta': {'_split_id': 0}, 'id_hash_keys': ['content'], 'embedding': '<embedding of shape (768,)>', 'id': '46ec22c7eafaea7c43eef7d996fd04ce'}>], 'file_paths': [PosixPath('/tmp/test.txt')], 'root_node': 'File', 'params': {}, 'node_id': 'Retriever'}
haystack-keda-indexing-localstack-1 | 2023-04-22T09:55:48.327 INFO --- [ asgi_gw_0] localstack.request.aws : AWS sqs.GetQueueUrl => 200
我们拥有一个无状态服务,该服务异步处理索引请求,并且可以在 Docker Compose 中运行。我们现在可以将其部署到 Kubernetes,配置 KEDA 并进行扩展。
结论和后续步骤
本文介绍了如何创建一个将文件转换为文档的无状态消费者应用程序。我们了解到,可以使用此应用程序与 Haystack 在单个配置文件中定义的各种模型、预处理器和文件类型。为了将此应用程序投入生产就绪的部署,我们将在 下一章 中将其部署到 Kubernetes 并定义自定义自动扩展。
