

使用 GPT-3 构建搜索引擎
将大型语言模型的力量与您选择的语料库相结合,生成基于事实的、听起来自然的答案
2023 年 1 月 31 日如果您最近上网,您可能会看到关于 OpenAI 最新语言模型 ChatGPT 的热烈讨论。ChatGPT 在许多方面都表现出色,包括调试代码和以您要求的任何风格重写文本。作为 GPT-3.5 的一个分支,GPT-3.5 是一个拥有数十亿参数的大型语言模型 (LLM),ChatGPT 的令人印象深刻的知识量归功于它在训练期间看到了互联网的大部分内容 — 以 Common Crawl 语料库和其他数据的形式。
在几十年的聊天机器人甚至无法记住它们前一刻说过的话之后,人们对一个能够进行对话并产生有力智能表象的语言模型感到兴奋是可以理解的。但是,当涉及到这些巨大模型生成的答案的有效性时,我们需要保持批判性。LLM 特别容易产生幻觉:产生乍一看似乎合理,但仔细检查后站不住脚的文本,并将完全虚构的东西呈现为事实。
我们 deepset 的专长是语义搜索引擎,它们通常由抽取式问答模型提供支持。这些模型会逐字返回知识库中的片段,而不是像 ChatGPT 那样从头开始生成文本。然而,许多应用程序可以从生成式 LLM 的能力中受益。这就是为什么 deepset 的开源应用自然语言处理 (NLP) 框架Haystack允许您在管道中使用多个 GPT 模型。通过这种方法,您可以构建一个由 GPT 驱动的语义搜索引擎,该引擎使用您自己的数据作为事实依据,并基于其中包含的信息给出自然语言答案。
您可以将 Haystack 视为一个全面且高度灵活的工具箱,其主要目标是使构建不同类型的 NLP 系统变得轻松快捷,同时保持透明。除了为OpenAI API提供便捷的入口点外,Haystack 还提供了成功实现包含 GPT 的端到端 NLP 系统所需的所有其他组件:矢量数据库、检索模块以及将所有这些元素组合成一个可查询系统的管道。
在本文中,我们将演示如何构建一个生成式问答系统,该系统使用 GPT-3 “davinci-003” 模型以令人信服的自然语言呈现结果。
大型语言模型的出现
难道所有现代语言模型都很庞大吗?这是真的 — 自从 Transformer 被引入作为各种 NLP 任务的基线超越架构以来,模型就越来越大。但是,虽然最大的 BERT 模型拥有 3.36 亿个参数,但 OpenAI 的最大的 GPT-3.5 模型 — ChatGPT 的基础 — 拥有其 520 倍的参数。

那么 GPT 利用所有额外的容量做了什么?从观察来看,我们可以说 GPT 在理解暗示和意图方面非常出色。它可以记住对话中之前讨论过的内容,包括弄清楚您用“他”或“在那之前”这样的词指代什么,并且它可以告诉您您的问题何时没有意义。所有这些特性都带来了更强的智能感。它还必须从头开始生成语言,这是一项比从语料库中检索正确部分更艰巨的任务。但研究也表明,GPT 使用其大量参数来存储事实 — 实际信息,然后它将其用于代码调试和回答常识性问题等任务。
但问题来了:GPT 仍然可能犯下严重的错误,而且这些错误更难检测,因为它非常擅长对话,并且使它的答案和代码示例*看起来*是正确的。早在十二月初,编程问答论坛Stack Overflow 暂时禁止了 ChatGPT 生成的解决方案。与此同时,大型语言模型的幻觉已经催生了一个新的研究领域。
但是,有一种方法可以更安全地使用 GPT 模型并产生价值。通过将生成模型连接到一个包含精选、领域特定内容的文本数据库 — 例如,产品评论语料库、金融报告集合或研究论文数据库 — 您可以将事实准确性与 GPT 的对话能力相结合。有了 Haystack,您可以立即设置这样一个基于 GPT 的搜索引擎。搜索引擎位于您的文本数据库之上,并响应输入查询返回自然语言答案。
不同类型的搜索引擎
语义搜索引擎有不同的种类,可以大致根据它们返回的答案类型来区分。答案可能包括匹配的文档(在文档搜索中)、答案片段(在抽取式问答中)或新生成的答案(在生成式问答中)。
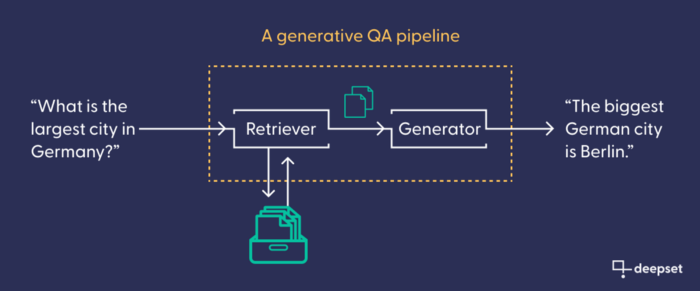
GenerativeQAPipeline:Haystack 用于生成式搜索引擎的组件
对于这些搜索范式中的每一种,Haystack 都提供了现成的管道:搜索引擎配置,带有用于语言模型的占位符,以实现最大效率。在本教程中,我们使用 GenerativeQAPipeline。它由一个检索器(用于查找相关文档)和一个生成器(用于编写文本)组成,它们相互连接。检索器连接到数据库。与生成器一样,它通常(但并非总是)基于 Transformer 模型。它的任务是根据用户的输入查询,从数据库中检索最有可能包含有价值信息的文档。然后,我们的生成模型将这些文档作为事实依据来编写其答案。
如何使用 GPT-3 构建搜索引擎
在我们开始之前,让我们快速谈谈您需要遵循的工具。
前提条件
- 您需要安装 Haystack。我们使用的是 1.13 版本。
- 要使用OpenAI API,您需要创建一个账户并生成一个 API 密钥。请注意,虽然最初的查询是免费的,但一旦达到一定限制,您就需要付费。(OpenAI 会为您提供 18 美元的初始额度,这足以完成本教程并试用该管道。)
- 这里我们使用了一个包含 18 篇关于德国首都柏林的维基百科文章的小型数据集。当然,您也可以使用自己的数据集。
- 由于我们的嵌入和答案通过 OpenAI API 提供,因此本指南不需要使用 GPU。但是,如果您想尝试不同的模型,我们建议您在Colab 笔记本中进行操作并激活 GPU(在“Runtime -> Change runtime type”下)。
转换和预处理
在设置管道之前,您需要预处理数据并将其添加到文档存储或数据库中。Haystack 中有许多文档存储选项。本教程使用 FAISS,这是一个矢量数据库。
在将数据馈送到文档存储之前,您需要将其转换为正确的格式。DocumentStore 期望数据以 Haystack 数据类型 Document 的形式提供 — 这是一种字典数据类型,它将信息存储在一组相关字段中(例如文档文本及其元数据)。convert_files_to_docs 函数从目录中检索文件并将其转换为 Haystack 文档。如果您使用的是维基百科的文章,可以使用 clean_wiki_text 清理函数来删除一些维基百科特有的样板信息。
from haystack.utils import convert_files_to_docs, clean_wiki_text
docs = convert_files_to_docs(dir_path=DOC_DIR, clean_func=clean_wiki_text, split_paragraphs=True)
根据您自己数据的格式,您可能需要遵循略有不同的预处理过程。使用 Haystack,您可以从网站提取数据,或转换 pdf、txt 或 docx 等不同文件格式。请查看我们的预处理教程和FileConverter的文档页面以了解更多信息。
许多文档,包括关于热门话题的维基百科文章,可能非常长。您需要确保数据库中的文档足够短,以便嵌入模型能够正确捕捉其含义。为此,您可以使用PreProcessor将其分割成更短的文本片段。我们建议将分割长度设置为每个片段 100 个 token,重叠 3 个 token,以确保不会丢失任何信息。
from haystack.nodes import PreProcessor
preprocessor = PreProcessor(
clean_empty_lines=True,
clean_whitespace=True,
clean_header_footer=False,
split_by="word",
split_length=100,
split_overlap=3,
split_respect_sentence_boundary=False,
)
processed_docs = preprocessor.process(docs)
这些处理过的文档看起来是什么样的?让我们来看一个
processed_docs[0]
<Document: {'content': 'The Berlin U-Bahn (German: [ˈuː baːn]; short for Untergrundbahn, "underground railway") is a rapid transit system in Berlin, the capital and largest city of Germany, and a major part of the city\'s public transport system. Together with the S-Bahn, a network of suburban train lines, and a tram network that operates mostly in the eastern parts of the city, it serves as the main means of transport in the capital.\nOpened in 1902, the U-Bahn serves 175 stations[1] spread across nine lines, with a total track length of 155.4 kilometres (96 miles 45 chains),[3] about 80% of which is underground.[4] Trains run',
'content_type': 'text',
'score': None,
'meta': {'name': 'Berlin U-Bahn.txt', '_split_id': 0},
'embedding': None,
'id': 'd2bf58a531b2500250650b43b1cce290'}>
每个文档都已转换为 Document 类的一个对象,这是一个字典,不仅包含文档的文本,还包含一些自动生成的元数据,例如文本来自哪个文件。
初始化 DocumentStore
现在是时候设置文档存储了 — 例如,经过矢量优化的 FAISS 数据库。在初始化文档存储时,您需要知道检索器的文档矢量嵌入的长度 — 这是它将为每个文档生成的内部表示。由于您将使用 OpenAI 的高维 text-embedding-ada-002 模型,因此需要将矢量的 embedding_dim 设置为 1536。
from haystack.document_stores import FAISSDocumentStore
document_store = FAISSDocumentStore(faiss_index_factory_str="Flat", embedding_dim=1536)
现在,删除数据库中任何现有的文档,并添加您之前生成的预处理文档。
document_store.delete_documents()
document_store.write_documents(processed_docs)
请注意,到目前为止,数据库仅包含纯文本文档。要添加高维矢量嵌入 — 使语言模型能够理解并用于语义搜索的每个文档的表示 — 您需要设置检索模型。
检索器
检索器是匹配您的查询与数据库中文档的模块,并检索它认为最有可能包含答案的文档。检索器可以是基于关键词的(如 tf-idf 和 BM25),也可以通过使用 Transformer 生成的文本矢量来编码语义相似性。在后一种情况下,检索器也用于*索引*数据库中的文档 — 即,将它们转换为检索器可以搜索的高维嵌入。
您将使用OpenAI 最新的检索模型,text-embedding-ada-002。要在 Haystack 中初始化它,您需要提供您的 OpenAI API 密钥。
from haystack.nodes import EmbeddingRetriever
retriever = EmbeddingRetriever(
document_store=document_store,
embedding_model="text-embedding-ada-002",
batch_size = 32,
api_key=MY_API_KEY,
max_seq_len = 1024
)
在设置检索器时,您会将其直接连接到您的文档存储。现在您可以使用 update_embeddings 方法将文档存储中的原始文档转换为检索模型可以搜索和比较的高维矢量。
document_store.update_embeddings(retriever)
生成器
现在您已准备好初始化将为您生成文本的 GPT 模型。 OpenAIAnswerGenerator 节点可以使用四种不同的 GPT 模型。您可以使用性能最佳的 GPT-3.5 模型,即 text-davinci-003。
from haystack.nodes import OpenAIAnswerGenerator
generator = OpenAIAnswerGenerator(api_key=MY_API_KEY, model="text-davinci-003", temperature=.5, max_tokens=30)
我们建议将 max_tokens 参数从默认值 13 增加到 30,以便 GPT 模型能够生成更长的序列。我们还建议将 temperature 设置为 .5(默认值为 .2),这使得模型在生成其答案时有更多的自由度。temperature 越低,模型越能忠实于底层源文本。
管道
现在您的 GPT 搜索引擎的所有独立元素都已设置好,是时候将它们传递给您的生成式 QA 管道了。
from haystack.pipelines import GenerativeQAPipeline
gpt_search_engine = GenerativeQAPipeline(generator=generator, retriever=retriever)
就是这样!您的 GPT 驱动的搜索引擎已准备好进行查询。
查询管道
现在您可以向您的系统提出一些关于柏林(或您的数据集关于其他任何主题)的常识性问题。除了查询本身,您还可以向搜索引擎传递一些参数,例如检索器应传递给生成器的文档数量以及应生成的答案数量(两者都指定为“top_k”)。
query = "What is Berlin known for?"
params = {"Retriever": {"top_k": 5}, "Generator": {"top_k": 1}}
answer = gpt_search_engine.run(query=query, params=params)
要打印由您的管道生成的答案,请导入 Haystack 有用的 print_answers 函数。它可以让您确定打印答案时要显示的详细程度。将其设置为 minimum 将仅打印答案字符串。那么搜索引擎对上述问题的回答是什么?
from haystack.utils import print_answers
print_answers(answer, details="minimum")
>>> Query: What is Berlin known for?
Answers:
[ { 'answer': "Berlin is known for its diverse culture, its nightlife, its contemporary arts, and its high quality of life."}]
请注意,此答案是凭空生成的:它不是从任何维基百科文章中引用的,而是基于其中的内容编写的。
生成的答案是上下文相关的
还记得我们之前说过 GPT-3 模型是根据它接收到的文档生成答案的吗?您现在可以通过独立运行生成器来测试这一点,而无需检索器。不过,您不能在没有任何文档的情况下运行它,因此您需要向其传递一个单独的片段。如果您使用上面打印出的关于 U-Bahn 的片段,会发生什么
generator.predict("What is Berlin known for?", documents=[processed_docs[0]])
>>> Query: What is Berlin known for?
Answers:
[ { "answer": "The Berlin U-Bahn."}]
系统回答说柏林以其地下铁路而闻名,因为那是该文档提供的全部知识。
现在,回到搜索引擎的完整版本 — 那个已经摄入了您全部数据集(例如,所有 18 篇关于柏林的维基百科文章)的版本 — 并问它几个问题,以更好地了解您的搜索引擎是如何工作的。
示例 1
Query: When is the best time to visit Berlin?
Answers:
[ { "answer": """ Berlin is a great city to visit year-round,
but the besttime to visit is during the summer months, from June to
August."""}]
示例 2
Query: Do people from Berlin have a dialect?
Answers:
[ { "answer": """ Yes, people from Berlin have a dialect, which is a variant
of the Brandenburgish dialect."""}]
示例 3
Query: Tell me about some interesting buildings in Berlin.
Answers:
[ { "answer": """The Berlin TV Tower is a TV Tower in Berlin, Germany. It
is Berlin’s tallest structure, at a height of 1,207 feet. """}]
示例 4
Query: How was the TV tower built?
Answers:
[ { "answer": """The TV tower was built by a team of architects between
1965 and 1969. The tower was built in a record-breaking
time of just 53 months,"""}]
GPT 的一个有趣之处在于它并不总是返回相同的答案。当多次提示相同的查询时,它会尝试提出不同的答案。当我们在自己完成本教程时,我们的模型在多次收到相同问题后,出现了一个严重的幻觉。看看这个答案
Query: How was the TV tower built?
Answers:
[ { "answer": """ The TV Tower was built by the Soviet troops by setting the
contents on fire and turning the tower into a makeshift
chimney."""}]
这个答案 — 排名低于正确答案 — 相当荒谬。但它应该提醒我们,生成模型的输出,即使看起来是一个格式良好的答案,也可能完全是幻觉,应该进行事实核查。
示例 5
Query: Is Berlin a good place for clubbing?
Answers:
[ { "answer": """Yes, Berlin is a good place for clubbing. There are many
nightclubs, including the Watergate, Tresor, and Berghain."""}]
比较生成式问答和抽取式问答
与此生成式管道一样,基于抽取式问答的搜索引擎会响应自然语言查询,就语料库中的文档返回答案。但是,由于抽取式问答系统逐字从文档文本中提取答案,因此与 GPT 搜索引擎相比,它存在一些限制。
抽取式问答模型无法产生您在上面的示例中看到的那些对话元素,例如回答“是”,或在答案中重复问题的部分。更重要的是,它无法像 GPT 模型那样全面地回答问题,因为它无法聚合来自不同文本的信息。
在最后一个示例中,GPT 确认柏林是俱乐部的好去处,然后继续列出一些著名夜总会的例子。
但是,当抽取式问答模型被问到同样的问题时,它只能通过提取它认为与查询最相关的文本片段来隐式地回答问题。以下是此类抽取式问答搜索引擎返回的两个答案,包括它们提取的“上下文”部分
Query: Is Berlin a good place for clubbing?
Answers:
[ { "answer": """ Partygoers in Germany often toast the New Year with a glass
of sparkling wine""",
"context": """ke place throughout the entire city. Partygoers in Germany
often toast the New Year with a glass of sparkling wine.\n
Berlin is home to 44 theaters and """},
{ "answer": "Berlin’s club scene a premier nightlife venue”,
"context": """rticularly those in Western and Central Europe, made
Berlin’s club scene a premier nightlife venue. After the
fall of the Berlin Wall in 1989, many hi"""}]
您应该使用生成式还是抽取式问答?
生成式问答相对于抽取式问答的优势显而易见:它具有更好的对话能力,能生成格式良好的自然语言句子,并且能在单个答案中聚合来自多个来源的知识。但是,正如我们所见,它也有一些缺点。在以下情况下,您应该考虑使用抽取式而不是生成式问答
- 当您想使用小型、开源模型时。正如我们所见,GPT 模型非常庞大,一旦您达到一定的查询限制,就需要付费才能使用 API。Hugging Face 模型中心,另一方面,托管着数千个开源的预训练模型,您可以免费下载。
- 当您想要透明地了解模型的信息来源时。抽取式模型不会产生幻觉。当然,这些模型也可能返回错误的答案。但通过检查它们提取的上下文,可以更容易地检测到这些错误。
- 当您想在下游任务中使用答案时。抽取式问答最受欢迎的应用之一是信息提取系统。这些系统不需要生成式搜索引擎的对话能力。相反,它们需要一种能够快速可靠地从大型语料库中提取事实信息的搜索功能。
Haystack:构建搜索引擎的主要框架
生成式问答、抽取式问答、翻译、摘要等等:使用 Haystack,您可以构建最适合解决您特定问题的系统,并使用最新、最热门的架构。
我们以应用为中心的 NLP 方法为您提供了模块化的构建块,使您能够以最短的时间设置自己的系统。查看Haystack 存储库以了解更多信息,或查看我们的文档。
想聊聊 GPT-3、搜索引擎以及所有 NLP 相关的内容吗? 加入我们的 Discord!
