

从头开始构建 RAG Pipeline
让我们通过简单地连接三个组件:Retriever(检索器)、PromptBuilder(提示构建器)和 Generator(生成器),来用 Haystack 构建一个简单的 RAG Pipeline。
2023年11月21日检索增强生成(RAG)正迅速成为一项基本技术,可以使 LLM 在回答任何问题(无论多么具体)时都更加可靠和有效。为了在当今的 NLP 领域保持相关性,Haystack 必须支持它。
让我们看看如何使用 Haystack 2.0 来构建此类应用程序,从直接调用 LLM 到一个功能齐全、可投入生产且可扩展的 RAG Pipeline。在本篇文章的结尾,我们将构建一个能够根据私有数据库中存储的数据回答有关世界国家问题的应用程序。届时,LLM 的知识将仅限于我们数据存储的内容,而所有这一切都可以在不微调语言模型的情况下完成。
💡 我最近就 Haystack 2.0 中的 RAG 应用程序发表了演讲,如果您更喜欢视频而非博客文章,可以 在此处 找到录音。请注意,代码可能已略有过时。
什么是 RAG?
检索增强生成(RAG)的概念最早在 Meta 于 2020 年发表的一篇 论文 中提出。它的设计目的是解决 seq2seq 模型(语言模型,给定一个句子,可以为你续写)的一些固有局限性,例如:
- 它们的内部知识,无论多么浩瀚,总会是有限的,而且至少会有点过时。
- 它们最擅长通用主题,而不是小众和特定领域,除非经过专门的微调,这是一个昂贵且缓慢的过程。
- 所有模型,即使是那些拥有专业知识的模型,也倾向于“产生幻觉”:它们会自信地产生错误的陈述,并附带看似合理的推理。
- 它们无法可靠地引用来源或说明其知识的来源,这使得对其回复进行事实核查变得不那么容易。
RAG 通过提供一些相关的、最新的、可信的信息以及用户的问题来解决这些“将 LLM 真实化”的问题。通过这种方式,LLM 不需要从其内部知识中提取信息,而是可以基于用户提供的片段来回答。
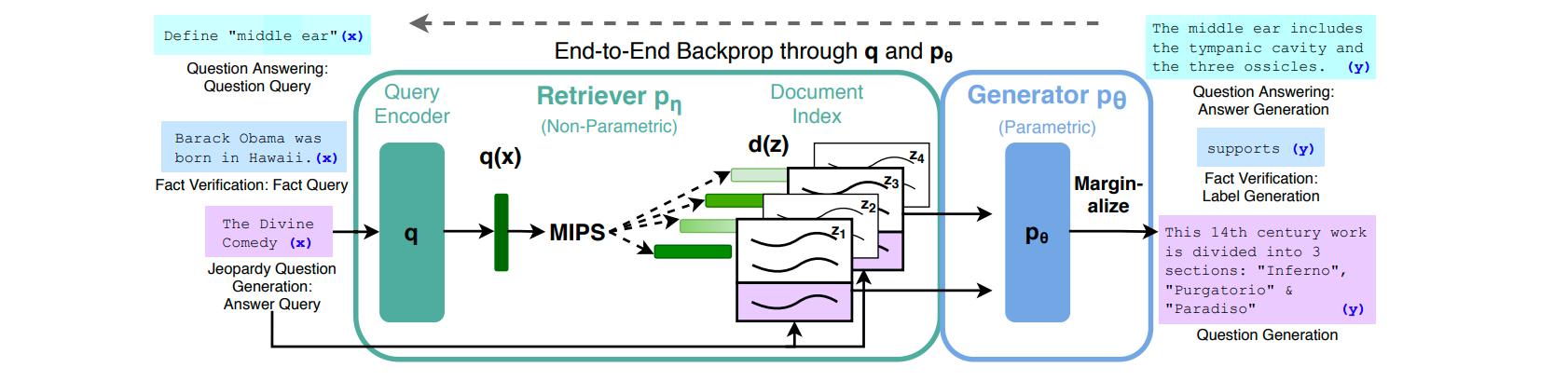
正如您在上图(直接取自原始论文)中看到的,像 RAG 这样的系统由两部分组成:一部分负责查找与用户提出的问题相关的文本片段,另一部分是一个生成模型(通常是 LLM),负责将这些片段重写成连贯的答案。
让我们用 Haystack 2.0 来构建一个!
💡 想看看这段代码的实际运行效果吗?请查看 此处的 Colab notebook。
⚠️ 警告: 此代码已在
haystack-ai==2.0.0b5上进行测试。Haystack 2.0 仍不稳定,因此在 Haystack 2.0 正式发布之前,后续版本可能会带来不通知的重大更改。然而,概念和组件保持不变。
生成器:Haystack 的 LLM 组件
作为任何一个称职的 NLP 框架,Haystack 以不同的方式支持 LLM。在 Haystack 2.0 中查询 LLM 最简单的方法是通过 Generator 组件:取决于您使用的 LLM 和查询方式(聊天、文本补全等),您应该选择合适的类。
在这些示例中,我们将使用 gpt-3.5-turbo(ChatGPT 背后的模型),因此所需的组件是 OpenAIGenerator。以下是使用它来查询 OpenAI 的 gpt-3.5-turbo 所需的所有代码:
from haystack.components.generators import OpenAIGenerator
generator = OpenAIGenerator(api_key=api_key)
generator.run(prompt="What's the official language of France?")
# returns {"replies": ['The official language of France is French.']}
您可以通过在初始化时指定 model 来选择您喜欢的 OpenAI 模型,例如 gpt-4。它还支持设置 api_base_url 以进行私有部署,设置 streaming_callback 以便您可以在终端实时查看生成的输出,以及可选的 kwargs 以允许您传递模型理解的任何其他参数,例如答案数量(n)、温度(temperature)等。
请注意,在此示例中,我们将 API 密钥传递给了组件的构造函数。这是不必要的:OpenAIGenerator 可以从 OPENAI_API_KEY 环境变量以及 openai SDK 的 api_key 模块变量中读取该值。
目前,Haystack 支持通过 HuggingFaceLocalGenerator 和 HuggingFaceTGIGenerator 组件来使用 HuggingFace 模型,并且更多 LLM 即将推出。
PromptBuilder:从模板构建结构化提示
让我们设想一下,我们的 LLM 驱动的应用程序还附带了一些预定义的问答,用户可以选择这些问题而不是输入完整的句子。例如,与其让用户输入 法国的首都是哪里?,不如让他们从列表中选择 告诉我官方语言,然后用户只需输入“法国”(或者为了好玩输入“瓦坎达”——我们的聊天机器人也需要一些挑战)。
在这种情况下,提示中有两部分:一个变量(国家名称,例如“法国”)和一个提示模板,这里是 "What's the official language of {{ country }}?"。
Haystack 提供了一个组件,可以渲染变量到提示模板中:它叫做 PromptBuilder。与我们之前看到的生成器一样,PromptBuilder 的初始化和使用也近乎简单。
from haystack.components.builders.prompt_builder import PromptBuilder
prompt_builder = PromptBuilder(template="What's the official language of {{ country }}?")
prompt_builder.run(country="France")
# returns {'prompt': "What's the official language of France?"}
注意我们是如何定义一个变量 country 的,方法是用双大括号将其名称括起来。PromptBuilder 允许您以这种方式定义任何输入变量:如果提示模板是 "What's the official language of {{ nation }}?",那么 PromptBuilder 的 run() 方法就会期望一个 nation 输入。
这种语法来自 Jinja2,一个流行的 Python 模板库。如果您曾经使用过 Flask、Django 或 Ansible,那么您会很快熟悉 PromptBuilder。反之,如果您从未听说过这些库中的任何一个,您可以查阅 Jinja 文档中的 语法。Jinja 有一个强大的模板语言,并提供了比您在提示模板中可能需要的更多的功能,从简单的 if 语句和 for 循环到通过点表示法进行对象访问、模板嵌套、变量操作、宏、完整的模板导入和封装等。
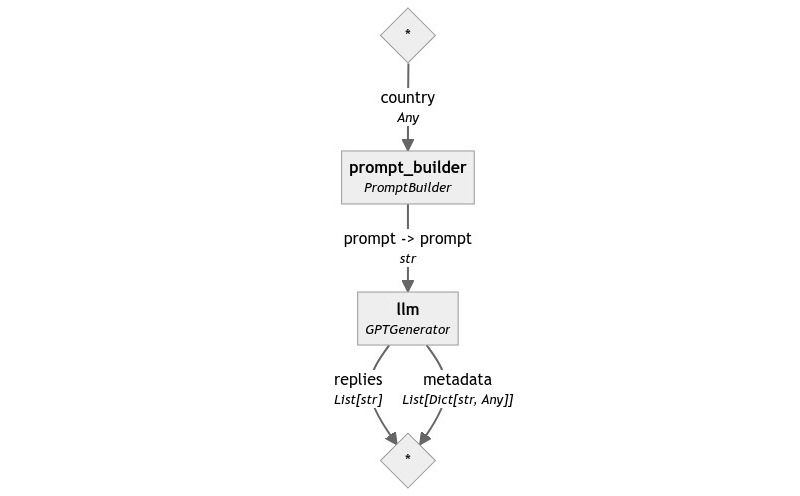
一个简单的生成式 Pipeline
有了这两个组件,我们可以组装一个最小的 Pipeline 来看看它们如何协同工作。连接它们很简单:PromptBuilder 生成一个 prompt 输出,而 OpenAIGenerator 期望一个同名同类型的输入。
from haystack import Pipeline
from haystack.components.generators import OpenAIGenerator
from haystack.components.builders.prompt_builder import PromptBuilder
pipe = Pipeline()
pipe.add_component("prompt_builder", PromptBuilder(template="What's the official language of {{ country }}?"))
pipe.add_component("llm", OpenAIGenerator(api_key=api_key))
pipe.connect("prompt_builder", "llm")
pipe.run({"prompt_builder": {"country": "France"}})
# returns {"llm": {"replies": ['The official language of France is French.'] }}
这是 Pipeline 图
让 LLM 作弊
构建 RAG 应用程序的生成部分非常简单!到目前为止,我们只向 LLM 提供了问题,但没有提供用于回答的信息。如今,LLM 拥有大量的通用知识,因此对于法国或德国等著名国家的问题,它们很容易正确回答。然而,在使用一个关于世界国家的应用程序时,一些用户可能对了解一些已经不存在的、不为人知的或已消失的微型国家更感兴趣。在这种情况下,ChatGPT 可能无法在没有任何帮助的情况下提供正确答案。
例如,让我们问我们的 Pipeline 一个非常小众的问题。
pipe.run({"prompt_builder": {"country": "the Republic of Rose Island"}})
# returns {
# "llm": {
# "replies": [
# 'The official language of the Republic of Rose Island was Italian.'
# ]
# }
# }
答案是一个有根据的猜测,但并不准确:尽管它位于意大利领海之外,但根据 维基百科,这个短暂存在的微型国家的官方语言是世界语。
我们如何让 ChatGPT 正确回答这样的问题?一种方法是让它“作弊”,将其作为问题的一部分提供答案。事实上,PromptBuilder 的设计正是为了满足这种用例。
这是我们新的、更高级的提示
Given the following information, answer the question.
Context: {{ context }}
Question: {{ question }}
让我们用这个提示构建一个新的 Pipeline!
context_template = """
Given the following information, answer the question.
Context: {{ context }}
Question: {{ question }}
"""
language_template = "What's the official language of {{ country }}?"
pipe = Pipeline()
pipe.add_component("context_prompt", PromptBuilder(template=context_template))
pipe.add_component("language_prompt", PromptBuilder(template=language_template))
pipe.add_component("llm", OpenAIGenerator(api_key=api_key))
pipe.connect("language_prompt", "context_prompt.question")
pipe.connect("context_prompt", "llm")
pipe.run({
"context_prompt": {"context": "Rose Island had its own government, currency, post office, and commercial establishments, and the official language was Esperanto."}
"language_prompt": {"country": "the Republic of Rose Island"}
})
# returns {
# "llm": {
# "replies": [
# 'The official language of the Republic of Rose Island is Esperanto.'
# ]
# }
# }
让我们看看我们 Pipeline 的图
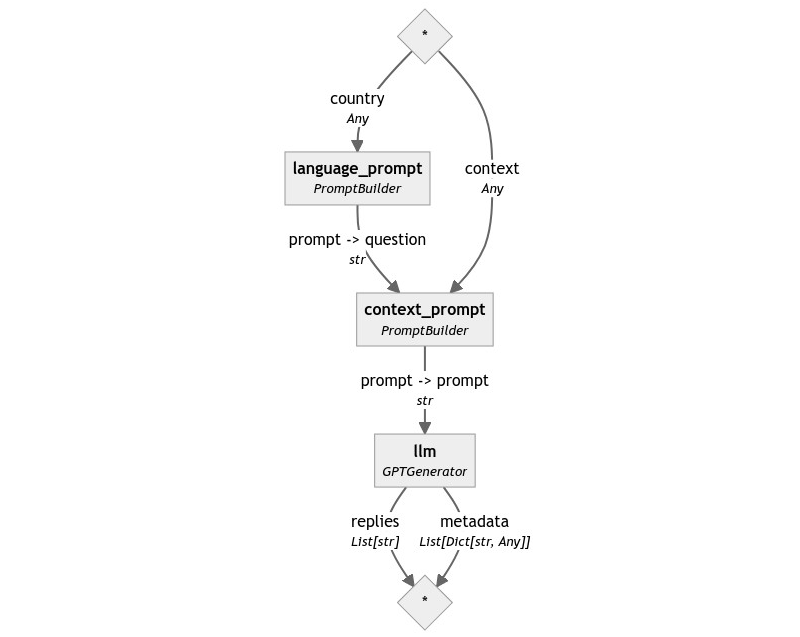
PromptBuilder 之美在于其灵活性。它允许用户将实例链接在一起,以构建复杂的提示,这些提示由更简单的模式组成:例如,我们将第一个 PromptBuilder 的输出用作第二个提示中 question 的值。
然而,在这个特定的场景中,我们可以通过将两个提示合并成一个来构建一个更简单的系统。
Given the following information, answer the question.
Context: {{ context }}
Question: What's the official language of {{ country }}?
使用这个新提示,生成的 Pipeline 又变得与我们的第一个非常相似。
template = """
Given the following information, answer the question.
Context: {{ context }}
Question: What's the official language of {{ country }}?
"""
pipe = Pipeline()
pipe.add_component("prompt_builder", PromptBuilder(template=template))
pipe.add_component("llm", OpenAIGenerator(api_key=api_key))
pipe.connect("prompt_builder", "llm")
pipe.run({
"prompt_builder": {
"context": "Rose Island had its own government, currency, post office, and commercial establishments, and the official language was Esperanto.",
"country": "the Republic of Rose Island"
}
})
# returns {
# "llm": {
# "replies": [
# 'The official language of the Republic of Rose Island is Esperanto.'
# ]
# }
# }
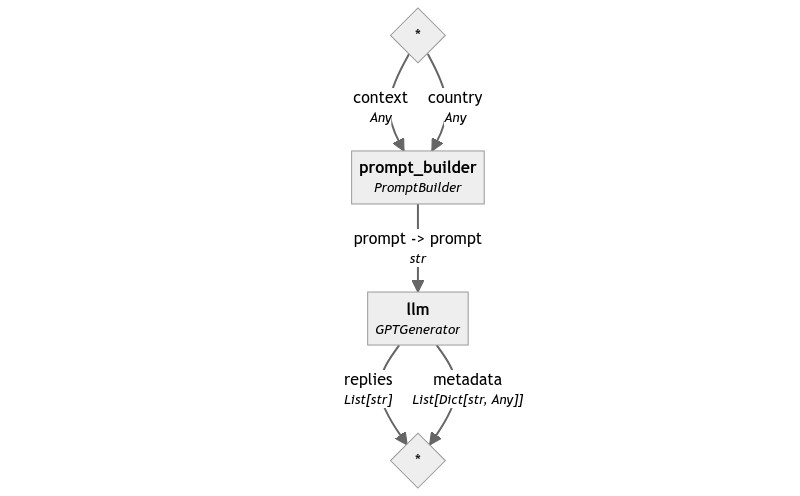
检索上下文
到目前为止,我们一直在玩弄提示,但根本问题仍未得到解答:我们如何获得用户所询问问题的正确文本片段?我们不能期望这些信息作为输入的一部分:我们需要我们的系统能够独立地获取这些信息,仅基于查询。
值得庆幸的是,从大型 语料库(一个技术术语,指大量数据,通常是文本)中检索相关信息是 Haystack 从一开始就擅长的任务:执行此任务的组件称为 Retrievers(检索器)。
检索可以在不同的数据源上执行:首先,让我们假设我们正在本地数据库中搜索数据,这是大多数 Retriever 所面向的用例。
让我们创建一个小型本地数据库来存储一些欧洲国家的信息。Haystack 提供了一个适合这些小型演示的便捷对象:InMemoryDocumentStore。这个文档存储在底层基本上就是一个 Python 字典,但它提供了与更强大的数据存储和向量存储(如 Elasticsearch 或 ChromaDB)完全相同的 API。请注意,该对象被称为“Document Store”,而不是简单地“datastore”,因为它存储的是 Haystack 的 Document 对象:一个小型数据类,有助于其他组件理解它们接收到的数据。
所以,让我们初始化一个 InMemoryDocumentStore 并向其中写入一些 Documents。
from haystack.dataclasses import Document
from haystack.document_stores.in_memory import InMemoryDocumentStore
documents = [
Document(content="German is the the official language of Germany."),
Document(content="The capital of France is Paris, and its official language is French."),
Document(content="Italy recognizes a few official languages, but the most widespread one is Italian."),
Document(content="Esperanto has been adopted as official language for some microstates as well, such as the Republic of Rose Island, a short-lived microstate built on a sea platform in the Adriatic Sea.")
]
docstore = InMemoryDocumentStore()
docstore.write_documents(documents=documents)
docstore.filter_documents()
# returns [
# Document(content="German is the the official language of Germany."),
# Document(content="The capital of France is Paris, and its official language is French."),
# Document(content="Esperanto has been adopted as official language for some microstates as well, such as the Republic of Rose Island, a short-lived microstate built on a sea platform in the Adriatic Sea."),
# Document(content="Italy recognizes a few official languages, but the most widespread one is Italian."),
# ]
文档存储设置好后,我们就可以初始化一个检索器了。在 Haystack 2.0 中,每个文档存储都附带自己高度优化的检索器集合:InMemoryDocumentStore 提供了两个,一个基于 BM25 排名,一个基于嵌入相似度。
让我们从基于 BM25 的检索器开始,它稍微容易设置一些。首先,让我们单独使用它来查看它的行为。
from haystack.components.retrievers.in_memory import InMemoryBM25Retriever
retriever = InMemoryBM25Retriever(document_store=docstore)
retriever.run(query="Rose Island", top_k=1)
# returns [
# Document(content="Esperanto has been adopted as official language for some microstates as well, such as the Republic of Rose Island, a short-lived microstate built on a sea platform in the Adriatic Sea.")
# ]
retriever.run(query="Rose Island", top_k=3)
# returns [
# Document(content="Esperanto has been adopted as official language for some microstates as well, such as the Republic of Rose Island, a short-lived microstate built on a sea platform in the Adriatic Sea.")
# Document(content="Italy recognizes a few official languages, but the most widespread one is Italian."),
# Document(content="The capital of France is Paris, and its official language is French."),
# ]
我们看到 InMemoryBM25Retriever 接受几个参数。query 是我们想要查找相关文档的问题。对于 BM25,该算法只搜索完全匹配的单词。结果检索器非常快,但它无法优雅地处理错误:它无法处理拼写错误、同义词或对实体的描述。例如,对于查询“felines”(猫科动物),包含“cat”(猫)一词的文档将被视为不相关。
top_k 控制返回的文档数量。我们可以看到,在第一个示例中,只返回了一个文档,这是正确的。在第二个示例中,当 top_k = 3 时,即使只有一个文档是相关的,检索器也会被强制返回三个文档,因此它会随机选择另外两个。尽管行为不是最优的,但 BM25 保证如果存在与查询相关的文档,它将位于第一个位置,所以目前我们可以将其与 top_k=1 一起使用。
检索器还接受一个 filters 参数,该参数允许您在检索之前预先过滤文档。这是一项强大的技术,在复杂的应用程序中非常有用,但目前我们用不到它。我将在后续的文章中更详细地讨论这个话题,称为元数据过滤。
现在,让我们在我们的 Pipeline 中利用这个新组件。
我们的第一个 RAG Pipeline
检索器不返回单个字符串,而是返回一个 Document 列表。我们如何将这些对象的原始内容放入我们的提示模板中?
是时候利用 Jinja 强大的语法来为我们处理一些解包工作了。
Given the following information, answer the question.
Context:
{% for document in documents %}
{{ document.content }}
{% endfor %}
Question: What's the official language of {{ country }}?
请注意,尽管对于 Python 程序员来说,语法可能有点陌生,但模板所做的事情是基本清楚的:它迭代文档,并为每个文档渲染其 content 字段。
准备好所有这些组件后,我们最终可以把它们组合在一起。
template = """
Given the following information, answer the question.
Context:
{% for document in documents %}
{{ document.content }}
{% endfor %}
Question: What's the official language of {{ country }}?
"""
pipe = Pipeline()
pipe.add_component("retriever", InMemoryBM25Retriever(document_store=docstore))
pipe.add_component("prompt_builder", PromptBuilder(template=template))
pipe.add_component("llm", OpenAIGenerator(api_key=api_key))
pipe.connect("retriever", "prompt_builder.documents")
pipe.connect("prompt_builder", "llm")
pipe.run({
"retriever": {"query": country},
"prompt_builder": {
"country": "the Republic of Rose Island"
}
})
# returns {
# "llm": {
# "replies": [
# 'The official language of the Republic of Rose Island is Esperanto.'
# ]
# }
# }
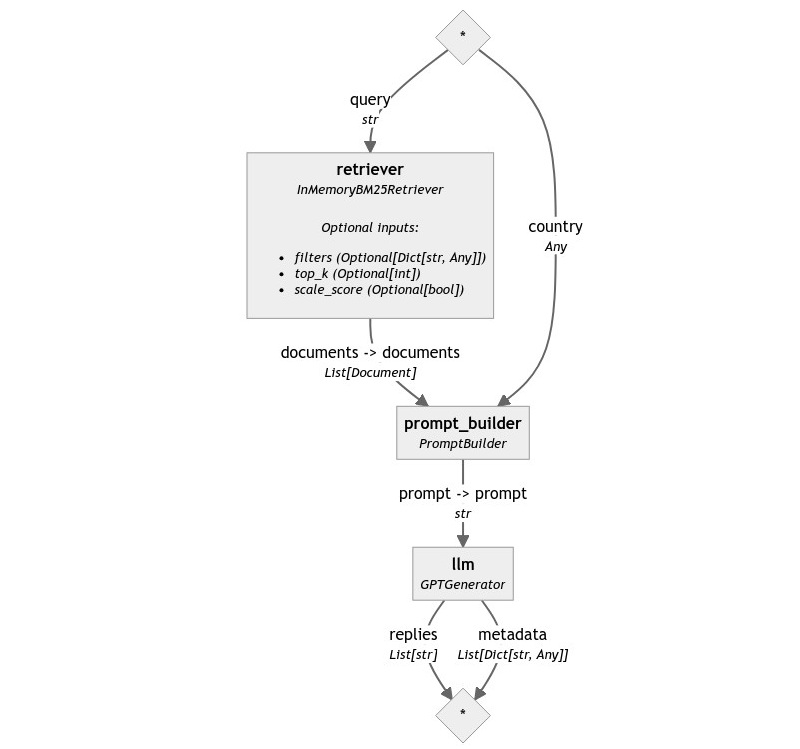
恭喜!我们已经构建了第一个名副其实的 RAG Pipeline。
扩展:Elasticsearch
那么,我们现在已经有了运行的原型。将此系统扩展到生产工作量需要付出什么努力?
当然,将系统扩展到生产就绪状态并非易事,无法在一两句话内解决。不过,我们可以开始这段旅程,从一个可以立即改进的组件开始:文档存储。
InMemoryDocumentStore 显然是一个玩具实现:Haystack 支持性能更好的文档存储,如 Elasticsearch、ChromaDB 和 Marqo。由于我们构建的应用程序使用了 BM25 检索器,让我们选择 Elasticsearch 作为我们生产就绪的文档存储。
如何在我们的 Pipeline 中使用 Elasticsearch?只需将 InMemoryDocumentStore 和 InMemoryBM25Retriever 替换为它们的 Elasticsearch 对应项即可,它们的 API 几乎相同。
首先,让我们创建文档存储:我们需要一个稍微复杂一些的设置来连接到 Elasticsearch 后端。在此示例中,我们使用 Elasticsearch 版本 8.8.0,但任何 Elasticsearch 8 版本都应该有效。
from elasticsearch_haystack.document_store import ElasticsearchDocumentStore
host = os.environ.get("ELASTICSEARCH_HOST", "https://:9200")
user = "elastic"
pwd = os.environ["ELASTICSEARCH_PASSWORD"] # You need to provide this value
docstore = ElasticsearchDocumentStore(
hosts=[host],
basic_auth=(user, pwd),
ca_certs="/content/elasticsearch-8.8.0/config/certs/http_ca.crt"
)
现在,让我们再次将这四个文档写入存储。在这种情况下,我们指定了重复策略,因此如果文档已存在,它们将被覆盖。所有 Haystack 文档存储都提供三种处理重复项的策略:FAIL(默认)、SKIP 和 OVERWRITE。
from haystack.document_stores import DuplicatePolicy
documents = [
Document(content="German is the the official language of Germany."),
Document(content="The capital of France is Paris, and its official language is French."),
Document(content="Italy recognizes a few official languages, but the most widespread one is Italian."),
Document(content="Esperanto has been adopted as official language for some microstates as well, such as the Republic of Rose Island, a short-lived microstate built on a sea platform in the Adriatic Sea.")
]
docstore.write_documents(documents=documents, policy=DuplicatePolicy.OVERWRITE)
完成此操作后,我们就可以构建与之前相同的 Pipeline,但使用 ElasticsearchBM25Retriever。
from elasticsearch_haystack.bm25_retriever import ElasticsearchBM25Retriever
template = """
Given the following information, answer the question.
Context:
{% for document in documents %}
{{ document.content }}
{% endfor %}
Question: What's the official language of {{ country }}?
"""
pipe = Pipeline()
pipe.add_component("retriever", ElasticsearchBM25Retriever(document_store=docstore))
pipe.add_component("prompt_builder", PromptBuilder(template=template))
pipe.add_component("llm", OpenAIGenerator(api_key=api_key))
pipe.connect("retriever", "prompt_builder.documents")
pipe.connect("prompt_builder", "llm")
pipe.draw("elasticsearch-rag-pipeline.png")
country = "the Republic of Rose Island"
pipe.run({
"retriever": {"query": country},
"prompt_builder": {"country": country}
})
# returns {
# "llm": {
# "replies": [
# 'The official language of the Republic of Rose Island is Esperanto.'
# ]
# }
# }
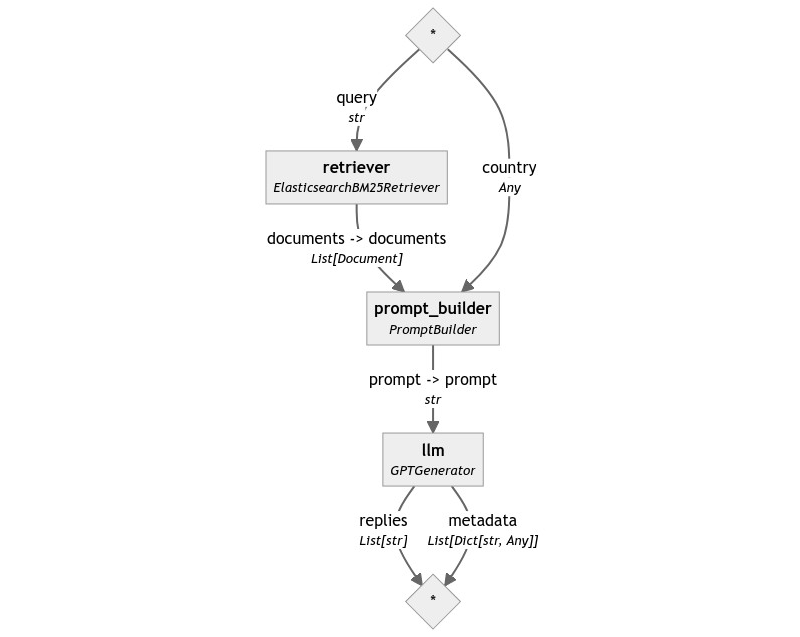
就是这样!我们现在正在一个生产就绪的 Elasticsearch 实例上运行相同的 Pipeline。
总结
在本篇文章中,我们详细介绍了使 Haystack RAG 应用程序成为可能的一些基本组件:Generators、PromptBuilder 和 Retrievers。我们已经看到了它们如何单独使用,以及如何将它们组合成 Pipelines 以实现相同目标。最后,我们尝试了一些(非常早期的!)功能,这些功能使 Haystack 2.0 能够投入生产,并可以从一个简单的演示中以最小的更改进行扩展。
然而,这只是我们 RAG 之旅的开始。敬请期待!
