
使用 Haystack 和 NVIDIA NeMo Retriever 通过文档重排序优化 RAG 应用
在检索增强生成 (RAG) 应用中,检索到的文档质量在提供准确有意义的响应方面起着至关重要的作用。但是,当嵌入相似性不足以准确排序参考文档时会发生什么?这就是**重排序**发挥作用的地方。
什么是重排序?
重排序是指根据每个文档与查询的匹配程度为其分配相关性分数。重排序会重新排序检索到的文档,以确保最相关的结果排在最前面。这一点很重要,因为检索阶段侧重于召回(广泛考虑相关性),而重排序则“微调”结果以提高精度。
重排序示例
考虑一个查询,例如“保护 REST API 的最佳实践是什么?” 检索模型可能会返回一个包含以下文档的排名列表:
- REST API:实践指南
- 最佳 REST API 框架
- 关于如何保护 REST API 的详细步骤
- 公共 API 与私有 API:挑战与限制
- REST API 架构原则
虽然这些文档似乎都与 REST API 的主题相关,但包含具体安全步骤的文档(文档 3)理想情况下应排在第一位。仅使用嵌入相似性,文档得分可能会过度依赖常见词语——例如,文档 1 包含“REST API”和与“实践”相似的词语,而文档 2 也包含查询中的“最佳”一词。重排序器的使用应能提供更好的文档评分,克服这些缺陷,从而改进检索管道。
为什么重排序在 RAG 系统中至关重要
向 RAG 管道添加重排序组件可以同时增强**召回率**(检索相关文档)和**精确度**(选择最相关的文档)。重排序器通常使用经过微调的**LLM**,重新排序检索到的文档块,以确保最相关的文档出现在顶部,从而提高检索过程的准确性。
通过优先处理正确的文档,重排序增加了为 LLM 提供最佳上下文的可能性,从而提高了生成响应的质量。例如,在一个用户寻求特定技术信息的应用程序中,**重排序模型可确保高度相关的内容优先显示**,防止不太有用的结果稀释响应质量。当提供响应的 LLM 的上下文窗口有限,或者当我们的目标是优化其推理过程以提高速度和成本效益时,这一点尤其重要。
重排序在**混合检索**设置中尤其有价值,在这种设置中,文档块来自不同的数据存储或不同的检索方法(例如,稀疏、密集或基于关键字的)。每种方法对相关性的排名可能不同,但重排序可以带来一致性,无论检索方法如何。在混合设置中,它可以确保提供给 LLM 的最终文档集反映了查询的真正语义相关性,而不是被单一检索方法的偏差所主导。
检索和重排序的评估指标
根据目的,可以使用许多指标来评估 RAG 管道,例如语义答案相似度或忠实度。在管道中使用重排序器时,评估不仅要评估检索性能,还要评估重排序器如何优化返回结果的顺序。
- 检索性能
召回率反映了检索操作的成功程度,检查检索了多少真实文档。单次命中召回率表示在结果中至少检索到一个相关文档的次数,多次命中召回率衡量所有相关文档出现在顶部结果中的次数。
- 重排序性能
为了衡量重排序模型对文档块的排序效果,我们可以使用**平均倒数排名 (MRR)** 和**归一化折扣累积增益 (NDCG)**。MRR 反映了相关文档的靠前程度,而 NDCG 则评估了整个排名的质量。结合使用,它们可以在需要少量或大量上下文的情况下提供见解。
| 召回率@5(单次命中) | 召回率@5(多次命中) | 精确度@5 | MRR@5 | NDCG@5 | |
|---|---|---|---|---|---|
| 检索器 (top_k=100) | 0.818 | 0.650 | 0.635 | 0.652 | 0.584 |
| 重排序器 (top_k=5) | 0.884 | 0.718 | 0.692 | 0.708 | 0.643 |
| 重排序器改进 | 6.60% | 6.80% | 5.69% | 5.59% | 5.90% |
表 1 - HotpotQA 数据集的小子集上的检索和重排序评估分数。对于评估,使用了以下 NVIDIA NeMo Retriever 微服务:用于检索的nvidia/llama-3.2-nv-embedqa-1b-v2,以及用于重排序的nvidia/llama-3.2-nv-rerankqa-1b-v2。
该表揭示了添加重排序器以增强检索输出的影响
- 召回率提升:重排序器同时提升了单次命中和多次命中在召回率@5 上的表现,其中多次命中召回率提升最大(+6.80%)。当需要多个相关文档以获得全面的上下文时,这种改进至关重要,因为重排序器成功地在顶部结果中浮现了更多相关文档。
- 重排序质量:MRR@5 和 NDCG@5 等指标表明重排序性能显著提高。MRR 的上升(+5.59%)表明相关文档提前出现,而 NDCG 的增加(+5.90%)表明整体排名质量得到改善,使得从结果顶部检索相关信息更加容易。
总而言之,这项分析表明,重排序模型显着提高了检索和重排序指标,并强调了其在 RAG 管道中有效浮现相关内容的价值。
有关此评估使用的详细代码,请参阅 Cookbook:评估重排序增强的检索管道
介绍 NVIDIA NIM
NeMo Retriever 微服务基于NVIDIA NIM 构建,NVIDIA NIM 是 NVIDIA AI Enterprise 软件平台的一部分。NVIDIA NIM 是一系列容器化微服务,旨在优化最先进 AI 模型的推理。容器使用各种组件来提供 AI 模型,并通过标准 API 暴露它们。模型使用 NVIDIA TensorRT 或 NVIDIA TensorRT-LLM(取决于模型类型)进行优化,自动应用量化、模型分发、优化内核/运行时以及 inflight 或连续批处理等过程,如有需要还可以进一步优化。详细了解NIM。
Haystack 提供 4 个与 NVIDIA NIM 连接的组件
- NvidiaGenerator:使用 LLM NIM 进行文本生成。
- NvidiaDocumentEmbedder:使用 NVIDIA NeMo Retriever 嵌入 NIM 微服务进行文档嵌入。
- NvidiaTextEmbedder:使用 NVIDIA NeMo Retriever 嵌入 NIM 微服务进行查询嵌入。
- (新增)NvidiaRanker:使用 NVIDIA NeMo Retriever 重排序 NIM 微服务进行文档块重排序。
开始使用 NVIDIA NIM
要集成 NVIDIA NIM,您可以访问 NVIDIA API catalog 中的预训练模型,或将 NVIDIA NIM 直接部署在您自己的基础设施上以增强控制和可扩展性。在此示例中,我们将重点关注使用 NVIDIA 托管的模型。
- 获取 API 密钥:在 NVIDIA API catalog 上注册,以获取具有免费积分的 API 密钥,用于访问预训练模型。
- 使用 NVIDIA 托管的模型:集成托管在 NVIDIA API catalog 上的 NVIDIA NIM 模型,以实现无缝访问。
了解如何在在 K8s 上使用 NVIDIA NIM 和 Haystack 构建 RAG 应用中将 NIM 部署到您自己的基础设施上。
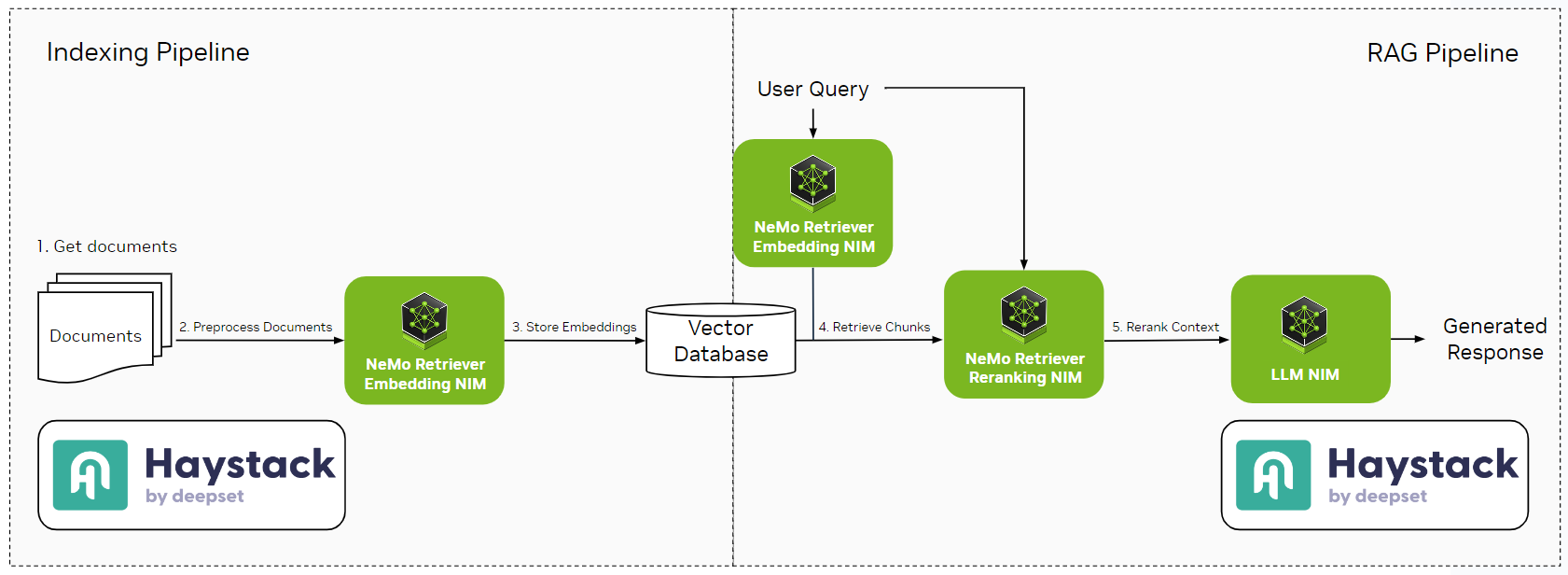
使用 NVIDIA Nemo Retriever 构建带有重排序的 Haystack RAG 管道
增强的检索
对于检索,使用 nvidia/llama-3.2-nv-rerankqa-1b-v2 模型初始化 NeMo Retriever 微服务 `NvidiaRanker`,并使用 nvidia/llama-3.2-nv-embedqa-1b-v2 初始化 `NvidiaTextEmbedder`。我们将设置检索器的 `top_k` 值为 30,重排序器的 `top_k` 值为 5。因此,我们将检索 30 个文档,但仅将 5 个最相关的文档作为上下文传递给 LLM。
from haystack_integrations.components.embedders.nvidia import NvidiaTextEmbedder
from haystack_integrations.components.generators.nvidia import NvidiaGenerator
from haystack_integrations.components.rankers.nvidia import NvidiaRanker
from haystack.components.retrievers import InMemoryEmbeddingRetriever
embedder = NvidiaTextEmbedder(model="nvidia/llama-3.2-nv-embedqa-1b-v2",
api_url="https://integrate.api.nvidia.com/v1")
retriever = InMemoryEmbeddingRetriever(document_store=document_store, top_k=30)
reranker = NvidiaRanker(
model="nvidia/llama-3.2-nv-rerankqa-1b-v2",
top_k=5
)
生成
定义基本提示,并使用 `meta/llama3-70b-instruct` 模型作为生成器初始化 `NvidiaGenerator`
from haystack.components.builders import PromptBuilder
from haystack_integrations.components.generators.nvidia import NvidiaGenerator
prompt = """Answer the question given the context.
Question: {{ query }}
Context:
{% for document in documents %}
{{ document.content }}
{% endfor %}
Answer:
"""
prompt_builder = PromptBuilder(template=prompt)
generator = NvidiaGenerator(
model="meta/llama3-70b-instruct",
model_arguments={
"max_tokens": 1024
}
)
构建增强的 RAG 管道
将所有组件整合在一起并建立相关的连接。
from haystack import Pipeline
enhanced_rag = Pipeline()
enhanced_rag.add_component("embedder", embedder)
enhanced_rag.add_component("retriever", retriever)
enhanced_rag.add_component("reranker", reranker)
enhanced_rag.add_component("prompt_builder", prompt_builder)
enhanced_rag.add_component("generator", generator)
enhanced_rag.connect("embedder.embedding", "retriever.query_embedding")
enhanced_rag.connect("retriever", "reranker")
enhanced_rag.connect("reranker.documents", "prompt_builder.documents")
enhanced_rag.connect("prompt_builder", "generator")
运行管道
为了测试我们的管道,我们将使用HotpotQA 数据集中的问题
question = "A medieval fortress in Dirleton, East Lothian, Scotland borders on the south side of what coastal area?" # correct answer is "Yellowcraig"
enhanced_rag.run({
"embedder": {"text": question},
"reranker": {"query": question},
"prompt_builder": {"query": question}
})
{'embedder': {'meta': {'usage': {'prompt_tokens': 26, 'total_tokens': 26}}},
'generator': {'replies': ['The answer is Yellowcraig. According to the context, Dirleton Castle borders on the south side of the Yellowcraig coastal area.'],
'meta': [{'role': 'assistant',
'usage': {'prompt_tokens': 503,
'total_tokens': 532,
'completion_tokens': 29},
'finish_reason': 'stop'}]}}
对于这个问题,增强管道的响应是“答案是 Yellowcraig。根据上下文,Dirleton Castle 位于 Yellowcraig 海岸地区的南部。”。现在,让我们创建一个没有重排序的基本 RAG 管道并比较结果。
无重排序的基本 RAG 管道
prompt = """Answer the question given the context.
Question: {{ query }}
Context:
{% for document in documents %}
{{ document.content }}
{% endfor %}
Answer:
"""
rag = Pipeline()
rag.add_component("embedder", NvidiaTextEmbedder(model="nvidia/llama-3.2-nv-embedqa-1b-v2",
api_url="https://integrate.api.nvidia.com/v1"))
rag.add_component("retriever", InMemoryEmbeddingRetriever(document_store=document_store, top_k=5))
rag.add_component("prompt_builder", PromptBuilder(template=prompt))
rag.add_component("generator", NvidiaGenerator(
model="meta/llama3-70b-instruct",
model_arguments={
"max_tokens": 1024
}
))
rag.connect("embedder.embedding", "retriever.query_embedding")
rag.connect("retriever", "prompt_builder.documents")
rag.connect("prompt_builder", "generator")
question = "A medieval fortress in Dirleton, East Lothian, Scotland borders on the south side of what coastal area?" # correct answer is "Yellowcraig"
rag.run({
"embedder": {"text": question},
"prompt_builder": {"query": question}
})
{'embedder': {'meta': {'usage': {'prompt_tokens': 26, 'total_tokens': 26}}},
'generator': {'replies': ['The Firth of Forth.'],
'meta': [{'role': 'assistant',
'usage': {'prompt_tokens': 488,
'total_tokens': 496,
'completion_tokens': 8},
'finish_reason': 'stop'}]}}
基本管道的响应是“*福斯湾*。”,它在上下文中被提及,但不是正确的答案。这表明仅靠检索器不足以检索最相关的文档,这支持了重排序器在召回率方面的改进。
结论
在这篇博文中,我们探讨了向 RAG 管道添加重排序模型所产生的重大影响。仅使用检索时,返回的文档可能基于嵌入相似性与查询大致匹配,但无法保证上下文相关性的排序。这可能导致响应缺乏特异性,正如基本 RAG 管道示例所示,该示例返回了“*福斯湾。*”这个答案,而不是正确的“*Yellowcraig*”,原因是文档排名不佳。
通过使用 `NvidiaRanker` 集成 NeMo Retriever `nvidia/llama-3.2-nv-rerankqa-1b-v2` 模型,增强的 RAG 管道优先处理了最具上下文相关性的文档,提高了响应的整体精度。通过重排序,**召回率@5(多次命中)** 和 **NDCG@5** 等指标显示出显著的改进,这表明相关文档不仅更频繁地出现在前几位结果中,而且在列表中的位置也更靠前,从而增强了 LLM 访问高质量上下文以进行准确生成的能力。
总而言之,通过添加基于 NVIDIA NIM 构建的 NeMo Retriever 重排序功能,RAG 管道实现了更好的文档排序、更相关的上下文以及更高的响应准确性——这证明了重排序器在构建健壮的、实际的 RAG 应用中的重要作用。