
使用NVIDIA NIM和Haystack在K8s上构建RAG应用程序
检索增强生成(RAG)系统将生成式AI与信息检索相结合,以生成有上下文的答案。大规模构建可靠且高性能的RAG应用程序是一个挑战。在这篇博文中,我们将展示如何使用Haystack和NVIDIA NIM来创建一个易于部署/维护、标准化且面向企业的RAG解决方案,该解决方案可以运行在本地以及云原生环境中。这个方案适用于云、本地甚至隔离环境。
关于Haystack
Haystack,由deepset开发,是一个开源框架,用于构建生产级的LLM应用程序、RAG管道和最先进的搜索系统,这些系统可以智能地处理大型文档集合。
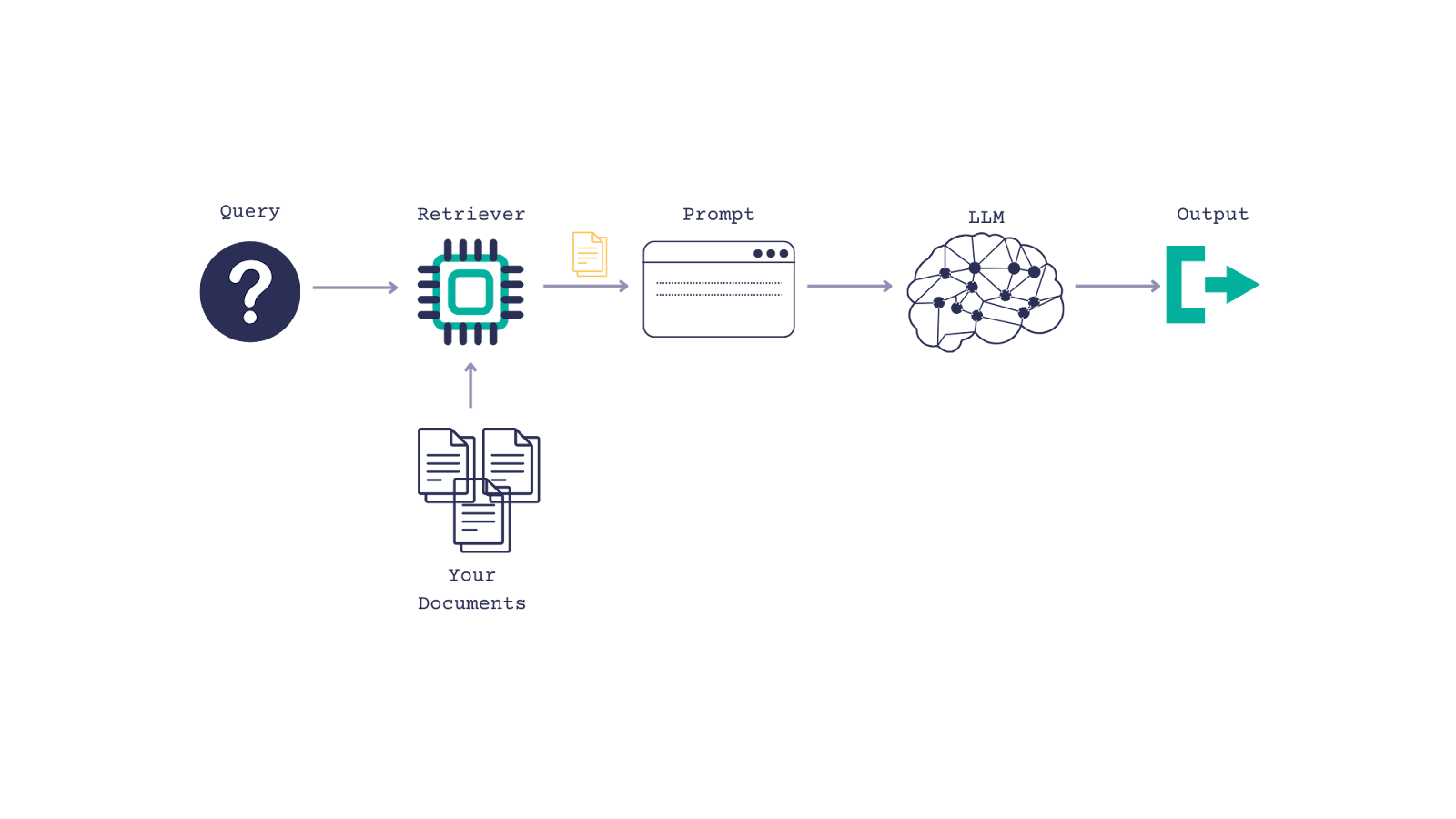
Haystack不断增长的社区集成生态系统提供了评估、监控、转录、数据摄取等工具。NVIDIA Haystack集成允许在Haystack管道中使用NVIDIA模型和NIM,从而可以灵活地从云原型设计转向本地部署。
关于NVIDIA NIM
NVIDIA NIM是一组容器化的微服务,旨在优化最先进AI模型的推理。该容器使用各种组件来服务AI模型,并通过标准API公开它们。模型使用TensorRT或TensorRT-LLM(取决于模型类型)进行优化,应用量化、模型分布、优化内核/运行时和inflight或连续批处理等过程,如果需要,还可以进行进一步优化。在此处了解更多关于NIM的信息。
本教程展示了如何构建一个Haystack RAG管道,该管道利用托管在NVIDIA API目录上的NIM。然后,我们提供了在Kubernetes环境中为自托管AI基础模型部署NIM的说明。请注意,托管NIM需要NVIDIA AI Enterprise许可证。
构建一个Haystack RAG管道,使用托管在NVIDIA API目录上的NVIDIA NIM
对于RAG管道,Haystack提供了3个可以与NVIDIA NIM连接的组件
- NvidiaGenerator:使用LLM NIM进行文本生成。
- NvidiaDocumentEmbedder:使用NVIDIA NeMo Retriever文本嵌入NIM进行文档嵌入。
-
NvidiaTextEmbedder:使用NVIDIA NeMo Retriever文本嵌入NIM进行查询嵌入。
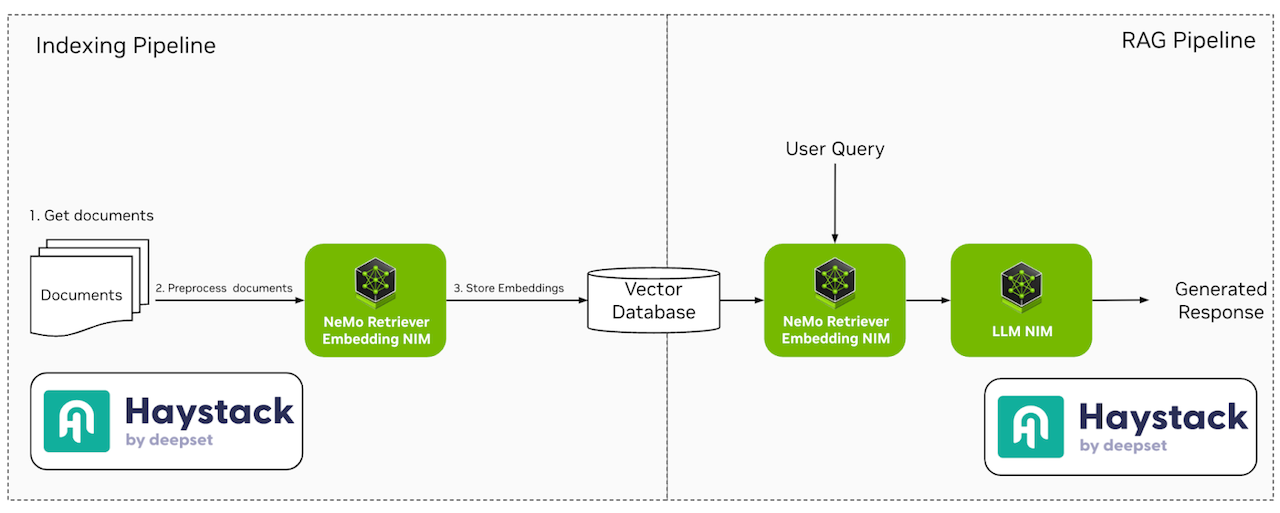
图 1 - 使用NVIDIA NIM的Haystack索引和RAG管道
在本节中,我们提供了用于构建RAG管道的脚本和说明,该管道利用NVIDIA API目录上托管的NIM,这些内容作为GitHub仓库的一部分。我们还提供了一个Jupyter Notebook,用于构建在Kubernetes环境中部署在您基础架构上的NIM的相同RAG管道。
使用Haystack索引管道矢量化文档
我们的索引管道实现可在索引教程中找到。Haystack提供了几个预处理组件,用于文档清理、拆分、嵌入器以及转换器,用于从不同格式的文件中提取数据。在本教程中,我们将把PDF文件存储在QdrantDocumentStore中。NvidiaDocumentEmbedder用于连接托管在NVIDIA API目录上的NIM。下面是如何使用托管在NVIDIA API目录上的snowflake/arctic-embed-l NIM来初始化嵌入器组件的示例。
from haystack.utils.auth import Secret
from haystack_integrations.components.embedders.nvidia import NvidiaDocumentEmbedder
embedder = NvidiaDocumentEmbedder(model="snowflake/arctic-embed-l",
api_url="https://ai.api.nvidia.com/v1/retrieval/snowflake/arctic-embed-l",
batch_size=1)
创建Haystack RAG管道
在我们的示例中,我们将使用NVIDIA NeMo Retriever文本嵌入NIM和LLM NIM创建一个简单的问答RAG管道。对于这个管道,我们使用NvidiaTextEmbedder来嵌入查询以进行检索,并使用NvidiaGenerator来生成响应。下面的示例展示了如何使用托管在NVIDIA API目录上的meta/llama3-70b-instruct LLM NIM来实例化生成器。
generator = NvidiaGenerator(
model="meta/llama3-70b-instruct",
api_url="https://integrate.api.nvidia.com/v1",
model_arguments={
"max_tokens": 1024
}
)
我们使用Haystack管道将这个RAG管道的各种组件连接起来,包括查询嵌入器和LLM生成器。下面是一个RAG管道的示例
from haystack import Pipeline
from haystack.utils.auth import Secret
from haystack.components.builders import PromptBuilder
from haystack_integrations.components.embedders.nvidia import NvidiaTextEmbedder
from haystack_integrations.components.generators.nvidia import NvidiaGenerator
from haystack_integrations.components.retrievers.qdrant import QdrantEmbeddingRetriever
from haystack_integrations.document_stores.qdrant import QdrantDocumentStore
document_store = QdrantDocumentStore(embedding_dim=1024, host="qdrant")
embedder = NvidiaTextEmbedder(model="snowflake/arctic-embed-l",
api_key=Secret.from_env_var("NVIDIA_EMBEDDINGS_KEY"),
api_url="https://ai.api.nvidia.com/v1/retrieval/snowflake/arctic-embed-l")
retriever = QdrantEmbeddingRetriever(document_store=document_store)
prompt = """Answer the question given the context.
Question: {{ query }}
Context:
{% for document in documents %}
{{ document.content }}
{% endfor %}
Answer:"""
prompt_builder = PromptBuilder(template=prompt)
generator = NvidiaGenerator(
model="meta/llama3-70b-instruct",
api_url="https://integrate.api.nvidia.com/v1",
model_arguments={
"max_tokens": 1024
}
)
rag = Pipeline()
rag.add_component("embedder", embedder)
rag.add_component("retriever", retriever)
rag.add_component("prompt", prompt_builder)
rag.add_component("generator", generator)
rag.connect("embedder.embedding", "retriever.query_embedding")
rag.connect("retriever.documents", "prompt.documents")
rag.connect("prompt", "generator")
索引文件并部署Haystack RAG管道
Hayhooks允许在容器化环境中部署RAG管道。在我们的示例中,我们提供了一个docker-compose文件来设置Qdrant数据库和RAG管道。由于我们正在使用托管在NVIDIA API目录上的NIM,我们需要在.env文件中设置NIM的API密钥。以下说明假定您有NVIDIA_API_KEY(用于NvidiaGenerator)和NVIDIA_EMBEDDINGS_KEY(用于NvidiaDocumentEmbedder和NvidiaTextEmbedder)。
执行docker-compose up将启动3个容器:qdrant、hayhooks和qdrant-setup(它将运行我们的索引管道然后停止)。Qdrant数据库将被部署在localhost上,并暴露在端口6333。Qdrant仪表板允许用户在localhost:6333/dashboard查看矢量化文档。
序列化管道
Python中定义的Haystack管道可以通过调用管道对象的dump()方法序列化为YAML,正如我们在RAG管道教程中所展示的那样。下面是YAML定义:
components:
embedder:
...
type: haystack_integrations.components.embedders.nvidia.text_embedder.NvidiaTextEmbedder
generator:
init_parameters:
api_key:
...
type: haystack_integrations.components.generators.nvidia.generator.NvidiaGenerator
prompt:
init_parameters:
template: "Answer the question given the context.\nQuestion: {{ query }}\nContext:\n\
{% for document in documents %}\n {{ document.content }}\n{% endfor %}\n\
Answer:"
type: haystack.components.builders.prompt_builder.PromptBuilder
retriever:
init_parameters:
document_store:
init_parameters:
...
type: haystack_integrations.document_stores.qdrant.document_store.QdrantDocumentStore
...
type: haystack_integrations.components.retrievers.qdrant.retriever.QdrantEmbeddingRetriever
connections:
- receiver: retriever.query_embedding
sender: embedder.embedding
- receiver: prompt.documents
sender: retriever.documents
- receiver: generator.prompt
sender: prompt.prompt
max_loops_allowed: 100
metadata: {}
部署RAG管道
要部署RAG管道,请执行hayhooks deploy rag.yaml,它将默认在https://:1416/rag上公开该管道。然后,您可以访问https://:1416/docs获取API文档并尝试该管道。
对于生产环境,Haystack提供了Helm图表和说明,用于创建使用Kubernetes等容器编排器运行Hayhooks的服务。
在接下来的章节中,我们将展示如何在Kubernetes环境中部署、监控和自动伸缩NIM,以自托管AI基础模型。最后,我们将提供如何在Haystack RAG管道中使用它们的说明。
在Kubernetes集群上自托管NVIDIA NIM
Kubernetes集群环境
在本教程中,设置环境包括一台DGX H100,配备8个H100 GPU,每个GPU拥有80GB内存作为主机,操作系统为Ubuntu。Docker用作容器运行时。Kubernetes使用Minikube部署在其上。为了在Kubernetes中利用GPU,我们使用GPU Operator安装必要的NVIDIA软件组件。
NVIDIA NIM部署
作为此设置的一部分,我们将使用Helm图表将以下NVIDIA NIM部署到Kubernetes集群中
- LLM NIM,使用模型
llama3-8b-instruct - NeMo Retriever文本嵌入NIM,使用模型
nvidia/nv-embedqa-e5-v5
LLM NIM的Helm图表位于GitHub,而NVIDIA NeMo Retriever嵌入NIM的Helm图表可以从NGC注册表获取。图3说明了在运行在DGX H100上的Kubernetes集群上部署NIM。GPU Operator组件通过其Helm图表进行部署,并构成GPU Operator堆栈的一部分。Prometheus和Grafana通过Helm图表进行部署,用于监控Kubernetes集群和NIM。
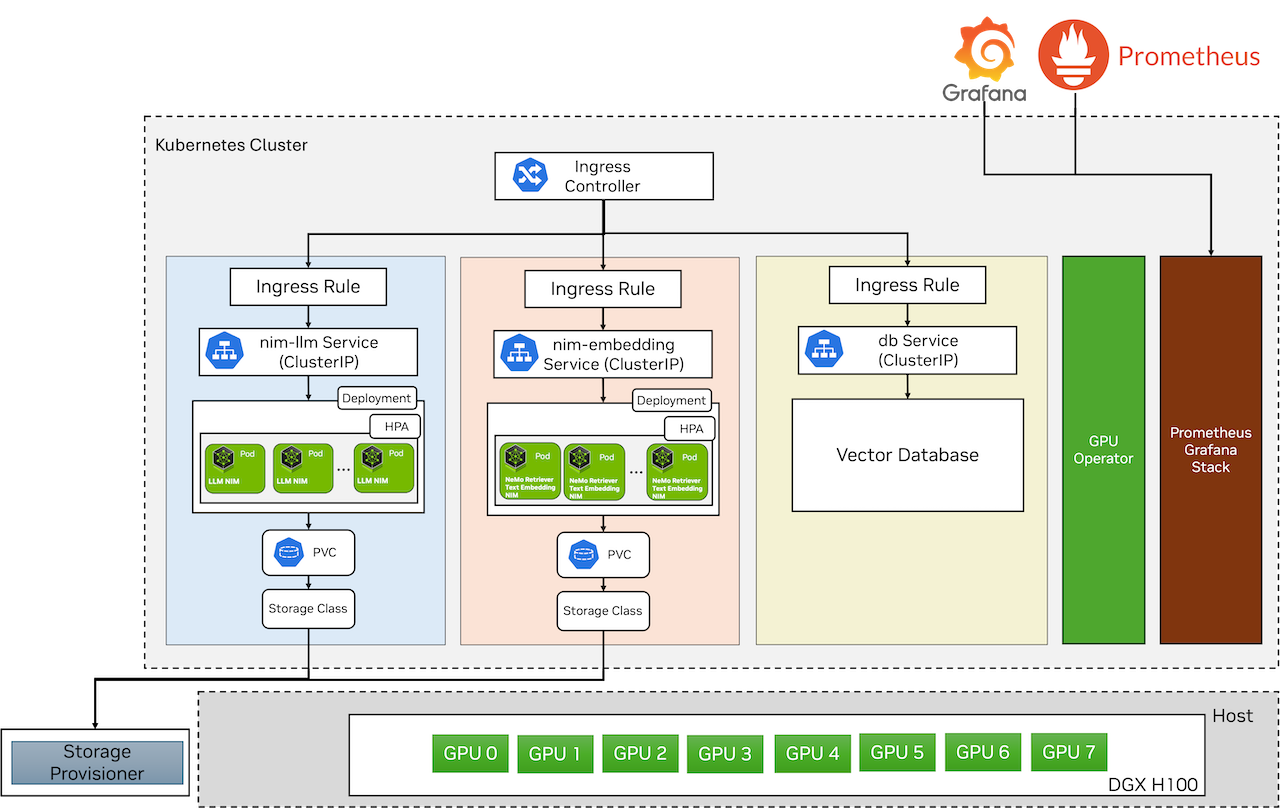
LLM NIM Helm图表包含LLM NIM容器,该容器在pod中运行,并通过持久卷(PV)和持久卷声明(PVC)引用模型。LLM NIM pod使用水平Pod自动伸缩器(HPA)根据自定义指标进行自动伸缩,并通过Kubernetes ClusterIP服务公开。为了访问LLM NIM,我们部署了一个Ingress,并将其暴露在/llm端点。
同样,NeMo Retriever文本嵌入NIM Helm图表包含NeMo Retriever文本嵌入NIM容器,该容器在pod中运行,并通过PV和PVC引用主机上的模型。NeMo Retriever文本嵌入NIM pod也通过HPA进行自动伸缩,并通过Kubernetes ClusterIP服务公开。为了访问NeMo Retriever文本嵌入NIM,我们部署了一个Ingress,并将其暴露在/embedding端点。
用户和其他应用程序可以通过Ingress访问公开的NVIDIA NIM。向量数据库Qdrant使用此Helm图表进行部署。
现在,让我们仔细看看每个NIM的部署过程
LLM NIM部署
- 如果命名空间尚未创建,请创建它
kubectl create namespace nim-llm
- 添加一个Docker注册表密钥,用于从NGC拉取NIM容器,并将
<ngc-cli-api-key>替换为NGC的API密钥。请遵循此链接以在NGC中生成API密钥。
kubectl create secret -n nim-llm docker-registry nvcrimagepullsecret \
--docker-server=nvcr.io \
--docker-username='$oauthtoken' --docker-password=<ngc-cli-api-key>
- 创建一个通用密钥
ngc-api,该密钥用于在NIM容器内拉取模型。
kubectl create secret -n nim-llm generic ngc-api \
--from-literal=NGC_CLI_API_KEY=<ngc-cli-api-key>
- 创建一个
nim-llm-values.yaml文件,内容如下。根据您的环境调整repository和tag值。
image:
# Adjust to the actual location of the image and version you want
repository: nvcr.io/nim/meta/llama3-8b-instruct
tag: 1.0.0
imagePullSecrets:
- name: nvcrimagepullsecret
model:
name: meta/llama3-8b-instruct
ngcAPISecret: ngc-api
persistence:
enabled: true
size: 30Gi
annotations:
helm.sh/resource-policy: keep
statefulSet:
enabled: false
resources:
limits:
nvidia.com/gpu: 1
- 我们假设LLM NIM的Helm图表位于此处:
./nims/helm/nim-llm/。您可以根据Helm图表的位置相应地更改命令。通过运行以下命令来部署LLM NIM
helm -n nim-llm install nim-llm -f ./nims/helm/nim-llm/ nim-llm-values.yaml
- 部署需要几分钟时间来启动容器、下载模型并使其就绪。您可以使用以下命令监视Pod
kubectl get pods -n nim-llm
示例输出
NAME READY STATUS RESTARTS AGE
nim-llm-0 1/1 Running 0 8m21s
- 如果尚未安装Ingress控制器,请安装一个Ingress控制器。然后,创建一个名为
ingress-nim-llm.yaml的文件,内容如下,以创建LLM NIM的Ingress。请确保将主机(此处为nims.example.com)更改为您自己的完全限定域名。
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: nim-llm-ingress
namespace: nim-llm
annotations:
nginx.ingress.kubernetes.io/use-regex: "true"
nginx.ingress.kubernetes.io/rewrite-target: /$2
spec:
rules:
- host: nims.example.com
http:
paths:
- path: /llm(/|$)(.*)
pathType: ImplementationSpecific
backend:
service:
name: nim-llm
port:
number: 8000
使用以下命令部署Ingress
kubectl apply -f ingress-nim-llm.yaml
- 通过发送curl请求进行测试,访问公开的服务(将
nims.example.com替换为您自己的完全限定域名)
curl -X 'POST' 'http://nims.example.com/llm/v1/chat/completions' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"messages": [
{
"content": "You are a polite and respectful chatbot helping people plan a vacation.",
"role": "system"
},
{
"content": "What shall i do in France in one line?",
"role": "user"
}
],
"model": "meta/llama3-8b-instruct",
"temperature": 0.5,
"max_tokens": 1024,
"top_p": 1,
"stream": false
}'
示例输出
{
"id": "cmpl-44c301e7f12942fb830fc53a58e98e2a",
"object": "chat.completion",
"created": 1724399020,
"model": "meta/llama3-8b-instruct",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Indulge in the rich culture and history of France by visiting iconic landmarks like the Eiffel Tower, Notre-Dame Cathedral, and the Louvre Museum, and savor the country's renowned cuisine and wine in charming cities like Paris, Lyon, and Bordeaux."
},
"logprobs": null,
"finish_reason": "stop",
"stop_reason": 128009
}
],
"usage": {
"prompt_tokens": 39,
"total_tokens": 94,
"completion_tokens": 55
}
}
现在,LLM NIM已启动并运行。
NeMo Retriever文本嵌入NIM部署
NeMo Retriever文本嵌入NIM的部署与LLM NIM类似。
-
遵循LLM NIM部署的步骤1-3,但将命令中的命名空间替换为
nim-embedding。 -
创建一个
nim-embedding-values.yaml文件,内容如下。根据您的环境调整repository和tag值。
image:
repository: nvcr.io/nim/nvidia/nv-embedqa-e5-v5
tag: 1.0.0
pullPolicy: IfNotPresent
resources:
limits:
ephemeral-storage: 30Gi
nvidia.com/gpu: 1
memory: 12Gi
cpu: "16000m"
requests:
ephemeral-storage: 3Gi
nvidia.com/gpu: 1
memory: 8Gi
cpu: "4000m"
metrics:
enabled: true
- 通过运行以下命令获取NeMo Retriever文本嵌入NIM Helm图表(您需要创建NGC CLI API密钥,有关如何创建它的信息,请在此查看)
helm fetch https://helm.ngc.nvidia.com/nim/nvidia/charts/text-embedding-nim-1.0.0.tgz --username='$oauthtoken' --password=<NGC_CLI_API_KEY>
- 我们假设NeMo Retriever文本嵌入NIM的Helm图表位于此处:
./nims/helm/nim-embedding/。您可以根据Helm图表的位置相应地更改命令。通过运行以下命令来部署NeMo Retriever文本嵌入NIM
helm -n nim-embedding install nim-embedding -f embedding-nim-values.yaml /nims/helm/nim-embedding/text-embedding-nim-1.0.0.tgz
- 部署需要几分钟时间来启动容器、下载模型并使其就绪。您可以使用以下命令监视Pod
kubectl get pods -n nim-embedding
示例输出
NAME READY STATUS RESTARTS AGE
nemo-embedding-ms-58dd974469-tpdvn 1/1 Running 0 5m
- 创建一个文件
ingress-nim-embedding.yaml,类似于LLM NIM的Ingress,服务名称为nemo-embedding-ms,端口为8080,路径为/embedding(/|$)(.*),如下所示
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: nim-embedding-ingress
namespace: nim-embedding
annotations:
nginx.ingress.kubernetes.io/use-regex: "true"
nginx.ingress.kubernetes.io/rewrite-target: /$2
spec:
rules:
- host: nims.example.com
http:
paths:
- path: /embedding(/|$)(.*)
pathType: ImplementationSpecific
backend:
service:
name: nemo-embedding-ms
port:
number: 8080
- 通过发送curl请求进行测试,访问公开的服务(在下方将
nims.example.com替换为您的完全限定域名)。
curl 'GET' \
'http://nims.example.com/embedding/v1/models' \
-H 'accept: application/json'
示例输出
{
"object": "list",
"data": [
{
"id": "nvidia/nv-embedqa-e5-v5",
"created": 0,
"object": "model",
"owned_by": "organization-owner"
}
]
}
7 您可以通过创建示例文本的嵌入来测试NeMo Retriever文本嵌入NIM,如下所示
curl -X "POST" \
"http://nims.example.com/embedding/v1/embeddings" \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"input": ["Hello world"],
"model": "nvidia/nv-embedqa-e5-v5",
"input_type": "query"
}'
示例输出
{
"object": "list",
"data": [
{
"index": 0,
"embedding": [
-0.0003485679626464844,
-0.017822265625,
0.0262298583984375,
0.0222015380859375,
...
-0.00823974609375
],
"object": "embedding"
}
],
"model": "nvidia/nv-embedqa-e5-v5",
"usage": {
"prompt_tokens": 6,
"total_tokens": 6
}
}
现在,NeMo Retriever文本嵌入NIM已启动并运行。
完成上述过程后,您将获得LLM NIM和NeMo Retriever文本嵌入NIM的API端点。
操作注意事项
监控和自动伸缩对于已部署的NVIDIA NIM至关重要,以确保高效、有效和可靠的运行。监控跟踪性能指标,检测错误,并优化资源利用率,而自动伸缩则动态调整资源以匹配不断变化的工作负载,确保NVIDIA NIM能够应对需求的突然峰值或下降。这使得NVIDIA NIM能够提供准确及时的响应,即使在高负载下也能保持高可用性并优化成本。在本节中,我们将详细介绍部署监控和启用NVIDIA NIM的自动伸缩。
监控
NVIDIA NIM指标使用开源工具Prometheus收集,并使用Grafana仪表板进行可视化。NVIDIA dcgm-exporter是收集GPU遥测数据的首选工具。我们遵循此处的说明来部署Prometheus和Grafana。
可视化NVIDIA NIM指标
LLM NIM
默认情况下,NVIDIA LLM NIM指标由LLM NIM容器在https://:8000/metrics公开。所有公开的指标在此处列出。使用Prometheus ServiceMonitor,它们可以发布到Prometheus并在Grafana中查看。Prometheus ServiceMonitor用于定义应用程序在Kubernetes集群内抓取指标。
- 创建一个名为
service-monitor-nim-llm.yaml的文件,内容如下。
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: nim-llm-sm
namespace: nim-llm
spec:
endpoints:
- interval: 30s
targetPort: 8000
path: /metrics
namespaceSelector:
matchNames:
- nim-llm
selector:
matchLabels:
app.kubernetes.io/name: nim-llm
- 使用以下命令创建一个Prometheus ServiceMonitor
kubectl apply -f service-monitor-nim-llm.yaml
在Prometheus UI的Status -> Targets下,部署后您将看到以下ServiceMonitor。

- 让我们在Prometheus UI上检查一些推理指标。图 4 显示了
request_success_totalNIM指标的堆叠图。
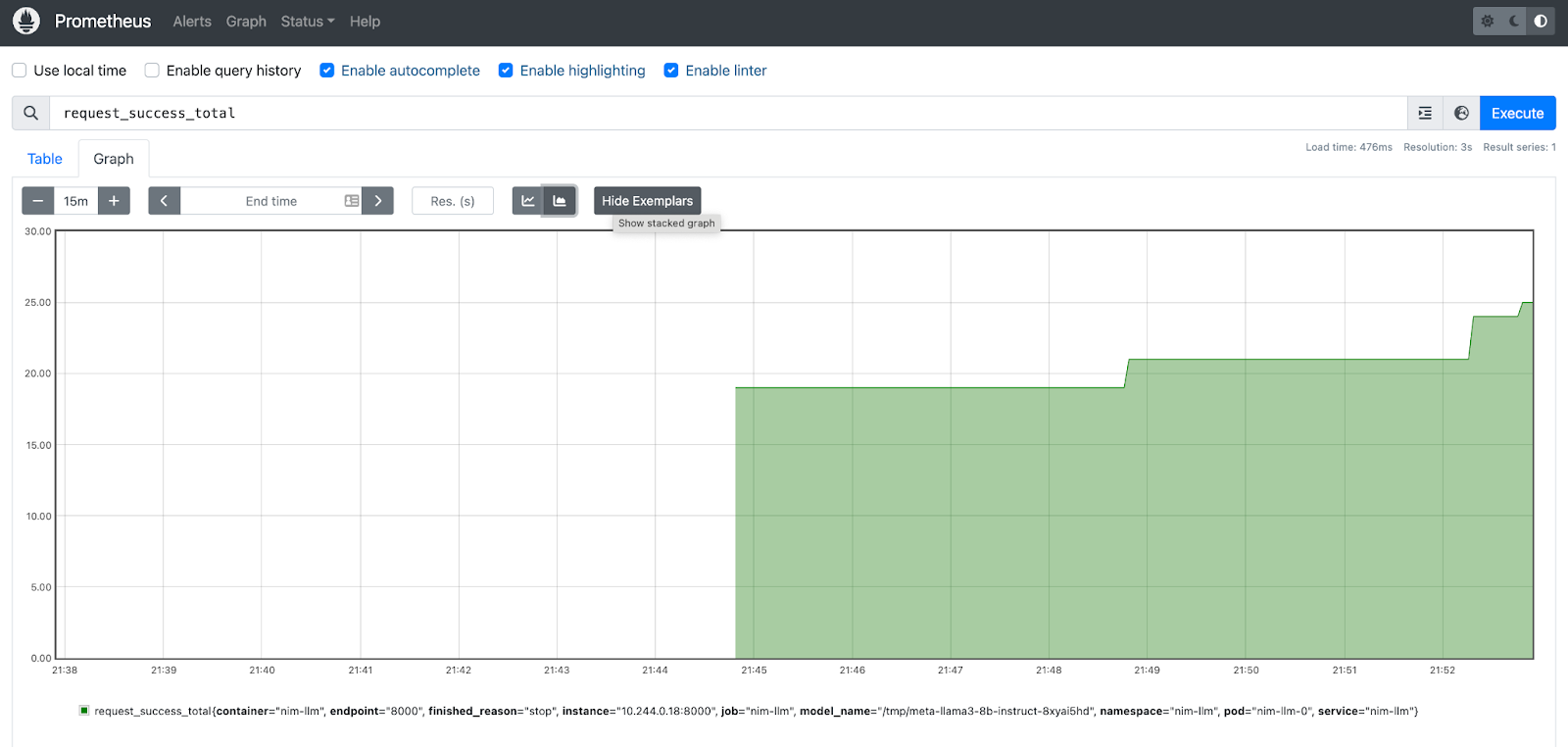
request_success_total指标的图表,表示完成的请求数量。NeMo Retriever文本嵌入NIM
NeMo Retriever文本嵌入NIM在端口8002上公开底层的Triton指标。所有公开的指标在此处列出。我们将创建一个Service Monitor来公开这些指标,以便在Prometheus中发布并在Grafana中可视化。
- 创建一个名为
service-monitor-nim-embedding.yaml的文件,内容如下。
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: nim-embedding-sm
namespace: nim-embedding
spec:
endpoints:
- interval: 30s
targetPort: 8002
path: /metrics
namespaceSelector:
matchNames:
- nim-embedding
selector:
matchLabels:
app.kubernetes.io/name: text-embedding-nim
- 使用以下命令创建一个Prometheus ServiceMonitor
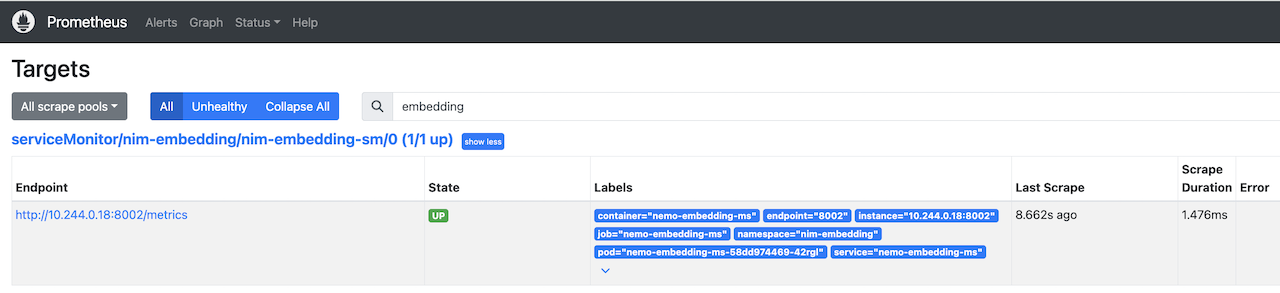
kubectl apply -f service-monitor-nim-embedding.yaml
在Prometheus UI的Status -> Targets下,部署后您将看到以下ServiceMonitor。
- 我们可以在Prometheus UI上查看一些Triton指标。图 5 显示了
nv_inference_count指标的堆叠图。
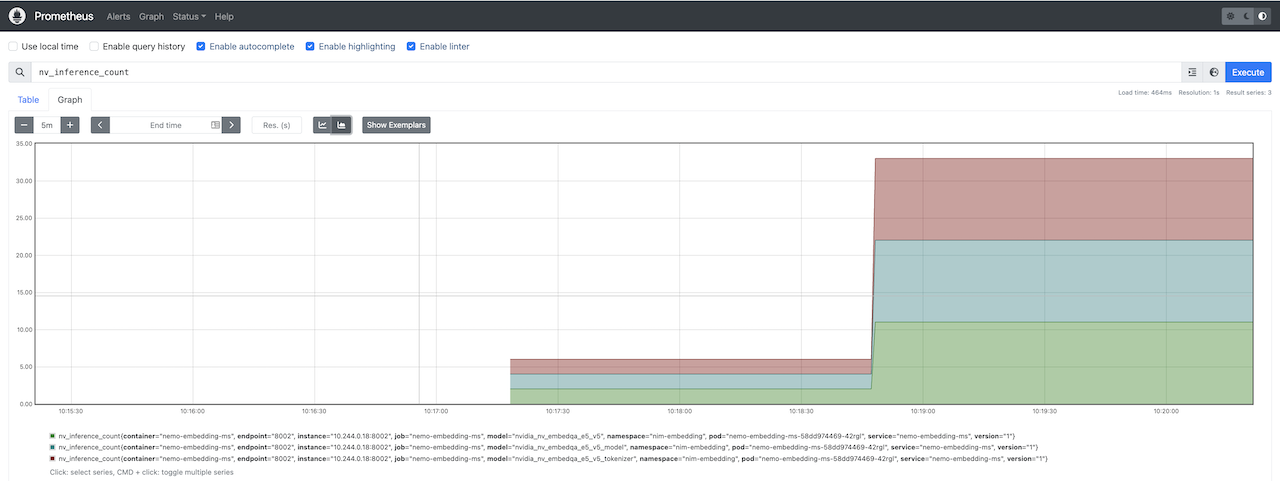
nv_inference_count指标的堆叠图,表示执行的推理数量。自动伸缩NVIDIA NIM
在本教程中,我们使用Kubernetes Horizontal Pod Autoscaler - HPA来调整NIM Pod的伸缩。我们定义了自定义指标来监控每个NVIDIA NIM的平均GPU使用率,HPA使用这些指标来动态调整NIM Pod的数量。请参阅下面的指标定义:
| 指标 | 表达式 |
|---|---|
| nim_llm_gpu_avg | avg by (kubernetes_node, pod, namespace, gpu) (DCGM_FI_DEV_GPU_UTIL{pod=~"nim-llm-.*"}) |
| nim_embedding_gpu_avg | avg by (kubernetes_node, pod, namespace, gpu) (DCGM_FI_DEV_GPU_UTIL{pod=~"nemo-embedding-ms-.*"}) |
这些指标是示例指标,用户应根据自己的环境进行调整。
让我们部署HPA。
- 创建一个名为
prometheus_rule_nims.yaml的文件,内容如下,以创建上述自定义指标的Prometheus规则。根据当前部署的Prometheus实例调整标签(app、其他Prometheus标签)。
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
app: kube-prometheus-stack
app.kubernetes.io/instance: kube-prometheus-stack-1710254997
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/part-of: kube-prometheus-stack
app.kubernetes.io/version: 56.8.2
chart: kube-prometheus-stack-56.8.2
heritage: Helm
release: kube-prometheus-stack-1710254997
name: kube-prometheus-stack-1709-gpu.rules
namespace: prometheus
spec:
groups:
- name: gpu.rules
rules:
- expr: avg by (kubernetes_node, pod, namespace, gpu) (DCGM_FI_DEV_GPU_UTIL{pod=~"nim-llm-.*"})
record: nim_llm_gpu_avg
- expr: avg by (kubernetes_node, pod, namespace, gpu) (DCGM_FI_DEV_GPU_UTIL{pod=~"nemo-embedding-ms-.*"})
record: nim_embedding_gpu_avg
- 通过运行以下命令创建自定义Prometheus记录规则
kubectl apply -f prometheus_rule_nims.yaml
- 在Prometheus UI的
Status -> Rules下,您可以看到上面创建的两个规则,如图 6 所示。

- 安装prometheus-adapter以查询基于上述自定义记录规则的自定义指标,并将其注册到自定义指标API,以便HPA可以获取。在下面的命令中,将
<prometheus-service-name>替换为Kubernetes中Prometheus服务的名称。
helm upgrade --install prometheus-adapter prometheus-community/prometheus-adapter --set prometheus.url="http://<prometheus-service-name>.prometheus.svc.cluster.local"
- 使用以下命令查询自定义指标API,以查看指标是否已注册
kubectl get --raw /apis/custom.metrics.k8s.io/v1beta1 | jq -r . | grep llms
示例输出
"name": "pods/nim_embedding_gpu_avg",
"name": "namespaces/nim_embedding_gpu_avg",
"name": "pods/nim_llm_gpu_avg",
"name": "namespaces/nim_llm_gpu_avg",
- 为两个NVIDIA NIM分别创建了一个HPA定义。在该定义中,我们指定了副本的最小和最大数量、要监控的指标以及该指标的目标值。下面是LLM NIM HPA的定义,您可以使用
nim_embedding_gpu_avg指标为NeMo Retriever文本嵌入NIM创建类似的定义。
LLM NIM HPA文件
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: nim-llm-hpa
namespace: nim-llm
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: nim-llm
minReplicas: 1
maxReplicas: 2
metrics:
- type: Pods
pods:
metric:
name: nim_llm_gpu_avg
target:
type: AverageValue
averageValue: 30
- 使用以下命令创建两个HPA
kubectl apply -f hpa_nim_llm.yaml
kubectl apply -f hpa_nim_embedding.yaml
- 检查HPA的状态
kubectl get hpa -A
示例输出
NAMESPACE NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
nim-embedding nim-embedding-hpa Deployment/nemo-embedding-ms 0/30 1 2 1 80s
nim-llm nim-llm-hpa Deployment/nim-llm 0/30 1 2 1 2m11s
- 向LLM NIM发送一些请求,并查看LLM NIM Pod的伸缩情况,如下所示
NAME READY STATUS RESTARTS AGE
nim-llm-0 1/1 Running 0 3h47m
nim-llm-1 1/1 Running 0 3m30s
此外,图 6 显示了显示LLM NIM伸缩情况的Prometheus图表。
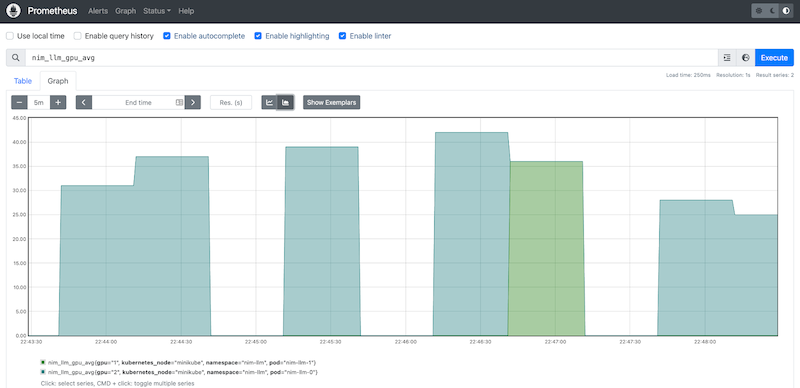
我们现在已以可伸缩的方式将NVIDIA NIM部署到您的基础架构上。我们现在可以在RAG管道中使用它们。下一节将提供详细信息。
在RAG管道中使用自托管的NVIDIA NIM
本节提供了将先前部署在Kubernetes集群上的NVIDIA NIM用于Haystack RAG管道中的NvidiaTextEmbedder、NvidiaDocumentEmbedder和NvidiaGenerator的说明,将<self-hosted-emedding-nim-url>替换为NeMo Retriever文本嵌入NIM的端点,并将<self-hosted-llm-nim-url>替换为LLM NIM。存储库中提供的Notebook包含了如何使用自托管NVIDIA NIM的示例。
NvidiaDocumentEmbedder:
embedder = NvidiaDocumentEmbedder(
model=embedding_nim_model,
api_url="http://<self-hosted-emedding-nim-url>/v1"
)
NvidiaTextEmbedder:
# initialize NvidiaTextEmbedder with the self-hosted NeMo Retriever Text Embedding NIM URL
embedder = NvidiaTextEmbedder(
model=embedding_nim_model,
api_url="http://<self-hosted-embedding-nim-url>/v1"
)
NvidiaGenerator:
# initialize NvidiaGenerator with the self-hosted LLM NIM URL
generator = NvidiaGenerator(
model=llm_nim_model_name,
api_url="http://<self-hosted-llm-nim-url>/v1",
model_arguments={
"temperature": 0.5,
"top_p": 0.7,
"max_tokens": 2048,
},
)
摘要
在这篇博文中,我们提供了使用Haystack和NVIDIA NIM构建健壮且可伸缩的RAG应用程序的全面指南。我们涵盖了通过利用托管在NVIDIA API目录上的NVIDIA NIM来构建RAG管道,以及使用部署在Kubernetes环境中的自托管NVIDIA NIM。我们的分步说明详细介绍了如何在Kubernetes集群中部署NVIDIA NIM,监控其性能,并根据需要进行伸缩。
通过利用成熟的部署模式,我们的架构确保了响应式的用户体验和可预测的查询时间,即使面对高或突发的查询和文档索引工作负载。此外,我们的部署方案非常灵活,可以轻松地在云、本地或隔离环境中实现。本指南旨在为任何寻求大规模构建可靠且高性能RAG应用程序的人提供资源。