

使用 Mixtral 8x7b、Haystack 和 PubMed 构建医疗聊天机器人
了解如何使用 PubMed 和 Mixtral 8x7B 创建自定义医疗聊天机器人,用于生成关键词和答案
2024 年 1 月 2 日不幸的是,全世界有无数人获得医疗保健的机会不足。我很幸运能获得健康保险和良好的医疗服务提供者的照顾。但是,在去看医生之前,我仍然想自己学习一些知识。
技术可以赋能人们掌控自己的健康。大型语言模型可以为聊天机器人提供支持,人们可以在其中提出医疗问题。
在这篇文章中,我将展示如何使用 Haystack 2.0-Beta 和 Mixtral 8x7B 模型,通过从 PubMed 获取研究论文来构建一个医疗聊天机器人。
您可以 跟随这个 Colab notebook。您需要一个 HuggingFace API 密钥。 在此处注册一个免费账户。
挑战
构建医疗聊天机器人会带来一些挑战。
- 数据缺乏。HIPAA 和其他隐私法规使得寻找可用于微调模型的公开 QA 数据集更加困难。
- 提供错误答案对人类的影响。 😬
- 保持更新。训练一个 LLM 需要很长时间。当它们发布时,它们的知识已经有些过时了。医学研究的突破一直在发生。我对长新冠特别感兴趣,它对人类造成了巨大的影响,并且是持续研究的主题。
因此,我决定使用 RAG 管道将 PubMed 数据与 LLM 结合起来。
PubMed RAG 管道
检索增强生成(RAG)是一种为 LLM 提供上下文以使其能够更好地回答问题的方法。
您将一些文档与一个查询一起传递给 LLM,并提示 LLM 在回答问题时使用这些文档。
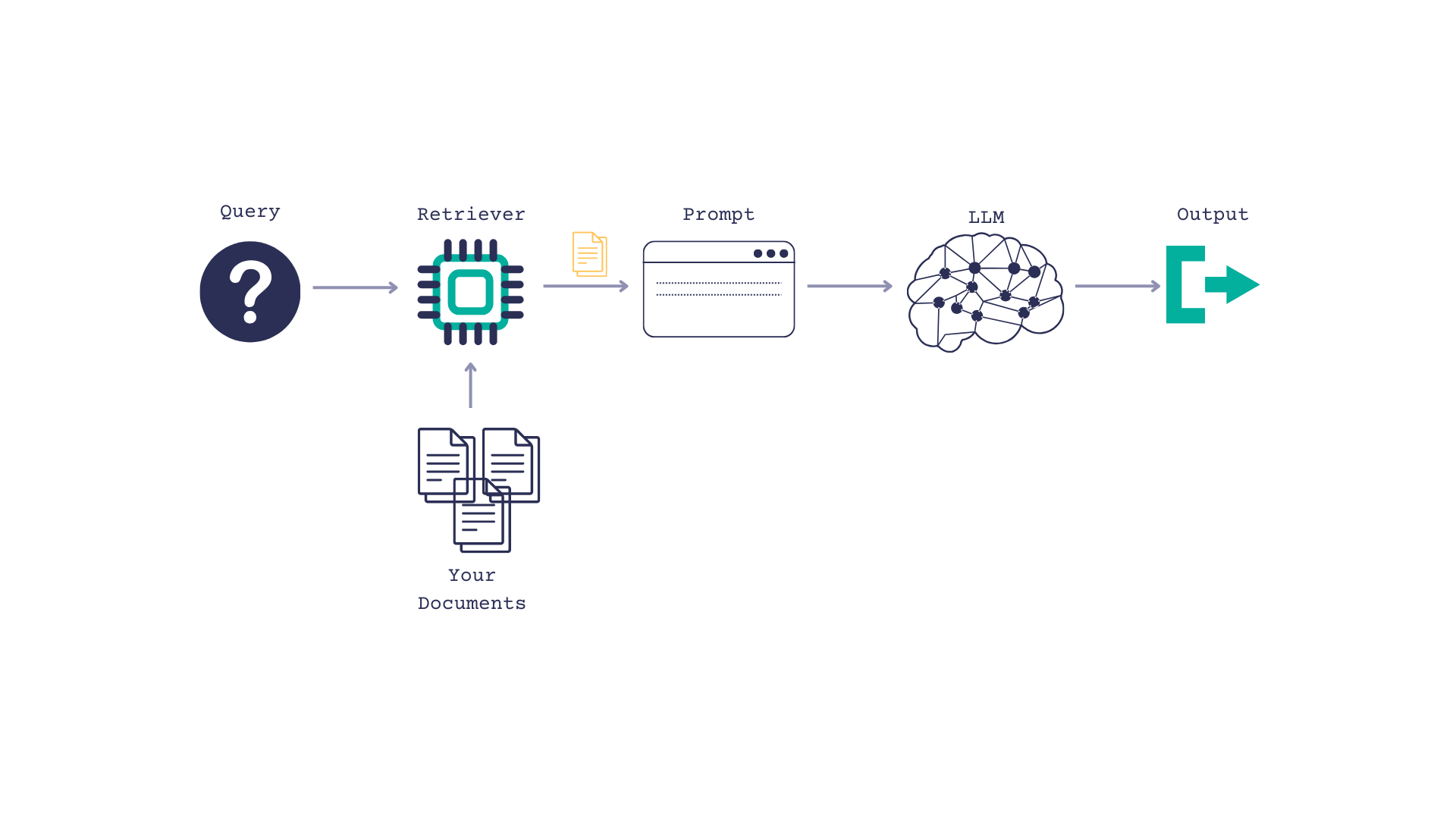
PubMed 拥有最新、可靠的医疗信息,因此它似乎是一个坚实的文档来源。此外,还有一个 PyMed 包装器用于 PubMed API,使得查询非常容易。我们将把它包装在一个 Haystack 自定义组件 中,将结果格式化为 Documents,以便 Haystack 可以使用它们,并添加一些轻量级的错误处理。
from pymed import PubMed
from typing import List
from haystack import component
from haystack import Document
pubmed = PubMed(tool="Haystack2.0Prototype", email="tilde.thurium@deepset.ai")
def documentize(article):
return Document(content=article.abstract, meta={'title': article.title, 'keywords': article.keywords})
@component
class PubMedFetcher():
@component.output_types(articles=List[Document])
def run(self, queries: list[str]):
cleaned_queries = queries[0].strip().split('\n')
articles = []
try:
for query in cleaned_queries:
response = pubmed.query(query, max_results = 1)
documents = [documentize(article) for article in response]
articles.extend(documents)
except Exception as e:
print(e)
print(f"Couldn't fetch articles for queries: {queries}" )
results = {'articles': articles}
return results
对于模型,我选择了 Mixtral 的 8x7b。Mixtral 是一种独特的模型,它使用 8 个“专家”和一个内部“路由”机制,将一个 token 路由到特定的专家。这也意味着在推理过程中,并非所有参数都会被使用,这使得模型响应速度非常快。 这篇 HuggingFace 博客文章更详细地解释了 MoE。
使用 Mixtral/LLM 为 PubMed 生成关键词
起初,我尝试了一种方法,直接将一个普通查询传递给 PubMed。例如“长新冠最当前的治疗方法是什么?”不幸的是,效果不太好。返回的文章不太相关。这也可以理解,因为 PubMed 并没有针对自然语言搜索进行优化。但是,它对关键词进行了优化。您知道什么擅长生成关键词吗?LLM!
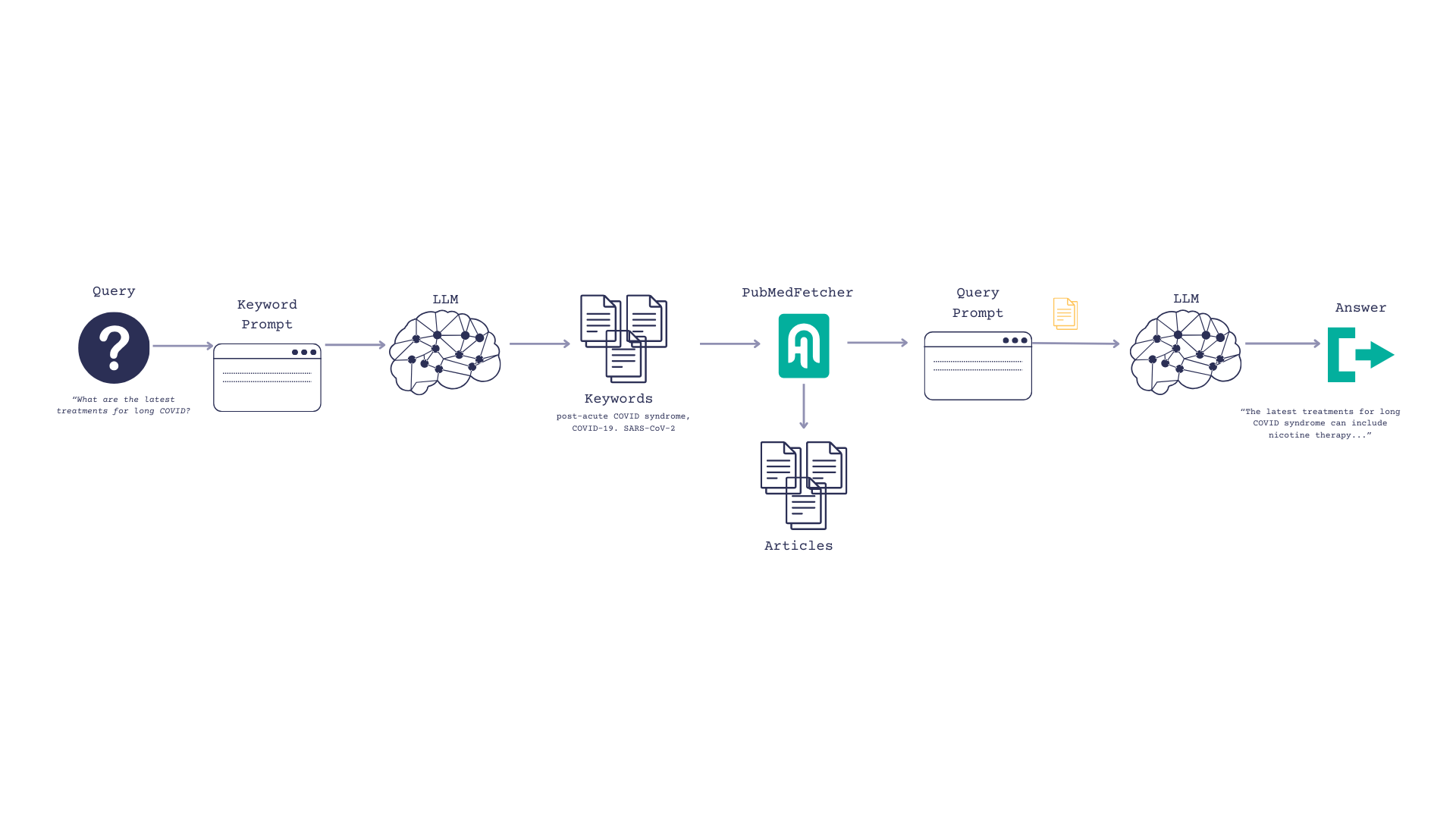
所以现在我们的流程如下:
- 用户输入一个问题,例如,“长新冠最当前的治疗方法是什么?”
- 我们提示 LLM 将问题转化为关键词
- 搜索 PubMed 并根据这些关键词返回 top_k 文章
- 将这些文章传递给 LLM,并要求它们在制定答案时参考这些文章。
首先,初始化 LLM 并预热它们。
from haystack.components.generators import HuggingFaceTGIGenerator
from haystack.utils import Secret
keyword_llm = HuggingFaceTGIGenerator("mistralai/Mixtral-8x7B-Instruct-v0.1", token=Secret.from_token(huggingface_token))
keyword_llm.warm_up()
llm = HuggingFaceTGIGenerator("mistralai/Mixtral-8x7B-Instruct-v0.1", token=Secret.from_token(huggingface_token))
llm.warm_up()
接下来,我们创建我们的提示和管道,并将所有内容连接起来。
from haystack import Pipeline
from haystack.components.builders.prompt_builder import PromptBuilder
keyword_prompt_template = """
Your task is to convert the follwing question into 3 keywords that can be used to find relevant medical research papers on PubMed.
Here is an examples:
question: "What are the latest treatments for major depressive disorder?"
keywords:
Antidepressive Agents
Depressive Disorder, Major
Treatment-Resistant depression
---
question: {{ question }}
keywords:
"""
prompt_template = """
Answer the question truthfully based on the given documents.
If the documents don't contain an answer, use your existing knowledge base.
q: {{ question }}
Articles:
{% for article in articles %}
{{article.content}}
keywords: {{article.meta['keywords']}}
title: {{article.meta['title']}}
{% endfor %}
"""
keyword_prompt_builder = PromptBuilder(template=keyword_prompt_template)
prompt_builder = PromptBuilder(template=prompt_template)
fetcher = PubMedFetcher()
pipe = Pipeline()
pipe.add_component("keyword_prompt_builder", keyword_prompt_builder)
pipe.add_component("keyword_llm", keyword_llm)
pipe.add_component("pubmed_fetcher", fetcher)
pipe.add_component("prompt_builder", prompt_builder)
pipe.add_component("llm", llm)
pipe.connect("keyword_prompt_builder.prompt", "keyword_llm.prompt")
pipe.connect("keyword_llm.replies", "pubmed_fetcher.queries")
pipe.connect("pubmed_fetcher.articles", "prompt_builder.articles")
pipe.connect("prompt_builder.prompt", "llm.prompt")
亲自尝试一下,看看效果!
question="What are the most current treatments for long COVID?"
pipe.run(data={"keyword_prompt_builder":{"question":question},
"prompt_builder":{"question": question},
"llm":{"generation_kwargs": {"max_new_tokens": 500}}})
What are the most current treatments for long COVID?
The COVID-19 pandemic has led to a significant increase in the number of patients with post-acute COVID-19 syndrome (PACS), also known as long COVID. PACS is a complex, multisystem disorder that can affect various organs and systems, including the respiratory, cardiovascular, neurological, and gastrointestinal systems. The pathophysiology of PACS is not yet fully understood, but it is believed to be related to immune dysregulation, persistent inflammation, and microvascular injury.
The management of PACS is challenging due to its heterogeneous presentation and the lack of evidence-based treatments. Current treatment approaches are mainly supportive and aim to alleviate symptoms and improve quality of life. These include:
- Pulmonary rehabilitation for respiratory symptoms
- Cardiac rehabilitation for cardiovascular symptoms
- Cognitive-behavioral therapy for neurological symptoms
- Dietary modifications and medications for gastrointestinal symptoms
- Vaccination to prevent reinfection and further complications
- Symptomatic treatment with medications such as nonsteroidal anti-inflammatory drugs (NSAIDs), corticosteroids, and antihistamines
- Experimental treatments such as antiviral therapy, immunomodulatory therapy, and cell-based therapy
潜在问题和解决方法
PubMed API 不是为高可扩展性设计的,所以这种方法对于高流量的生产系统来说并不理想。在这种情况下,您可以考虑将文章提取到一个 由持久存储支持的 Haystack DocumentStore 中。
或者,您可以尝试使用已经在医学数据集上训练过的模型,例如 Gradient 的模型。
总结
今天您学习了如何使用 Mixtral 8x7B 和 Haystack RAG 管道来构建一个医疗聊天机器人。感谢您的阅读!如果您想了解更多关于 Haystack 2.0 或 RAG 管道的信息,这些文章可能对您有所帮助:
