
使用自动合并改进检索
了解分层文档分割器和自动合并以改进检索到的上下文
2024 年 9 月 12 日对于大多数 RAG 应用,我们首先需要检索最相关的上下文,因此最终需要先拆分文档,然后索引这些较小的文档片段。这样做的原因有很多,从需要仅检索较大文档片段的*相关*部分,到 LLM 仍然没有无限上下文长度(尽管它们正在大规模改进)这一简单事实。
自动合并是一种利用分层文档结构的检索技术。当一个文档太长时,它会被拆分成更小的文档或块,我们可以将这些更小的文档视为原始文档的子文档,将原始文档视为父文档。这将形成一个分层树结构,其中每个较小的文档是前一个较大文档的子文档。树的叶子是没有子文档的文档,根是原始文档。
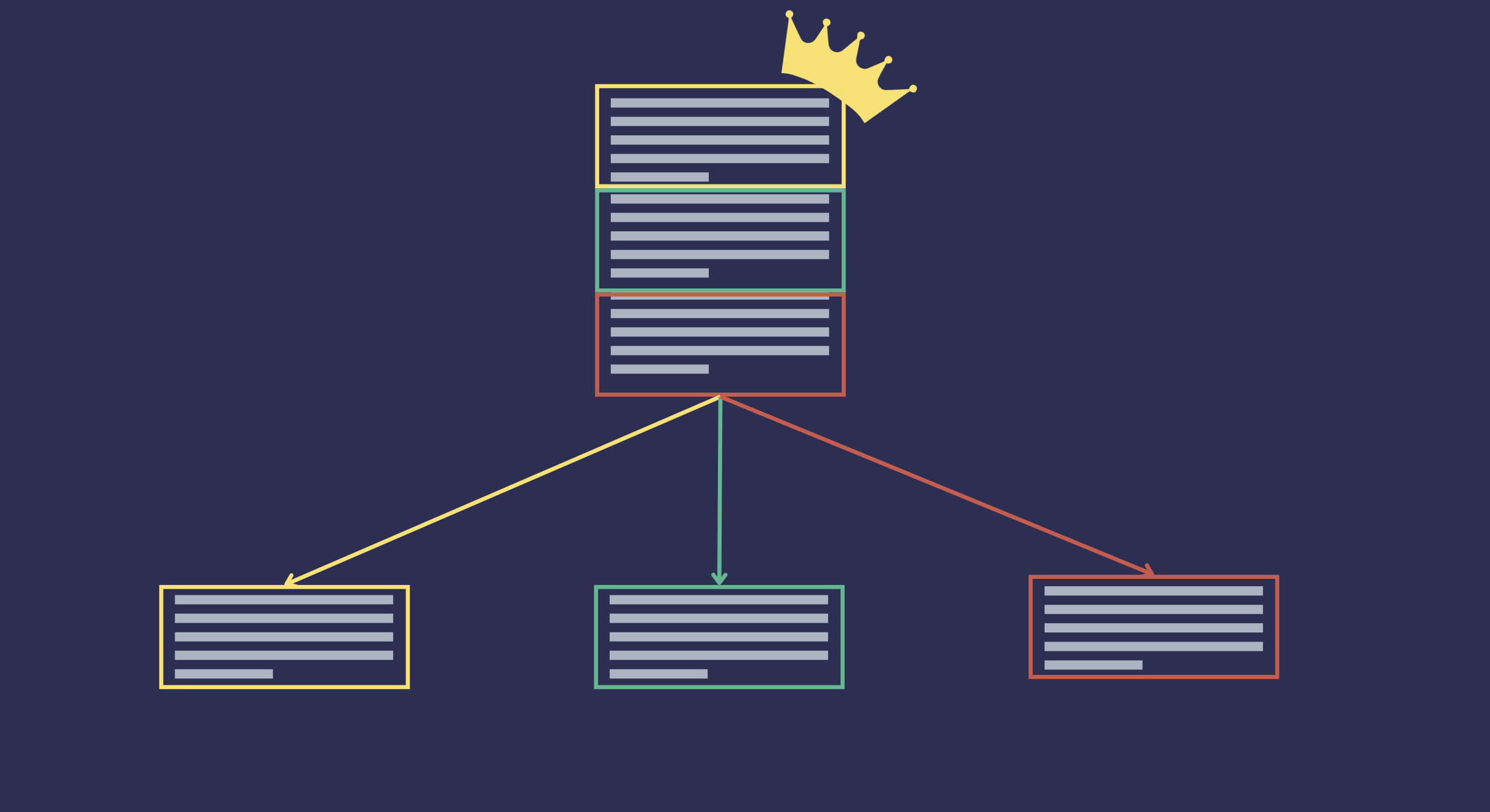
当父文档可能比其子文档的子集包含更多用户所需信息的相关上下文时,我们可以使用自动合并检索技术。当发出查询时,检索器通常会返回与查询相关的 top_k 个文档块。但是,如果属于同一父文档的检索到的文档块数量超过特定阈值,则检索器将返回父文档而不是单个块。
Haystack 组件
Haystack 使用两个组件来实现自动合并检索
-
HierarchicalDocumentSplitter:将文档拆分成多个不同块大小的 Document 对象,构建一个分层树结构,其中每个较小的块是前一个较大块的子块。init方法需要三个参数:block_sizes:用于拆分文档的块大小集合。块按降序拆分。因此,{20, 5} 的block_sizes意味着每个“父”块的最大长度为 20,其每个子块的最大长度为 5。split_overlap:每个拆分的重叠单元数。split_by:用于拆分文档的单元。
-
AutoMergingRetriever:一种利用文档的分层树结构检索器,其中叶节点索引在文档存储中。在检索过程中,如果同一父文档下的匹配叶子文档数量高于定义的阈值,检索器将返回父文档而不是单个叶子文档。init方法需要三个参数:document_store:用于检索父文档的 DocumentStorethreshold:用于决定返回父文档而不是单个文档的阈值
入门示例
让我们来看一个简单的例子,演示 AutoMergingRetriever 如何工作。在这个例子中,我们将使用一个文档。我们使用 HierarchicalDocumentSplitter 将文档拆分成块,这些块由更小的文档表示,并捕获文档的分层结构。
from haystack import Document
from haystack.components.preprocessors import HierarchicalDocumentSplitter
docs = [Document(content="The monarch of the wild blue yonder rises from the eastern side of the horizon.")]
splitter = HierarchicalDocumentSplitter(block_sizes={10, 3}, split_overlap=0, split_by="word")
docs = splitter.run(docs)
我们首先创建一个文档,然后使用 HierarchicalDocumentSplitter 将其拆分成更小的文档。我们需要指定要拆分文档的块大小。在这种情况下,我们将文档拆分成 10 个和 3 个单词的块 - 这意味着分割器只有 2 个级别,第一个级别最多 10 个单词,第二个级别最多 3 个单词。文档之间没有重叠,我们还指定要按单词拆分文档。这导致从原始文档创建了 9 个文档。文档拆分如下:
`The monarch of the wild blue yonder rises from the eastern side of the horizon.` -- (root)
|
|
|
|--- `The monarch of the wild blue yonder rises from the`
| |
| |
| |--- `The monarch of` -- (leaf)
| |
| |--- `the wild blue` -- (leaf)
| |
| |--- `yonder rises from` -- (leaf)
| |
| |--- `the` -- (leaf)
|
|
|--- `eastern side of the horizon.` -- (leaf)
| |
| |
| |--- `eastern side of` -- (leaf)
| |
| |--- `the horizon.` -- (leaf)
请注意,原始文档始终是树的根。然后我们有两个子级别,第一个子级别最大块大小为 10 个单词,第二个子级别最大块大小为 3 个单词。
现在我们需要将这些文档拆分到两个不同的文档存储中。在初始化过程中,AutoMergingRetriever 需要索引父文档的文档存储。在运行时,它接收匹配用户查询的叶子文档,如果同一父文档下的匹配叶子文档数量高于定义的阈值,它将返回父文档,否则返回原始检索到的叶子文档。
让我们实际看一下。我们索引父文档,通过选择 __level 为 1 的文档。
from haystack.document_stores.in_memory import InMemoryDocumentStore
parent_docs_store = InMemoryDocumentStore()
parent_docs = [doc for doc in docs["documents"] if doc.meta["__level"]==1]
parent_docs_store.write_documents(parent_docs)
现在让我们使用父文档存储和父阈值 0.5 来初始化 AutoMergingRetriever,这意味着如果同一父文档下的至少 50% 的叶子文档匹配查询,检索器将返回父文档而不是匹配用户查询的叶子文档。如果我们使用单个叶子文档查询文档存储,检索器将返回相同的叶子文档。
from haystack.components.retrievers import AutoMergingRetriever
retriever = AutoMergingRetriever(document_store=parent_docs_store, threshold=0.5)
retriever.run(matched_leaf_documents=[docs['documents'][4]])
如果我们现在使用两个叶子文档查询文档存储,检索器将返回父文档而不是单独的叶子文档,因为阈值 0.5 已满足。
matched_leaf_documents = [docs['documents'][4], docs['documents'][5]]
retriever.run(matched_leaf_documents=matched_leaf_documents)
这是一个简单的入门示例,展示了 AutoMergingRetriever 如何工作以及如何检索父文档而不是单个叶子文档。接下来,我们将使用新闻文章数据集进行一个完整的示例。
高级示例
我们将使用 BBC 新闻数据集来展示 AutoMergingRetriever 如何处理包含多个新闻文章的数据集。该数据集包含 2,225 篇来自 BBC 的文档,涵盖 2004-2005 年期间的五个主题领域,这是 D. Greene 和 P. Cunningham 的工作的一部分。“Practical Solutions to the Problem of Diagonal Dominance in Kernel Document Clustering”, Proc. ICML 2006。
阅读数据集
原始数据集可在 http://mlg.ucd.ie/datasets/bbc.html 找到,但我们将使用一个已预处理并存储在单个 CSV 文件中的版本,该文件可在以下 URL 找到:
from typing import List
import csv
from haystack import Document
def read_documents(file: str) -> List[Document]:
with open(file, "r") as file:
reader = csv.reader(file, delimiter="\\t")
next(reader, None) # skip the headers
documents = []
for row in reader:
category = row[0].strip()
title = row[2].strip()
text = row[3].strip()
documents.append(Document(content=text, meta={"category": category, "title": title}))
return documents
docs = read_documents("bbc-news-data.csv")
len(docs)
>> 2225
索引文档
在将新闻文章读入 Haystack Document 对象后,我们现在对其进行索引。为了简单起见,我们将使用 InMemoryDocumentStore 作为文档存储。我们首先将 HierarchicalDocumentSplitter 应用于 Document 列表,创建分层结构。
我们将创建两个文档存储,一个用于父文档,一个用于叶子文档。稍后我们将说,将有一个中间检索器来匹配用户查询与索引的叶子文档,然后这个中间检索器将连接到一个 AutoMergingRetriever,该检索器决定何时返回父文档而不是叶子文档。
下面的函数接收新闻文章作为 Documents,并按元字段 __level 进行过滤,以区分子文档和父文档,并将它们索引到各自的文档存储中,这两个文档存储都将由该函数返回。
from typing import Tuple
from haystack.document_stores.in_memory import InMemoryDocumentStore
from haystack.document_stores.types import DuplicatePolicy
from haystack.components.preprocessors import HierarchicalDocumentSplitter
def indexing(documents: List[Document]) -> Tuple[InMemoryDocumentStore, InMemoryDocumentStore]:
splitter = HierarchicalDocumentSplitter(block_sizes={10, 5}, split_overlap=0, split_by="sentence")
docs = splitter.run(documents)
# store the leaf documents in one document store
leaf_documents = [doc for doc in docs["documents"] if doc.meta["__level"] == 1]
leaf_doc_store = InMemoryDocumentStore()
leaf_doc_store.write_documents(leaf_documents, policy=DuplicatePolicy.SKIP)
# store the parent documents in another document store
parent_documents = [doc for doc in docs["documents"] if doc.meta["__level"] == 0]
parent_doc_store = InMemoryDocumentStore()
parent_doc_store.write_documents(parent_documents, policy=DuplicatePolicy.SKIP)
return leaf_doc_store, parent_doc_store
查询文档
现在我们有了文档存储,让我们构建一个查询管道,它由一个与包含叶子文档的文档存储关联的 BM25Retriever,以及一个与父文档关联且阈值为 0.6 的 AutoMergingRetriever 组成,这意味着如果至少 60% 的匹配叶子文档属于同一个父文档,则返回其父文档而不是每个单独的 Document。
from haystack import Pipeline
from haystack.components.retrievers import InMemoryBM25Retriever
from haystack.components.retrievers import AutoMergingRetriever
def querying_pipeline(leaf_doc_store: InMemoryDocumentStore, parent_doc_store: InMemoryDocumentStore, threshold: float = 0.6):
pipeline = Pipeline()
bm25_retriever = InMemoryBM25Retriever(document_store=leaf_doc_store)
auto_merge_retriever = AutoMergingRetriever(parent_doc_store, threshold=threshold)
pipeline.add_component(instance=bm25_retriever, name="BM25Retriever")
pipeline.add_component(instance=auto_merge_retriever, name="AutoMergingRetriever")
pipeline.connect("BM25Retriever.documents", "AutoMergingRetriever.matched_leaf_documents")
return pipeline
整合
docs = read_documents("bbc-news-data.csv")
leaf_doc_store, parent_doc_store = indexing(docs)
pipeline = querying_pipeline(leaf_doc_store, parent_doc_store, threshold=0.6)
所以,现在我们可以单独运行每个函数,并拥有一个使用 AutoMergingRetriever 的查询管道。然后,我们可以使用该管道查询文档存储以获取与网络安全相关的文章,我们还可以利用管道参数 include_outputs_from 来获取 BM25Retriever 组件的输出。
result = pipeline.run(data={'query': 'phishing attacks spoof websites spam e-mails spyware'}, include_outputs_from={'BM25Retriever'})
result 将有两个键,分别对应两个检索器组件:AutoMergingRetriever 和 BM25Retriever。
让我们看看每个组件检索了多少文档。
In [17]: len(result['AutoMergingRetriever']['documents'])
Out[17]: 7
In [18]: len(result['BM25Retriever']['documents'])
Out[18]: 10
如我们所见,AutoMergingRetriever 检索了 7 个文档,而 BM25Retriever 检索了 10 个文档。这是因为 AutoMergingRetriever 返回了父文档而不是单个叶子文档。让我们比较一下 BM25Retriever 和 AutoMergingRetriever 检索的文档标题。
doc_titles = sorted([d.meta['title'] for d in result['BM25Retriever']['documents']])
In [14]: doc_titles
Out[14]:
['Bad e-mail habits sustains spam',
'Bad e-mail habits sustains spam',
'Cyber crime booms in 2004',
'Cyber criminals step up the pace',
'Cyber criminals step up the pace',
'Junk e-mails on relentless rise',
'More women turn to net security',
'Security scares spark browser fix',
'Spam e-mails tempt net shoppers',
'Spam e-mails tempt net shoppers']
In [15]: doc_titles = sorted([d.meta['title'] for d in result['AutoMergingRetriever']['documents']])
In [16]: doc_titles
Out[16]:
['Bad e-mail habits sustains spam',
'Cyber crime booms in 2004',
'Cyber criminals step up the pace',
'Junk e-mails on relentless rise',
'More women turn to net security',
'Security scares spark browser fix',
'Spam e-mails tempt net shoppers']
AutoMergingRetriever 返回了文章的父文档,而不是单个叶子文档。
- “不良电子邮件习惯助长垃圾邮件”
- “网络罪犯加速步伐”
- “垃圾邮件诱惑网购者”;
因为其中每篇文档的叶子文档至少有 60% 匹配了查询。
结论
在本教程中,我们了解了 AutoMergingRetriever 的工作原理。Haystack 中 AutoMergingRetriever 实现的一个重要方面是,它要求使用 HierarchicalDocumentSplitter 来拆分文档。另一个要注意的方面是,正如我们所见,AutoMergingRetriever 应与其他基础 Retrievers 结合使用,以实现更灵活的检索系统。
