
使用 NVIDIA NIM 在 deepset Studio 中直观地设计 Haystack AI 应用
在我们之前的文章中,我们探讨了如何使用 Haystack 和 NVIDIA NIM 构建和部署检索增强生成 (RAG) 应用中的两个关键 AI 管道。
- 索引管道:通过预处理、分块和嵌入 PDF 文件来准备数据,最后将其存储在向量数据库中。
- RAG 管道:用于根据上传的 PDF 文件内容回答问题。
在本文中,我们将更进一步,展示如何使用deepset Studio直观地设计这些 AI 管道的架构。deepset Studio 是一个新发布的工具,可用于可视化创建、部署和测试管道。通过此工具,您可以映射出 AI 工作流的整个结构,从数据摄感到检索,同时无缝集成由NVIDIA API 目录中提供的 NVIDIA NIM 微服务加速的生成式 AI 模型。
通过可视化构建这些管道,您不仅能看到 AI 应用的逻辑流程,还能在编写代码之前快速迭代设计。一旦完成,deepset Studio 允许您将管道导出为 Python 代码或 YAML 定义,即可进行部署。
阅读本文后,您将了解如何使用deepset Studio构建 AI 管道,同时利用NVIDIA API 目录中的检索嵌入和 LLM NIM 微服务。我们还将指导您完成使用 NIM API 的过程,并演示如何根据您的选择在deepset Studio中配置它们以进行本地部署。
deepset Studio:您的 Haystack 开发环境
大多数 AI 应用由许多协同工作的组件构成,以实现最终用例。无论是 RAG、准备和嵌入文档、与数据库聊天还是其他功能,我们都会涉及不同的模型、提示、决策步骤、预处理器等。此外,最终设计的确定通常也涉及多个利益相关者。
一个代表应用程序逻辑流程的可视化层有助于我们在一个易于理解的简单界面中推理应用程序。它也有助于与不同利益相关者进行快速迭代。
现在,我们将看到如何使用 deepset Studio(您可以在此处注册)可视化地创建这些管道。deepset Studio 是 Haystack 的新开发环境,允许您在拖放式 UI 中设计、构建、部署和运行这些管道。对于每个需要生成式 AI 模型(如嵌入模型或 LLM 生成器)的步骤,我们将使用 NVIDIA API 目录中 NVIDIA 托管的模型。最后,我们将展示如何使用 NVIDIA NIM 自行托管生成式 AI 模型。
NVIDIA NIM 微服务
NVIDIA NIM,作为 NVIDIA AI Enterprise 软件平台的一部分,是一套容器化的微服务,旨在优化 AI 模型的推理。这些容器包含各种组件,可有效地服务 AI 模型并通过标准 API 暴露它们。模型通过NVIDIA TensorRT或NVIDIA TensorRT-LLM(取决于模型类型)进行优化,利用量化、模型分区、优化内核/运行时以及动态或连续批处理等技术。这允许进行进一步的性能调优以最大化效率。
NIM 微服务提供简化的集成和生产就绪的、优化的生成式 AI 部署,使开发人员能够专注于构建他们的应用程序。
NIM 微服务可用于流行的 AI 基础模型,包括 LLM 社区模型和特定于检索的文本嵌入和重排序 AI 模型。开发人员可以通过 NVIDIA API 目录轻松开始使用 NVIDIA NIM,生成免费 API 密钥,或下载并将 NIM 微服务容器部署到他们自己的环境中。
使用 deepset Studio 构建 RAG 应用
构建有效的 RAG 应用时,一个常被忽视但至关重要的步骤是数据准备和上下文嵌入——这个过程可能非常耗时。在深入考虑使用哪个 LLM 或如何增强提示之前,首先关注嵌入和存储文档(尤其是在不依赖外部 API 进行数据检索时)至关重要。
大多数 RAG 应用围绕两个核心管道:索引和RAG。图 1 显示了使用 Haystack 和 NVIDIA NIM 的两个管道的高级概述。本文将使用 Qdrant 作为向量数据库,但可以替换为任何其他数据库。
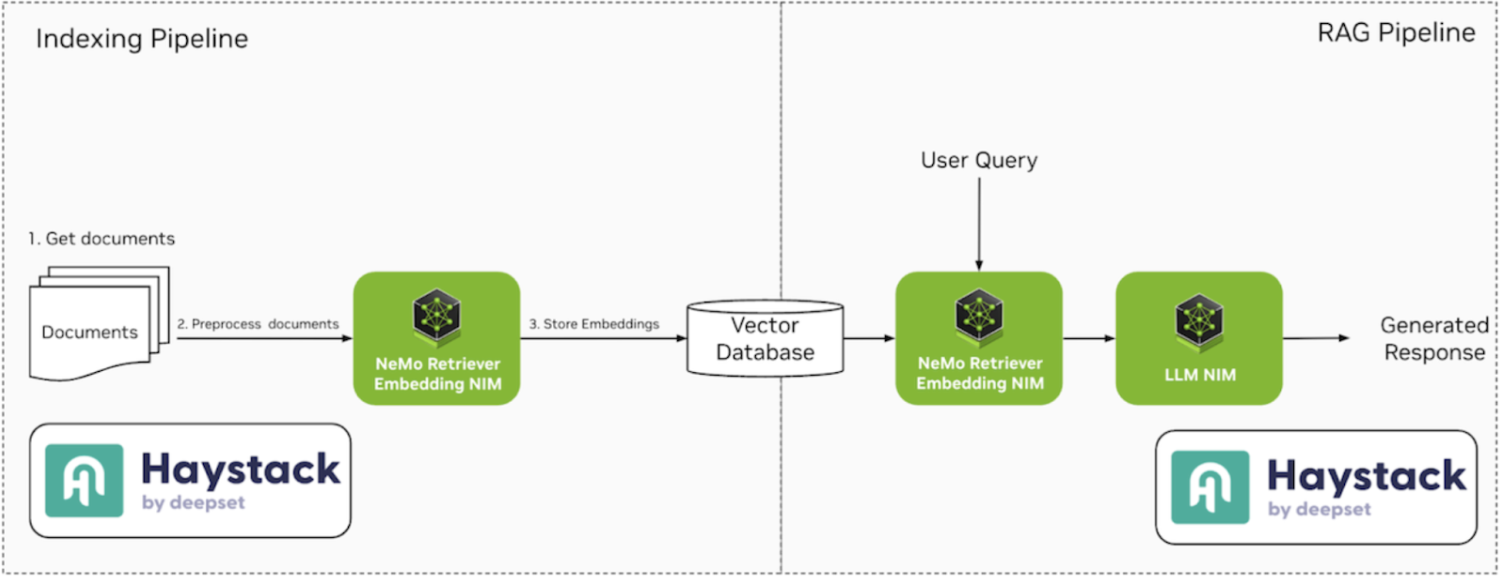
在接下来的章节中,我们将详细分解每个管道,并指导您使用deepset Studio构建它们。
索引管道
索引管道负责准备数据,这些数据为 LLM 的响应创建上下文。此管道可能包括数据清理、分块、嵌入组件,最终将处理后的数据(即嵌入)存储在向量数据库中以创建可搜索的上下文。
NVIDIA NeMo Retriever 为语义搜索应用(如 RAG)提供基础构建块,实现准确且优化的文档索引和大规模搜索。您可以使用NeMo Retriever 文本嵌入 NIM 微服务来矢量化文档,并使用NeMo Retriever 文本重排序 NIM 微服务进一步优化搜索。
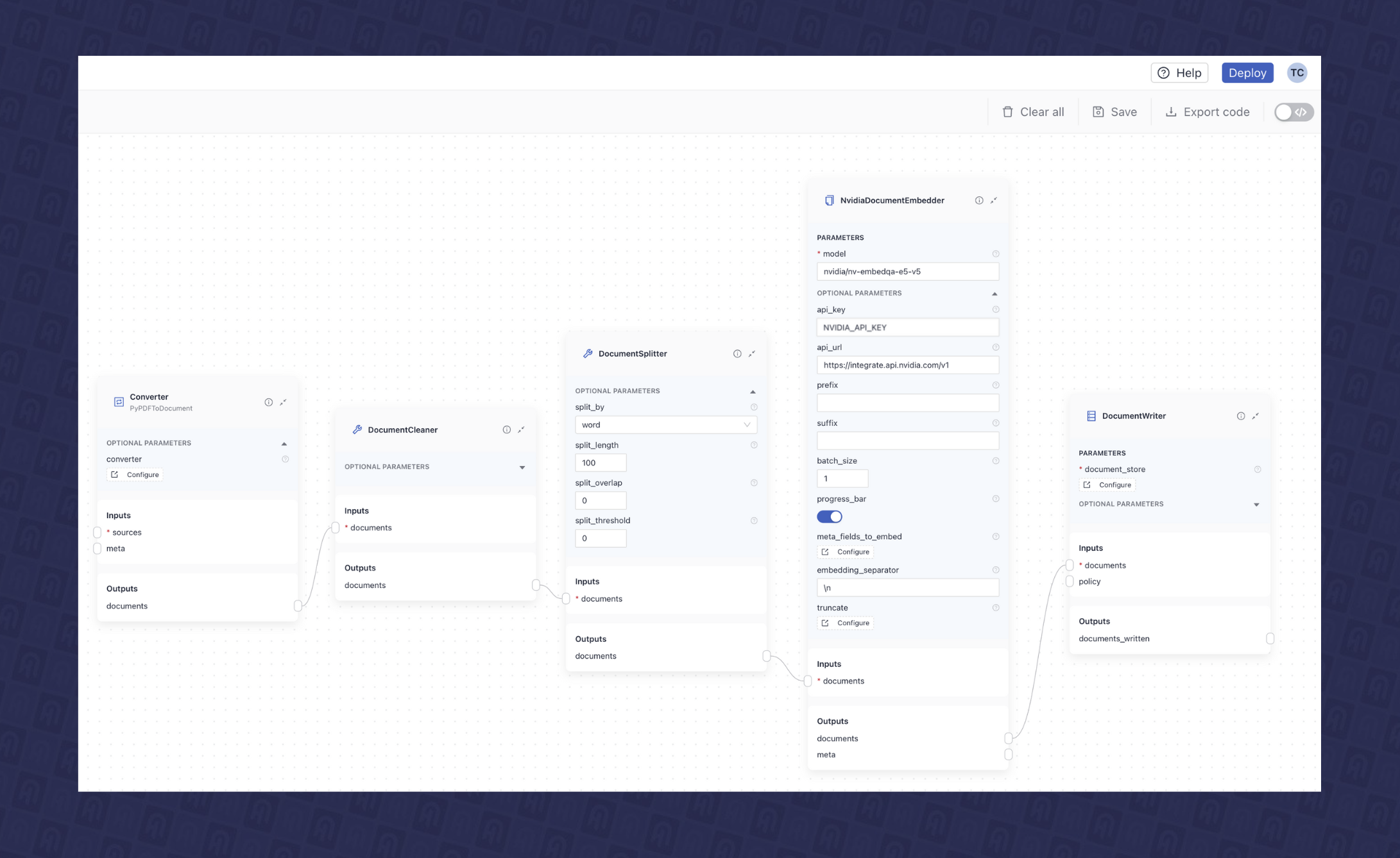
此管道涉及将 PDF 文件索引到向量数据库(此处为Qdrant数据库),包括预处理、清理、拆分和嵌入数据。Haystack 提供了多种组件来构建此类管道。在此示例中,我们将使用以下组件:
- PyPDFtoDocument:一个 PDF 转换器,可将 PDF 文件转换为文档数据类,Haystack 可以在管道中使用它。
- DocumentCleaner:一个预处理文档清理组件,可删除不必要的元素,如空行、页眉和页脚,从而实现更干净的数据。
- DocumentSplitter:此组件将大型文档分解为更小、更易于管理的块,以便进行嵌入和存储。您可以按单词、句子或段落自定义拆分,并定义每个块的长度以及它们之间的重叠。这有助于应对 LLM 上下文限制等挑战,并确保在检索阶段只获取最相关的片段进行处理。
- NvidiaDocumentEmbedder:此组件支持使用NeMo Retriever 文本嵌入 NIM 微服务进行文档嵌入,该服务可以通过NVIDIA API 目录托管,也可以自行托管在您的基础设施中。在本文中,我们将使用nvidia/nv-embedqa-e5-v5 NIM微服务进行文档嵌入。
我们可以在 deepset Studio 中单独配置这些组件并将它们连接起来以构建索引管道。图 2 显示了 deepset Studio 中构建的索引管道的最终可视化设计。
RAG 管道
完成数据准备步骤后,您可以继续实现检索增强步骤。识别用于生成文档嵌入的嵌入 NIM 微服务至关重要,因为我们通常需要相同的模型来进行检索。
在大多数用例中,RAG 管道由三个到四个组件组成。在本文中,我们将使用以下组件来构建 RAG 管道:
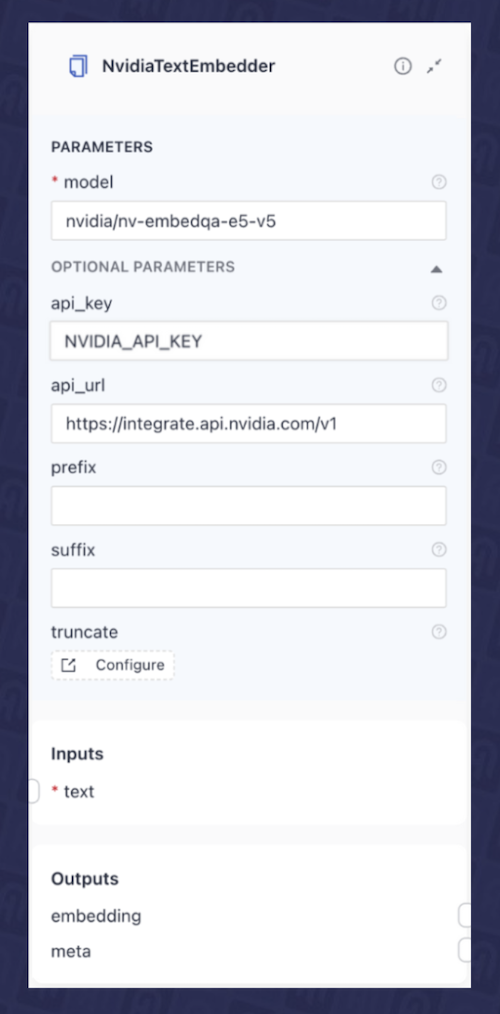
- Text Embedder:此组件使用数据索引管道期间使用的相同嵌入模型来嵌入用户输入的查询。为此,我们将使用
NvidiaTextEmbedder组件,我们已将其配置为利用 NVIDIA API Catalog(nvidia/nv-embedqa-e5-v5)中 NVIDIA 托管的NVIDIA NeMo Retriever 文本嵌入 NIM 微服务。要进行设置,您需要提供模型的api_url和NVIDIA_API_KEY,如图 3 所示。
- Retriever:在这种情况下,我们将使用
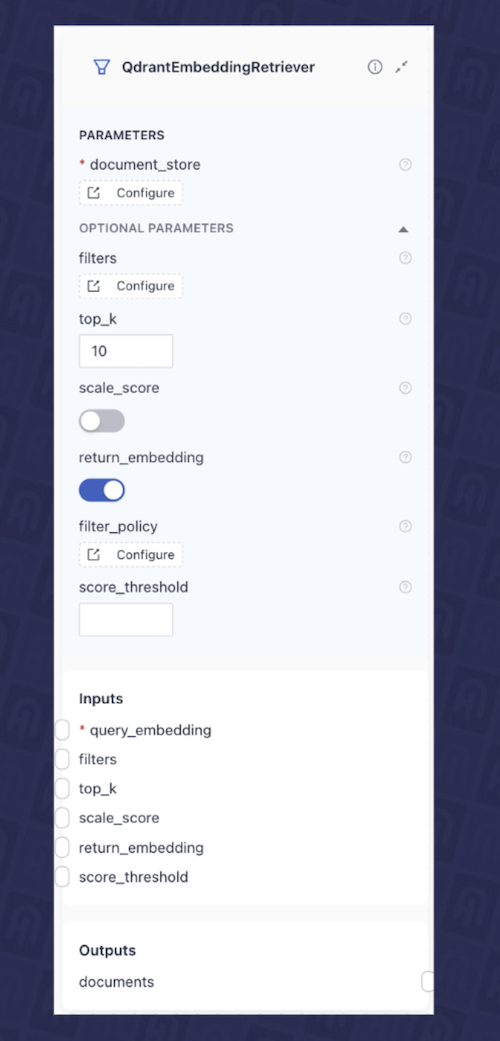
QdrantEmbeddingRetriever,它接收来自上一个组件的查询嵌入,并从 Qdrant 数据库检索最相关的文档。图 4 显示了 deepset Studio 中该组件的配置。
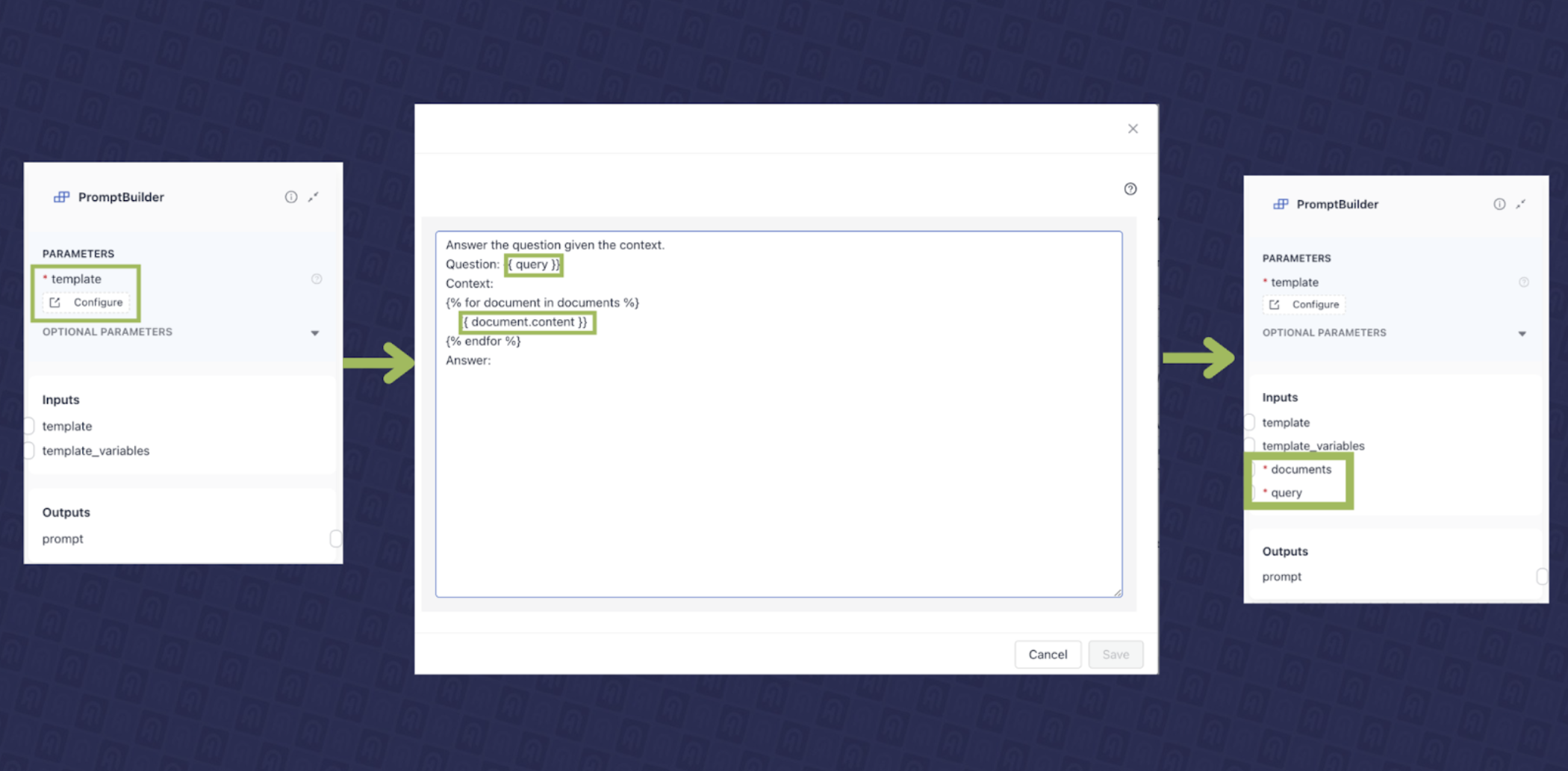
- Prompt Construction Component:此组件负责创建将发送到大型语言模型 (LLM) 的指令(提示),代表“增强”步骤。在 Haystack 中,这由
PromptBuilder处理。它允许您使用 Jinja 创建提示模板,并根据模板的内容动态检测输入。对于我们的用例,我们在 deepset Studio 中使用 PromptBuilder 开发了一个提示模板,如图 5 所示,该模板需要查询和文档作为输入。
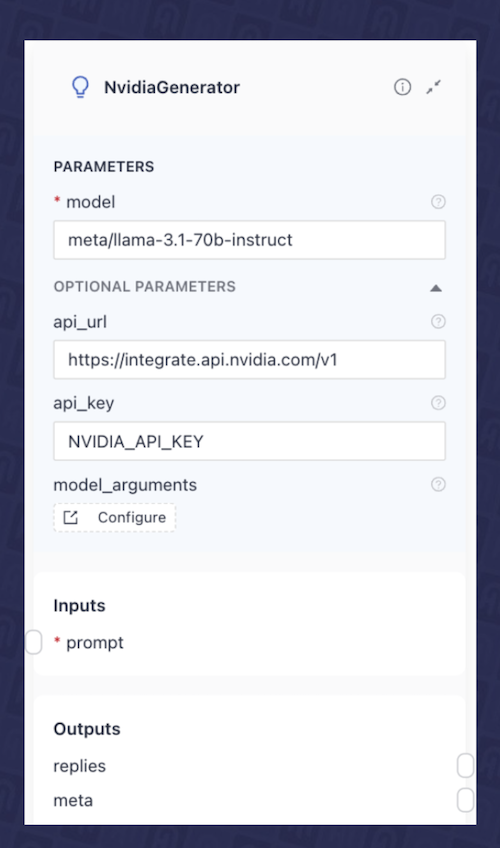
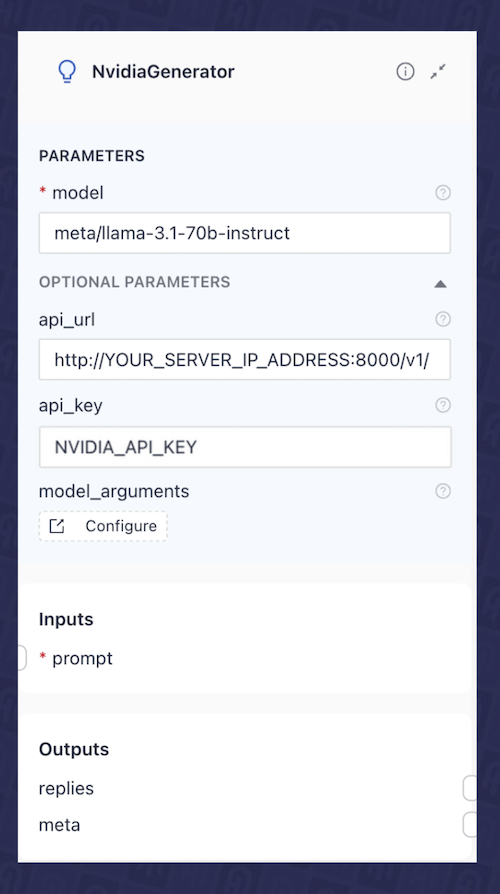
- LLM Component:最后,我们将添加一个 LLM 组件,该组件接收我们最终的增强提示并生成响应。在此示例中,我们将使用llama-3_1-70b-instruct NIM 微服务,该服务来自NVIDIA API 目录。在这种情况下,我们使用 Haystack 中的
NvidiaGenerator组件,并将其配置为使用meta/llama-3.1-70b-instruct模型。图 6 显示了 deepset Studio 中该组件的配置。
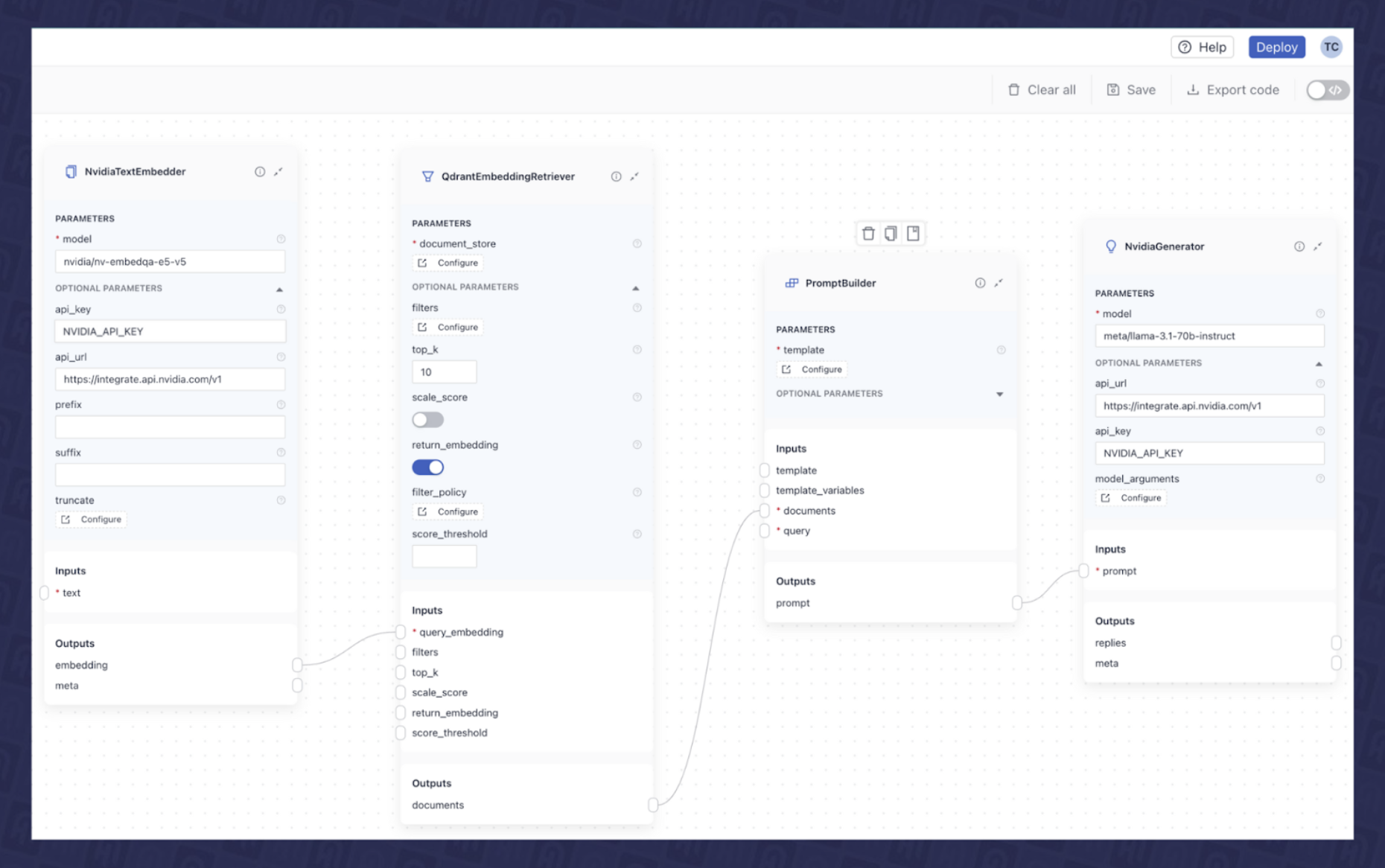
如您所见,这些独立组件中的每一个都需要特定的输入并产生各种输出。您可以在此处了解有关管道架构以及组件如何连接的更多信息。我们现在可以在 deepset Studio 中连接它们以创建最终的 RAG 管道,如图 7 所示。
为管道使用自托管 NIM 微服务
上面描述的索引和 RAG Haystack 管道使用来自 NVIDIA API 目录的 NIM 端点。但是,您也可以在自己的环境中自托管和部署 NIM 微服务。在这种情况下,您只需将 API 目录中的 NIM 端点替换为自托管的 NIM 端点即可。接下来,我们将看到如何做到这一点。
首先,您需要将 NIM 微服务部署到您的环境中。此部署可以使用 Docker 或 Kubernetes 进行。在我们之前的文章中,我们详细介绍了在 Kubernetes 集群上部署 NIM 微服务容器。但是,为了进行更快的原型设计,我们将在此处概述使用 Docker 部署 NIM 容器的步骤。
以下命令将在配备了受支持 GPU 的服务器上部署 meta/llama-3.1-70b-instruct LLM NIM 微服务。您可以参考支持矩阵以了解与不同 GPU 型号的兼容性。
export NGC_API_KEY=<PASTE_API_KEY_HERE>
export LOCAL_NIM_CACHE=~/.cache/nim
mkdir -p "$LOCAL_NIM_CACHE"
docker run -it --rm \
--gpus all \
--shm-size=16GB \
-e NGC_API_KEY \
-v "$LOCAL_NIM_CACHE:/opt/nim/.cache" \
-u $(id -u) \
-p 8000:8000 \
nvcr.io/nim/meta/llama-3.1-70b-instruct:1.1.2
此命令将拉取 NIM 容器,该容器首先检查底层 GPU。根据此检测,它将从NVIDIA NGC 目录下载适合已识别 GPU 基础架构的优化模型。
您可以按照相同的部署过程为NVIDIA NeMo Retriever 文本嵌入 NIM 微服务部署嵌入模型,相关说明可在此处找到。
一旦 NIM 部署完成(无论是通过 Docker 还是 Kubernetes),只需将管道中嵌入和 LLM 组件的 api_url 更新为指向您自托管的 NIM API 端点 URL(例如:http://your_server_ip_address:8000/v1/),如图 8 中NvidiaGenerator(即 LLM 组件)所示。
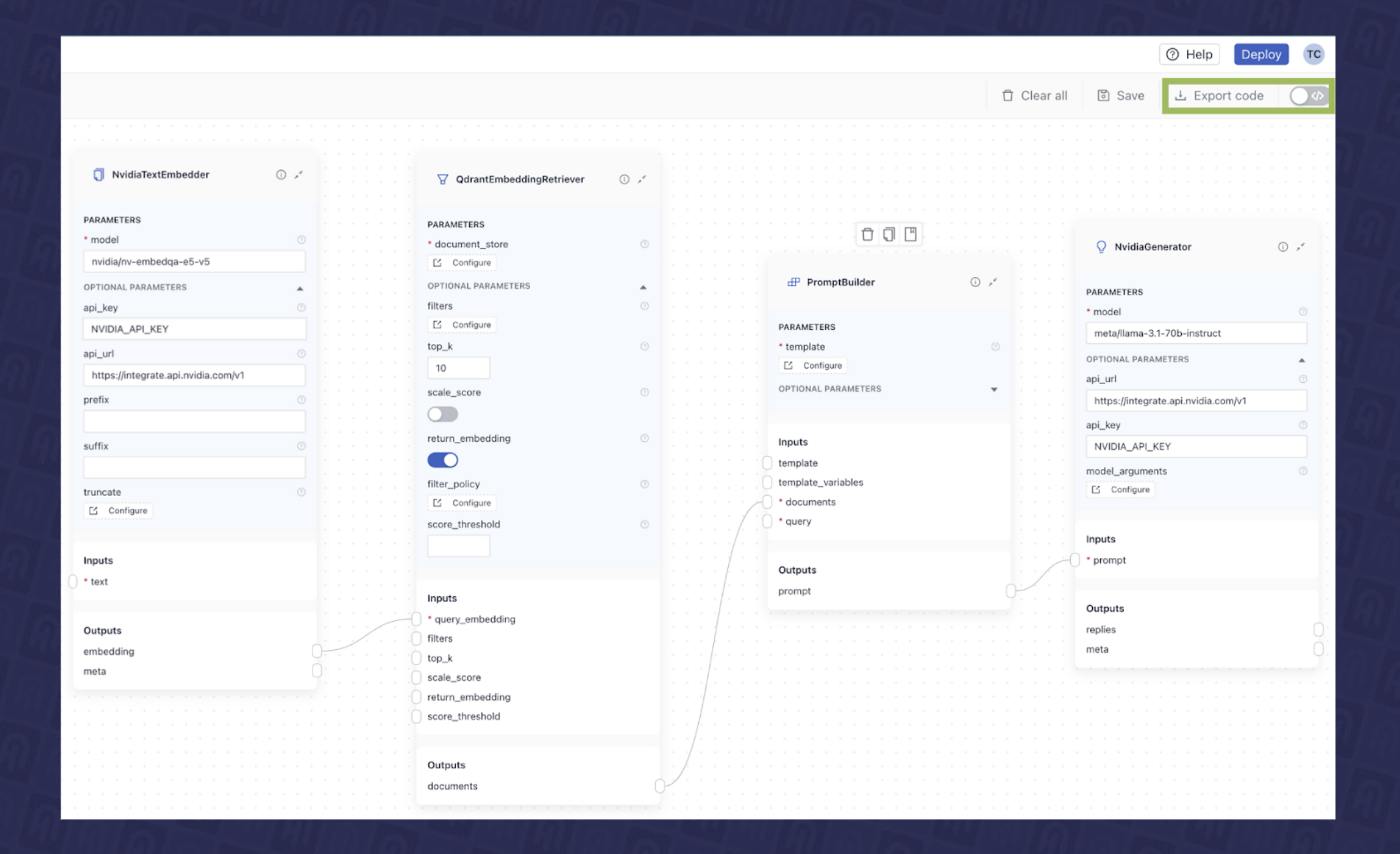
导出管道并部署 RAG 应用
在 deepset Studio 中构建完应用程序的最终布局后,我们可以通过单击导出按钮,以两种格式之一导出管道进行部署。
- YAML:在我们之前的文章中,我们创建了类似的索引和 RAG 管道,演示了如何将它们序列化为 YAML 并使用Hayhooks进行部署。如果您想遵循相同的方法,可以选择此选项。
- Python:或者,您可以将管道导出为标准的 Python 脚本以进行本地执行。
图 9 展示了在 deepset Studio 中以 Python 格式导出 RAG 管道的示例。
以下 Python 代码片段显示了从 deepset Studio 导出的 RAG 管道的代码。
from haystack import Pipeline
from haystack_integrations.components.embedders.nvidia.text_embedder import NvidiaTextEmbedder
from haystack_integrations.document_stores.qdrant.document_store import QdrantDocumentStore
from haystack_integrations.components.retrievers.qdrant.retriever import QdrantEmbeddingRetriever
from haystack.components.builders.prompt_builder import PromptBuilder
from haystack_integrations.components.generators.nvidia.generator import NvidiaGenerator
nvidiatextembedder = NvidiaTextEmbedder(model="snowflake/arctic-embed-l", api_url="https://ai.api.nvidia.com/v1/retrieval/snowflake/arctic-embed-l")
document_store = QdrantDocumentStore(embedding_dim=1024, host="qdrant")
qdrantembeddingretriever = QdrantEmbeddingRetriever(top_k=10, return_embedding=True, document_store=document_store)
promptbuilder = PromptBuilder(template="Answer the question given the context.\nQuestion: {{ query }}\nContext:\n{% for document in documents %}\n {{ document.content }}\n{% endfor %}\nAnswer:")
nvidiagenerator = NvidiaGenerator(model="meta/llama-3.1-70b-instruct", api_url="https://integrate.api.nvidia.com/v1", model_arguments={"max_tokens": 1024})
pipeline = Pipeline()
pipeline.add_component("nvidiatextembedder", nvidiatextembedder)
pipeline.add_component("qdrantembeddingretriever", qdrantembeddingretriever)
pipeline.add_component("promptbuilder", promptbuilder)
pipeline.add_component("nvidiagenerator", nvidiagenerator)
pipeline.connect("nvidiatextembedder.embedding", "qdrantembeddingretriever.query_embedding")
pipeline.connect("qdrantembeddingretriever.documents", "promptbuilder.documents")
pipeline.connect("promptbuilder.prompt", "nvidiagenerator.prompt")
现在我们有了可运行的管道,可以选择以下选项之一来部署 RAG 应用:
- 使用Hayhooks在容器化环境中自托管管道。Docker 部署说明可在我们之前的文章中找到。或者,如果您想通过 Kubernetes 进行部署,请在此处找到说明:here。
- 从 deepset Studio 部署(有限制)。立即注册。
- 如果您是 deepset Cloud 客户:直接从 deepset Studio 部署到deepset Cloud,这是一个完全托管的 AI 工作台。此选项使您能够与团队协作进行应用程序设计、评估应用程序并有效管理其部署。
摘要
设计 AI 应用的最终布局需要仔细集成多个组件,并且,重要的是,需要多次迭代。在本文中,我们看到了如何使用 deepset Studio 可视化地设计 AI 管道的架构。该工具允许您映射出 AI 工作流的整个结构——从数据摄感到检索——同时无缝集成来自 NVIDIA API 目录的 NVIDIA 托管模型 API 端点或自托管的 NIM 微服务。通过 deepset Studio,您可以在不妥协关键技术决策(包括语言模型的托管选项)的情况下可视化应用程序的架构。该工具允许您在编写代码之前,在可视化层中对复杂的管道架构进行推理。设计完成后,deepset Studio 使您能够部署和测试您的管道,或将其导出为 Python 代码或 YAML 定义,使其准备好进行部署。