

什么是文本向量化?您需要了解的一切
一篇关于文本向量化历史及其在语义搜索系统中的作用的指南
2021 年 12 月 3 日只要计算机存在,就一直存在如何以机器可以处理的方式表示数据的问题。在自然语言处理 (NLP) 中,我们经常谈论文本向量化——将单词、句子甚至更大的文本单元表示为向量(或“向量嵌入”)。其他数据类型,如图像、声音和视频,也可以被编码为向量。但这些向量到底是什么,以及如何在您自己的应用程序中使用它们?
在本篇文章中,我们将回顾机器学习中文本向量化的历史,以全面理解现代技术。我们将简要回顾传统的基于计数的方法,然后转向 Word2Vec 嵌入和 BERT 的高维向量。我们将讨论基于 Transformer 的语言模型如何为文本向量化带来深度语义,以及这对现代搜索系统意味着什么。最后,我们将探讨向量数据库的最新且令人兴奋的趋势。
基于计数的文本向量化:简单的开端
在编程中,向量是一种与列表或数组相似的数据结构。对于输入表示的目的,它只是值的序列,值的数量代表向量的“维度”。向量表示包含有关输入对象质量的信息。它们提供了一种计算机可以轻松处理的统一格式。
词袋模型
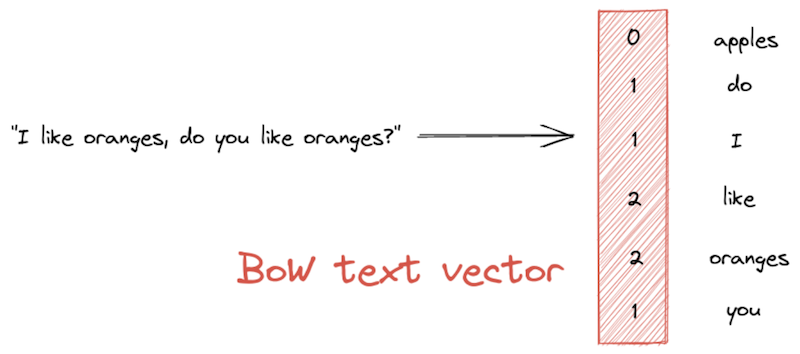
最简单的文本向量化方法之一是词袋模型(BoW)表示。BoW 向量的长度等于整个词汇表——即语料库中唯一单词的集合。向量的值表示每个单词在给定文本段落中出现的频率
TF-IDF
另一方面,加权的 BoW 文本向量化技术,如TF-IDF(“术语频率-逆文档频率”的缩写),试图为在语料库中较少文档中出现的单词赋予更高的相关性分数。为此,TF-IDF 衡量一个单词在文本中的频率与其在语料库中的总体频率的关系。
想象一篇频繁提及“橙子”一词的文档。TF-IDF 将会查看语料库中的所有其他文档。如果“橙子”在许多文档中出现,那么它不是一个非常重要的词,并且在 TF-IDF 文本向量中权重较低。然而,如果它只出现在少数文档中,那么它被认为是一个独特的词。在这种情况下,它有助于在语料库中表征文档,因此在向量中获得更高的值。
BM25
虽然比简单的 BoW 方法更复杂,但 TF-IDF 存在一些缺点。例如,它没有解决这样一个事实:在短文档中,即使只提及一个单词一次,也可能意味着该词具有高度相关性。BM25的引入是为了解决这个问题和其他问题。它是 TF-IDF 的改进,因为它考虑了文档的长度。它还减弱了文档中单词出现次数过多的影响。
由于 BoW 方法会产生包含许多零的长向量,因此它们通常被称为“稀疏”向量。除了语言无关之外,稀疏向量还易于计算和比较。语义搜索系统使用它们进行快速文档检索。
现在让我们看看一种更近期的编码技术,它旨在捕获单词的语义特性,而不仅仅是词汇特性。
Word2Vec:从上下文中推断含义
单词不仅仅是一堆字母。作为一种语言的使用者,我们可能理解一个单词的含义以及如何在句子中使用它。简而言之,我们理解它的语义。我们上面看到的稀疏、基于计数的方**法没有考虑我们的系统处理的单词或短语的含义**。
2013 年,由 NLP 研究员 Tomáš Mikolov 领导的团队提出了Word2Vec 方法,该方法可以通过“词嵌入”来表示单词的语义和句法属性。Word2Vec 的理念是,单词的含义在于其分布特性——即单词所使用的上下文。Word2Vec 有两种主要的实现(CBOW 和skip-gram)。两者都训练一个浅层神经网络,将单词表示为可变长度(通常为 300)的特征向量。这些向量是密集的,意味着它们主要由浮点值组成,而不是零。
在 Word2Vec 的高维嵌入空间中,相似的单词彼此靠近。例如,我们期望“橙子”和“苹果”这两个词彼此靠近,而“房子”或“宇宙飞船”应该离这对词更远。语义文本相似度通过距离度量来衡量,通常是余弦相似度。虽然在脑海中想象 300 维几乎是不可能的,但为了可视化目的,可以将嵌入降至二维,如这个交互式示例所示。
通常,我们希望对更长的文本段落(例如整个文档的句子)进行编码。我们可以添加或平均单个词向量来生成整个文本的一个向量。另一种方法是Doc2Vec模型,该模型经过训练,其方式类似于 Word2Vec,只是它是在文档而不是单词上进行训练的。
然而,尽管编码了单词的语义属性,但由此产生的文本向量化仍然有许多不足之处。例如,Word2Vec 编码是僵化的:给定一个单词,它总是以相同的方式编码,而不管它在句子中的位置,或者它是否具有多个含义。该模型也无法处理未知单词。
最后,基于 Word2Vec 的方法在表示较长文本段落方面并未取得太大成功。幸运的是,所有这些问题都已通过一种新的向量生成技术得到了及时解决:Transformer 驱动的 BERT。
Transformer:为文本向量化带来深度语义
Jacob Devlin 及其同事开发的传奇的BERT(“Transformer 的双向编码器表示”)语言模型克服了基于 Word2Vec 的嵌入方法带来的障碍。BERT 能够通过编码单词在文本中的位置以及单词本身来生成上下文相关的词向量。此外,这种方法还可以处理未知单词以及具有多种含义的单词。
BERT 的成功基于其Transformer 架构,以及它用于学习的海量数据。在训练过程中,BERT “阅读”了整个英语维基百科和 BooksCorpus(一个大型的未出版小说合集)。BERT 的后继者,例如RoBERTa,在更大的文本集合上进行训练。通过这种方式,基于 Transformer 的语言模型学习对语言的深度、上下文感知的表示。
语义搜索系统:通过高维向量实现更好的文档检索
在语义搜索系统的上下文中,我们需要一种方法来向量化我们文档存储中的文档以及我们想要匹配的查询。我们将介绍两种使用 Transformer 完成此任务的不同技术:Sentence-BERT 和 Dense Passage Retrieval。
Sentence-BERT(简称 SBERT)使用一个编码器,可以将较长的文本段落转换为向量。在语义文档搜索系统中,SBERT 为每个现有文档生成一个向量。这些向量随后与原始文档一起在数据库中进行索引。在推理时,SBERT 将新文档转换为向量,并将其与数据库中的向量进行比较。两个向量越相似,其底层文档就越相似。
Dense Passage Retrieval (DPR) 是问答系统领域中一种流行的文本向量化方法。它基于双编码器方法,可以检索可能包含给定问题答案的文档。以DPR 论文中的一个例子为例,查询“指环王中的坏蛋是谁?”被映射到句子“Sala Baker 因在《指环王》三部曲中扮演反派索伦而闻名。”
正如示例所示,DPR 能够配对问题和答案段落,即使它们没有使用完全相同的词语。该模型理解“坏蛋”是“反派”的同义词。这正是基于 Transformer 的方法与 TF-IDF 和 BM25 等关键字匹配技术不同之处。但是,SBERT 和 DPR 在索引时确实需要更长的时间。这是因为它们在将每个文档存储在数据库中并附带其高维向量表示之前,都会运行每个文档通过 Transformer 模型。
先向量化:向量数据库的力量
像Elasticsearch和OpenSearch这样流行的面向文档的数据库允许您存储和搜索您的向量化文本以及原始文档。这很有用,因为它允许您将基于关键字的方法与更新的、基于 Transformer 的方法结合起来。但随着数据集合的增长以及从词汇、基于关键字的搜索系统转向语义搜索系统,对专门为向量数据量身定制的数据库的需求越来越大。
最近,出现了一代新的数据库来满足这一需求。向量优化数据库专门为存储和搜索向量数据而设计。请注意,“数据”不仅仅意味着文本——其他数据类型,如图像或视频,也可以存储在向量数据库中。这些数据库在通过“最近邻”算法计算文本向量之间的相似性方面特别快。
向量数据库具有高度可扩展性,即使处理数百万文档也能实现快速搜索。Haystack 支持FAISS、Milvus和Weaviate向量数据库——我们迫不及待地想看看您将用它们构建什么!
开始使用 Haystack
Haystack是我们旗舰级的 NLP 框架,使开发人员能够为他们的应用程序添加各种现代 NLP 任务,例如语义搜索、问答和摘要。计算您自己的向量,将它们添加到您选择的数据库中,然后开始构建强大的自然语言处理管道。
立即通过查看我们的GitHub 存储库或加入我们的Discord社区来开始!
