

将 Gradient 模型与 Haystack Pipeline 结合使用
隆重推出新的 Haystack 集成,让您可以轻松地在 Gradient 平台上微调和部署模型,这些模型可以在 Haystack Pipeline 中使用。
2023 年 12 月 11 日创建 LLM 应用时,模型管理可能是比较棘手的一部分,尤其是在需要我们自己微调、托管和扩展模型的情况下。在这种情况下,拥有可用的选项会很有帮助。今天,我们扩展了 Haystack 2.0 生态系统,增加了一项新集成,可以帮助您实现这一点。
Gradient 是一个 LLM 开发平台,提供用于微调、嵌入和推理最先进的开源模型的 Web API。在本文中,我们将介绍 Haystack 的新 Gradient 集成,以及如何在您的检索增强生成 (RAG) Pipeline 中使用它。
您可以在此处找到一个 Colab 示例,该示例使用 Gradient 的嵌入和生成模型,针对 Notion 页面构建一个 RAG Pipeline。
Gradient 集成提供的功能
Haystack 的Gradient 集成附带了 Haystack Pipeline 的三个新组件:
GradientDocumentEmbedder:您可以使用此组件为文档创建嵌入。GradientTextEmbedder:您可以使用此组件为文本片段(例如查询)创建嵌入。GradientGenerator:您可以使用此组件使用 LLM 生成响应。
如何使用 Gradient 集成
Gradient 平台提供了一个嵌入 API 端点(撰写本文时,它支持 bge-large),以及 Llama-2、Bloom 等 LLM 的微调和部署(未来还将支持更多)。
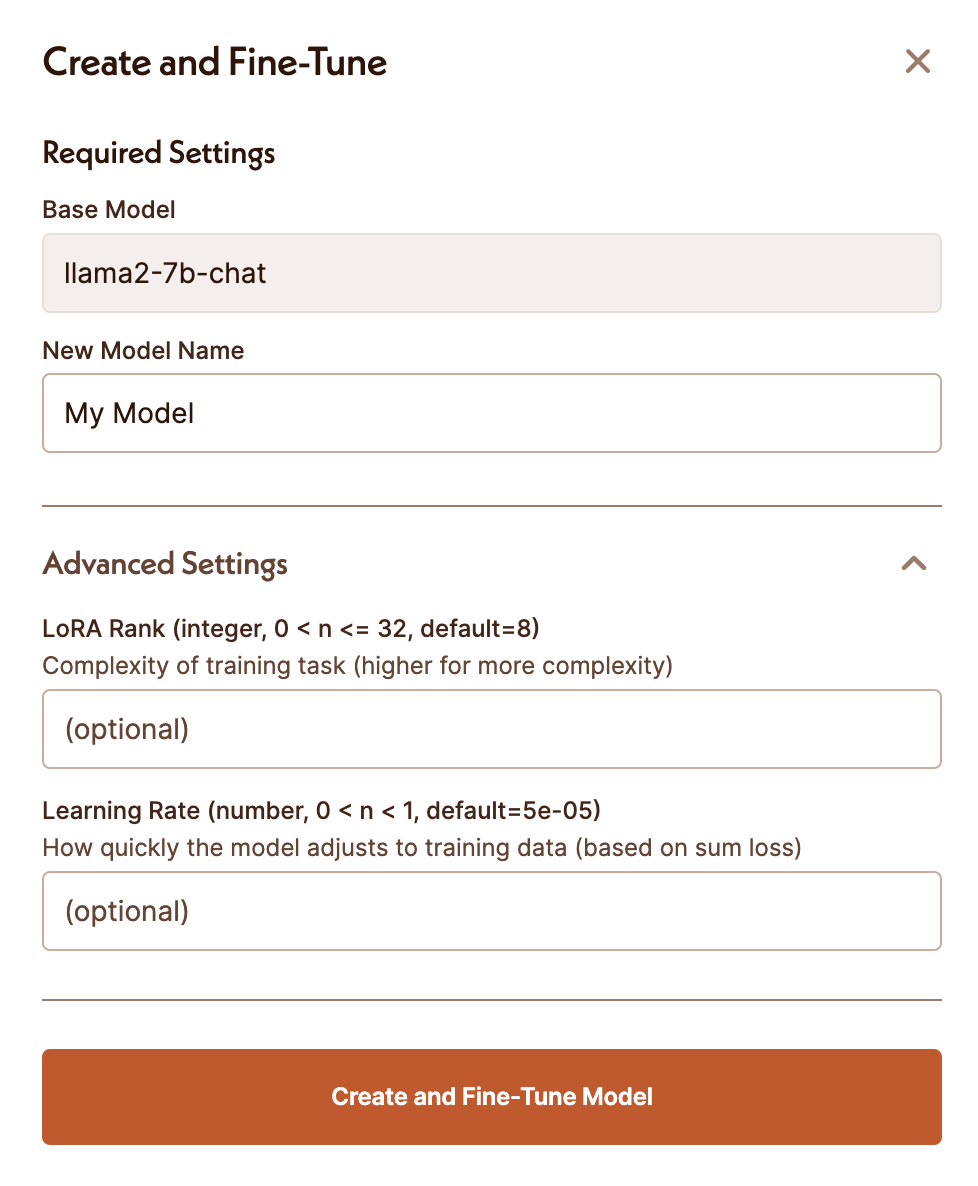
要通过 Gradient 微调和使用模型,第一步是创建一个工作区。

创建工作区后,您将能够选择一个基础模型并启动一个微调作业。
使用 GradientGenerator
您可以使用 GradientGenerator,它可以与 Gradient 提供的任何基础模型配合使用,或者与您在平台上微调过的模型配合使用。
例如,要使用 llama2-7b-chat 模型
os.environ["GRADIENT_ACCESS_TOKEN"] = "YOUR_GRADIENT_ACCESS_TOKEN"
os.environ["GRADIENT_WORKSPACE_ID"] = "YOUR_WORKSPACE_ID"
generator = GradientGenerator(base_model_slug="llama2-7b-chat",
max_generated_token_count=350)
或者,要使用您在 Gradient 平台上微调过的模型,请提供您的 model_adapter_id。
os.environ["GRADIENT_ACCESS_TOKEN"] = "YOUR_GRADIENT_ACCESS_TOKEN"
os.environ["GRADIENT_WORKSPACE_ID"] = "YOUR_WORKSPACE_ID"
generator = GradientGenerator(model_adapter_id="your_finetuned_model_adapter_id",
max_generated_token_count=350)
构建 RAG Pipeline
在本文中,我提供了一个Colab 示例,该示例使用 NotionExporter 集成,对您的私有 Notion 页面进行问题解答。我们使用 GradientDocumentEmbedder 组件为 Notion 页面创建嵌入,并将其索引到 InMemoryDocumentStore 中。至于 RAG Pipeline,您可以使用 GradientTextEmbedder 和 GradientGenerator 来:
- 嵌入用户查询,以从 Notion 页面中检索最相关的文档。
- 使用您自己从 Gradient 微调的 LLM 生成响应。
import os
from haystack.components.retrievers.in_memory import InMemoryEmbeddingRetriever
from haystack.components.builders import PromptBuilder
from haystack_integrations.components.embedders.gradient import GradientTextEmbedder
from haystack_integrations.components.generators.gradient import GradientGenerator
prompt = """ Answer the query, based on the
content in the documents.
Documents:
{% for doc in documents %}
{{doc.content}}
{% endfor %}
Query: {{query}}
"""
os.environ["GRADIENT_ACCESS_TOKEN"] = "YOUR_GRADIENT_ACCESS_TOKEN"
os.environ["GRADIENT_WORKSPACE_ID"] = "YOUR_WORKSPACE_ID"
text_embedder = GradientTextEmbedder()
retriever = InMemoryEmbeddingRetriever(document_store=document_store)
prompt_builder = PromptBuilder(template=prompt)
generator = GradientGenerator(model_adapter_id="your_finetuned_model_adapter_id",
max_generated_token_count=350)
rag_pipeline = Pipeline()
rag_pipeline.add_component(instance=text_embedder, name="text_embedder")
rag_pipeline.add_component(instance=retriever, name="retriever")
rag_pipeline.add_component(instance=prompt_builder, name="prompt_builder")
rag_pipeline.add_component(instance=generator, name="generator")
rag_pipeline.connect("text_embedder", "retriever")
rag_pipeline.connect("retriever.documents", "prompt_builder.documents")
rag_pipeline.connect("prompt_builder", "generator")
要运行此 Pipeline:
question = "What are the steps for creating a custom component?"
rag_pipeline.run(data={"text_embedder":{"text": question},
"prompt_builder":{"query": question}})
