

将 RAG 部署到生产环境
面向数据科学家的概述:如何将一个可用的原型转变为生产环境中的检索增强生成 AI 系统
2023 年 9 月 13 日作为数据科学家,我们通常已经掌握了原型制作的艺术。我们可以使用 Haystack 等机器学习框架来构建、测试和微调数据驱动的系统。我们是收集利益相关者反馈、量化反馈以及解读各种性能指标的专家。但是,当我们想将这些系统迁移到生产环境并向公众开放时,对我们许多人来说,这可能会变得很棘手。
借助 Haystack,开发人员可以在自己的文本数据库之上构建复杂的 LLM 管道,并使用最先进的工具:从对话式 AI 到语义搜索和摘要。如今,最受关注的架构之一是 RAG,即检索增强生成 AI。RAG 管道将生成式 LLM 的强大功能与您数据中包含的见解相结合,以创建真正有用的用户界面。要了解更多信息,请参阅我们在 The Deep Dive 上的博客文章《RAG》。
但部署到生产环境本身就是一门艺术。而且它可能令人望而生畏。一次成功的部署需要许多元素协同工作,每个元素都可能导致失败。幸运的是,在 deepset,我们拥有一支知识渊博的团队,他们定期将 Haystack 驱动的管道部署到生产环境。因此,在本文中,我将分享我从他们那里学到的经验——这样您就可以尽快将您的 RAG 系统投入生产。
从原型到生产
原型制作是构建系统版本的过程——通过迭代设计、部署和测试——直到您获得一个满足您的需求并有潜力在生产环境中产生真正价值的配置。虽然这个过程本身就充满挑战,但这仅仅是您系统生命周期的开始。
应用 AI 项目的第二步是将其部署到生产环境。坦率地说,这与开发环境的区别在于,可能出错的事情要多得多。这是因为我们无法控制有多少人会查询您的系统——并期望它能快速响应。我们也几乎无法知道人们何时会查询它。因此,您需要为应急情况做好计划,并构建一个可扩展(意味着其处理能力可以根据需要增长和收缩)且健壮(因此系统上的高负载不会导致其崩溃)的系统。
当您将系统部署到生产环境时,更难预测人们会将其用于何种目的。因此,您需要监控系统的性能并做出相应反应。但 LLM 的可观测性和管道监控是复杂的主题,我们将在下一篇博客文章中探讨。
用例
并非所有机器学习驱动的系统都相同。事实上,您可能会认为它们都不同——它们的性质取决于我们要解决的问题、管道设计、底层数据以及项目的规模。
让我们考虑一个使用 RAG 管道的中型项目。该管道连接到一个定期更新的数据存储。例如,这样的项目可以用于在线新闻环境,或者用于定期摄取公司报告的面向员工的系统。总之,我们的系统具有以下要求:
-
在首次构建时,它可以摄取大量文档(我们现有的在线新闻或公司报告集合)。
-
它可以定期(例如,每天或每当新文档到达时)使用其他较小的文档批次进行更新。
-
可以随时从用户界面(可能是浏览器)查询它。
虽然前两点由索引管道处理,但第二点由查询管道处理。在 Haystack 中,您可以在同一个 yaml 文件中定义两者。
移至生产环境
在将系统投入生产的过程中,您可以使用许多工具。确切的选择取决于您的需求和偏好——如果您之前部署过系统,您可能已经有了首选的设置。无论哪种方式,让我们盘点一下成功部署所需的要素:
-
一个生产就绪的托管数据库,例如 OpenSearch、Weaviate 或 Pinecone。使用第三方托管数据库的好处是,它们可以为您处理所有复杂的事务,如数据库维护和安全。
-
一个可以托管您的数据库和计算基础设施的服务器:您将需要 CPU 和 GPU——可能用于索引,肯定用于推理。云提供商有很多选择,选择您最熟悉的即可。最大的提供商是 AWS、Azure 和 GCP。
-
一个编排工具,如 Kubernetes(通常风格为 K8s),它与服务器(数据所在和管道运行的地方)和客户端(通过 REST API 发送请求的用户界面)进行通信。
-
在大多数实际项目中,您还想在将应用程序部署到外部服务器之前在本地进行测试。您可以使用 k3d 在本地 Kubernetes 环境中进行设置。它允许您在自己的机器上通过 docker 创建一个轻量级的 Kubernetes 集群。有关详细说明,请参阅 Kristof 的文章。
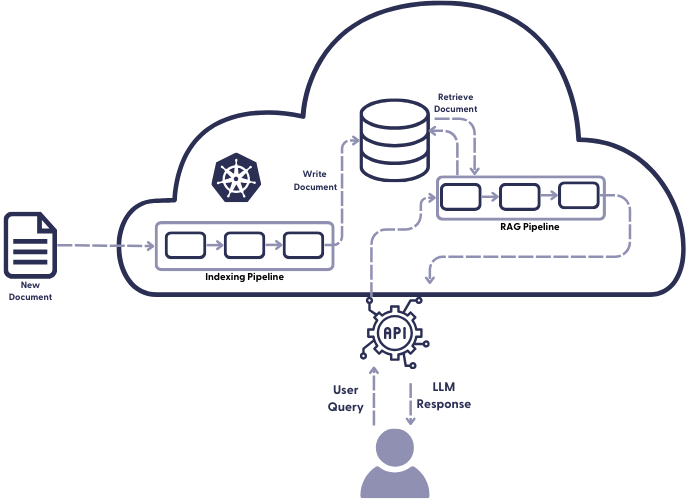
将索引管道部署到生产环境
索引是向数据库添加文档的过程。在生产环境中如何进行索引取决于您使用的是关键字检索器还是嵌入检索器(或两者都用,在混合检索设置中)。关键字检索器速度快,不需要任何特殊硬件。嵌入检索器则不同。
嵌入方法需要更多时间,因为它们必须将文档通过基于 Transformer 的语言模型进行处理。模型输出一个密集、语义丰富的向量,该向量被添加到数据库中,使其在后续的检索步骤中可供搜索。由于此步骤在计算上很昂贵,因此您需要使用 GPU 来加速它。
准备数据库
在索引过程中,文档及其相应的文本嵌入存储在数据库的内存中。在注册托管数据库之前,建议您至少大致了解您的文档和向量将占用多少空间。因为以后增加空间很麻烦——但购买过多空间然后不使用它可能会花费您数千欧元/美元/日元。因此,优化向量长度可以为您节省大量费用。
您需要的空间量在很大程度上取决于向量的长度。例如,Cohere 的巨型文本嵌入比我们通常在生产中使用的嵌入长五倍——因此需要五倍的空间。因此,优化向量长度可以为您节省大量费用。
在设置托管数据库时,您会遇到的另一个概念是“高可用性”。这指的是将文档存储在多个物理位置的一个以上的服务器上。这种冗余实践可确保即使一个服务器暂时或永久宕机,您的文档仍可用。
预处理和索引您的文档
在原型制作期间,您已经定义了索引管道,它指定了在将文档添加到数据库之前如何预处理它们。对于生产环境,您将把索引管道移到您的云提供商,在那里它将由 Kubernetes 部署在虚拟机上。将配置的所有详细信息(如文档存储的凭据、管道 yaml 本身以及管道和硬件的缩放规则)汇总到一个 Helm chart 中很有用。然后,Kubernetes 将根据 chart 中指定的设置部署您的系统。
如何将原始文件发送到您的外部服务很大程度上取决于您的应用程序和文件的来源。例如,您可以编写一个脚本,每天或每周在固定时间将文件批次发送到您的索引端点,或者您可以配置一个流,在文件到达时发送它们。当您期望索引新数据时,可以在 Kubernetes 中启用自动伸缩,它将创建可以并行运行的索引管道副本。
由于索引过程不如查询过程那样时间敏感,因此您可以将文件排队等待索引。队列用于确保请求几乎立即被接受,但可能在(不久的)将来被处理。要了解更多关于使用 KEDA 进行排队的信息,请参阅我们关于缩放索引管道的系列文章。
一旦您的文档嵌入准备就绪,服务就会将它们添加到数据库中,在那里它们现在可以被查询。
将查询管道部署到生产环境
与索引不同,查询对时间极其敏感。当用户查询您的 RAG 系统时,他们期望快速获得答案——即使是最轻微的延迟也可能导致他们放弃您的产品并转向别处。因此,至关重要的是,您的生产查询管道始终可用,并且能够一次处理大量查询。这意味着,除其他外,该管道必须能够按需扩展。
同样,Kubernetes 是我们的朋友。它通过 Haystack REST API 端点接收请求,并在有大量请求同时到来时创建查询管道的副本。它还确保这些管道副本在需要时具有必要的硬件资源。查询由管道处理,检索增强的、LLM 生成的响应会返回到您的应用程序,您的用户可以在其中与之交互。
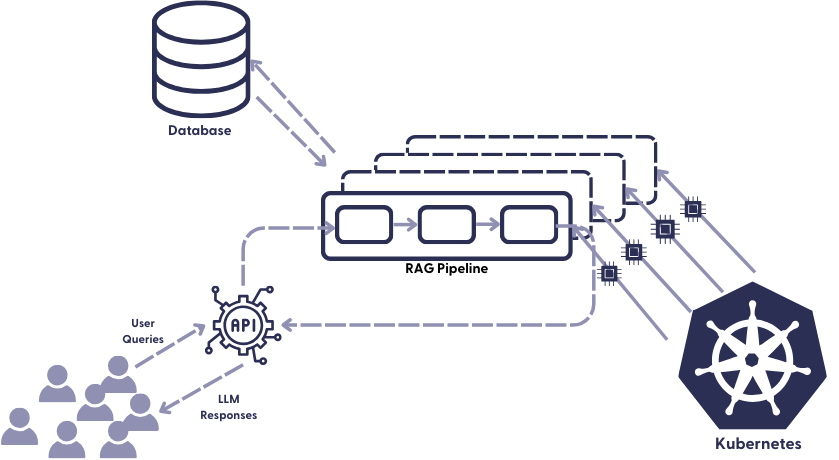
缩放的细节由我们的编排工具处理。此外,像 SageMaker 或 Hugging Face Inference 这样的模型托管服务可以帮助单独缩放模型推理。除了这些自动化解决方案之外,我们还可以自己调整管道的缩放。要做到这一点,最好考虑以下问题:
-
我希望每个副本同时处理多少个请求?
-
预期的峰值负载是多少?
-
为了降低成本,我们可以接受更高的延迟吗?
回答这些问题将有助于您优化设置并节省开支——但也不必过分担心这些设置,因为它们总是可以调整的。首先,您需要将系统投入生产,然后您可以对其进行监控和改进——更多信息将在下一篇博客文章中介绍。🙂
从 RAG 到财富
提供 LLM 的原型制作是一回事,而提供将系统投入生产所需的所有要素则是另一回事。只有后者才能真正帮助您的用户和客户在眨眼间获得有价值的见解。
Haystack 是供 AI 工程师和数据科学家构建和部署由最新 AI 驱动的生产就绪系统的框架。
您是否有兴趣了解更多关于使用 LLM 构建高级系统来解决实际用例的信息?也许您甚至正在构建和部署自己的自定义 RAG 系统?我们很想听听您的想法——加入 Haystack Discord,在那里我们可以讨论 LLM、检索增强以及更多内容。

