

使用 Amazon Bedrock 和 Haystack 进行基于 PDF 的问答
使用 Amazon Bedrock 为 PDF 文件创建定制的生成式问答应用程序
2024 年 1 月 17 日Amazon Bedrock 是一个全托管服务,通过单一 API 提供来自领先 AI 初创公司和亚马逊的高性能基础模型。您可以选择各种基础模型,找到最适合您用例的模型。
在本文中,我将指导您完成使用新添加的 Amazon Bedrock 与 Haystack 集成 以及 OpenSearch 高效存储文档的过程,以创建针对 PDF 文件定制的生成式问答应用程序。该演示将展示专门针对 Bedrock 文档设计的 QA 应用程序的逐步开发过程,从而在此过程中展示 Bedrock 的强大功能 🚀
Amazon Bedrock 的优势
- 它提供了对来自 AI21 Labs、Anthropic、Cohere、Meta 和 Stability AI 等领先 AI 初创公司以及 Amazon Titan 模型提供的各种基础模型的访问。
- 您可以使用 Amazon Bedrock无缝地试验不同的语言大模型 (LLM)。无需多个 API 密钥,只需修改模型名称,然后使用各种提示和配置测试您的应用程序,以确定最适合您特定用例的模型。
- Amazon Bedrock 不会使用您的提示和续写来训练 AWS 模型,也不会与第三方共享。 您的训练数据不会用于训练核心 Amazon Titan 模型或分发给外部。此外,其他使用数据(如时间戳和账户 ID)也不会用于模型训练。 来源
- 在原型开发阶段之后部署应用程序时,您无需管理用于托管模型的基础设施。Amazon Bedrock 会负责托管基础设施,提供无缝的部署体验。
设置 Amazon Bedrock
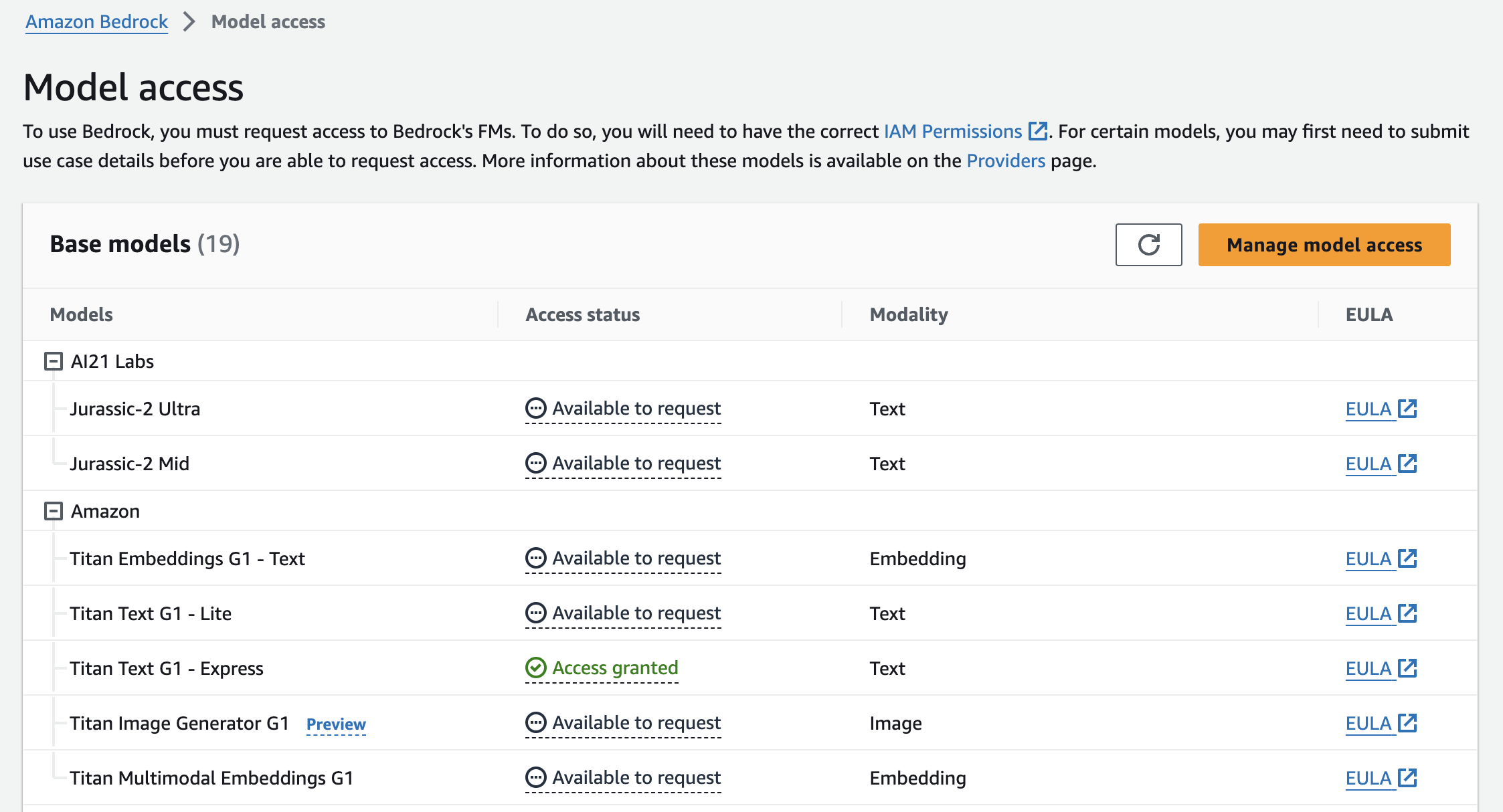
要使用 Amazon Bedrock,请先注册 AWS 账户。成功登录后,转到Amazon Bedrock 控制台即可开始。请注意,默认情况下,用户没有模型访问权限。您应从模型访问页面请求访问权限。对于此应用程序,我们将使用 Amazon 的“Titan Text G1 - Express”模型。不幸的是,Amazon Bedrock 没有免费套餐,因此您可能需要在此步骤中提供付款信息。
在此设置 Amazon Bedrock指南中了解有关该过程的更多信息。
API 密钥
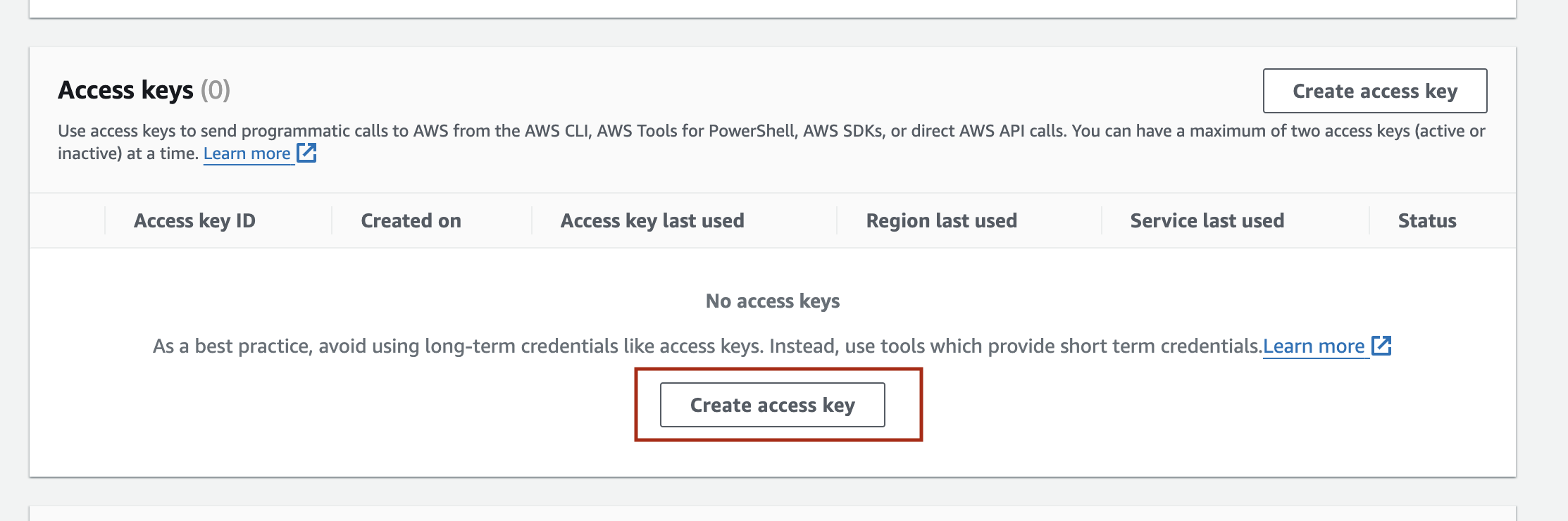
要使用 Amazon Bedrock,您需要 aws_access_key_id、aws_secret_access_key,并指明 aws_region_name。登录您的账户后,在“Security Credentials”(安全凭证)部分创建访问密钥。有关详细指导,请参阅有关管理 IAM 用户访问密钥的文档。
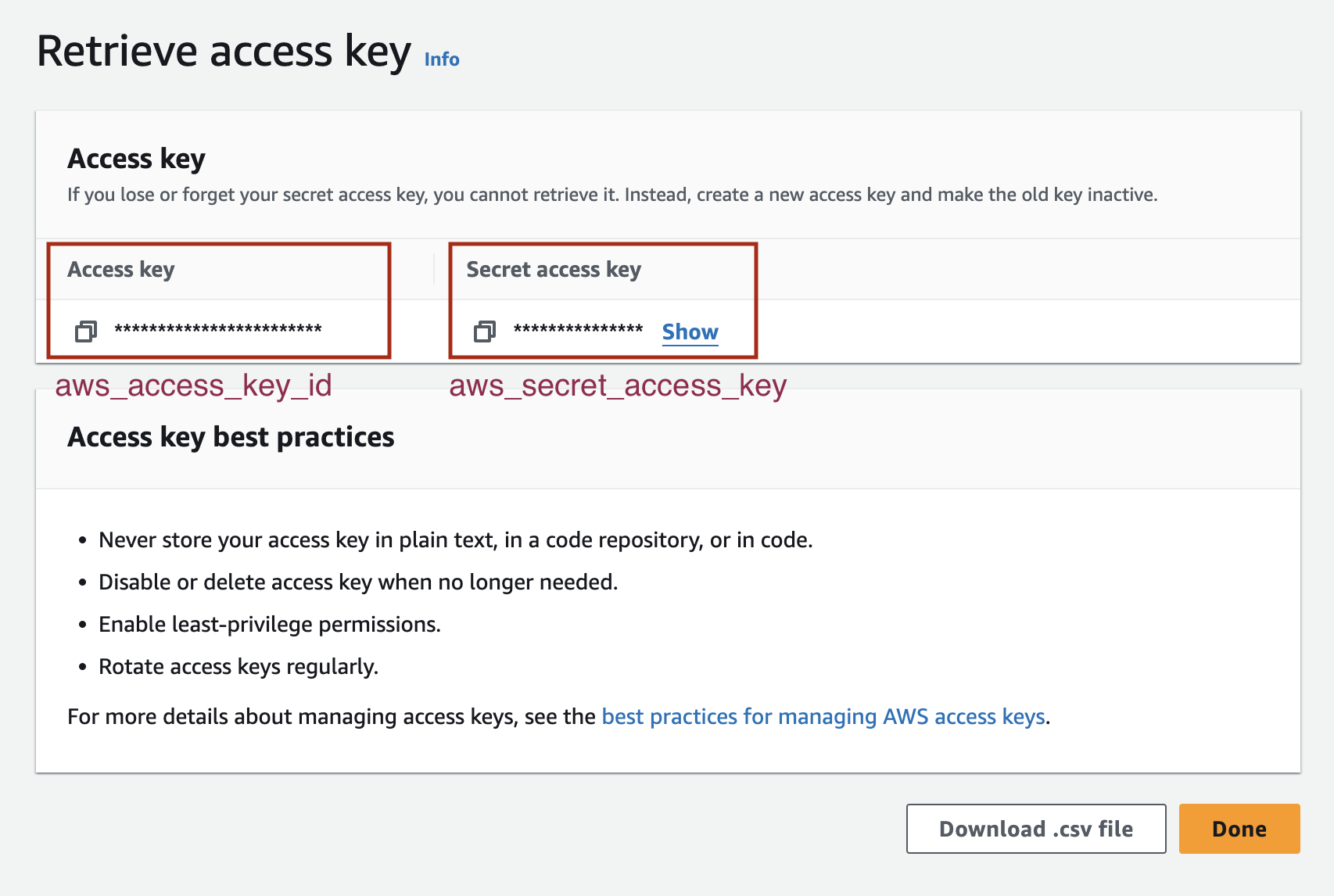
aws_access_key_id和aws_secret_access_key密钥开发环境
安装依赖项
让我们安装 Haystack 的 Amazon Bedrock 和 OpenSearch 集成,以及用于处理 PDF 文件的 pypdf 包。
pip install opensearch-haystack amazon-bedrock-haystack pypdf
下载文件
对于此应用程序,我们将使用 Amazon Bedrock 的用户指南。Amazon Bedrock 提供了其指南的PDF 版本。您可以从其来源下载 PDF,或通过运行下面的代码 👇🏼
import boto3
from botocore import UNSIGNED
from botocore.config import Config
s3 = boto3.client('s3', config=Config(signature_version=UNSIGNED))
# Download the PDF file from our s3 bucket to `/content/bedrock-documentation.pdf` directory
s3.download_file('core-engineering', 'public/blog-posts/bedrock-documentation.pdf', '/content/bedrock-documentation.pdf') #
初始化 OpenSearch 实例
OpenSearch 是一个完全开源的搜索和分析引擎,可与 Amazon OpenSearch Service 无缝集成,让您能够轻松部署、管理和扩展 OpenSearch 集群。要开始,请按照 OpenSearch 文档中提供的详细说明安装 OpenSearch 并启动一个实例。
以下是使用 Docker 启动 OpenSearch 的方法(推荐)
docker pull opensearchproject/opensearch:2.11.0
docker run -p 9200:9200 -p 9600:9600 -e "discovery.type=single-node" -e "OPENSEARCH_JAVA_OPTS=-Xms1024m -Xmx1024m" opensearchproject/opensearch:2.11.0
构建索引管道
我们的索引管道将使用 PyPDFToDocument 将 PDF 文件转换为 Haystack Document,并通过清理和分块对其进行预处理,然后将它们存储在 OpenSearchDocumentStore 中。
让我们运行下面的管道并将文件索引到我们的文档存储中
from pathlib import Path
from haystack import Pipeline
from haystack.components.converters import PyPDFToDocument
from haystack.components.preprocessors import DocumentCleaner, DocumentSplitter
from haystack.components.writers import DocumentWriter
from haystack.document_stores.types import DuplicatePolicy
from haystack_integrations.document_stores.opensearch import OpenSearchDocumentStore
## Initialize the OpenSearchDocumentStore
document_store = OpenSearchDocumentStore(hosts="https://:9200", use_ssl=True, verify_certs=False, http_auth=("admin", "admin"))
## Create pipeline components
converter = PyPDFToDocument()
cleaner = DocumentCleaner()
splitter = DocumentSplitter(split_by="sentence", split_length=10, split_overlap=2)
writer = DocumentWriter(document_store=document_store, policy=DuplicatePolicy.SKIP)
## Add components to the pipeline
indexing_pipeline = Pipeline()
indexing_pipeline.add_component("converter", converter)
indexing_pipeline.add_component("cleaner", cleaner)
indexing_pipeline.add_component("splitter", splitter)
indexing_pipeline.add_component("writer", writer)
## Connect the components to each other
indexing_pipeline.connect("converter", "cleaner")
indexing_pipeline.connect("cleaner", "splitter")
indexing_pipeline.connect("splitter", "writer")
运行管道以索引您想要的文件。
indexing_pipeline.run({"converter": {"sources": [Path("/content/bedrock-documentation.pdf")]}})
当您需要向文档存储添加其他文件时,用于将文件索引到文档存储的管道非常方便。如有必要,请随时使用新文档重新运行管道。
构建查询管道
让我们创建另一个管道来查询我们的应用程序。在此管道中,我们将使用 OpenSearchBM25Retriever 从 OpenSearchDocumentStore 中检索相关信息,并使用 Amazon Titan 模型 amazon.titan-text-express-v1 通过 AmazonBedrockGenerator 生成答案。您可以在支持的基础模型中找到其他模型选项。接下来,我们将使用检索增强生成 (RAG) 方法和 PromptBuilder 为我们的任务创建提示。此提示将有助于通过考虑提供的上下文来生成答案。最后,我们将连接这三个组件来完成管道。
from haystack.components.builders import PromptBuilder
from haystack.pipeline import Pipeline
from amazon_bedrock_haystack.generators.amazon_bedrock import AmazonBedrockGenerator
from haystack_integrations.components.retrievers.opensearch import OpenSearchBM25Retriever
## Create pipeline components
retriever = OpenSearchBM25Retriever(document_store=document_store, top_k=15)
## Set the AWS credentials as environment variables
os.environ["AWS_ACCESS_KEY_ID"] = "aws_access_key_id"
os.environ["AWS_SECRET_ACCESS_KEY"] = "aws_secret"
os.environ["AWS_REGION_NAME"] = "aws_region_name"
## Initialize the AmazonBedrockGenerator with an Amazon Bedrock model
generator = AmazonBedrockGenerator(model='amazon.titan-text-express-v1', max_length=500)
template = """
{% for document in documents %}
{{ document.content }}
{% endfor %}
Please answer the question based on the given information from Amazon Bedrock documentation.
{{question}}
"""
prompt_builder = PromptBuilder(template=template)
## Add components to the pipeline
rag_pipeline = Pipeline()
rag_pipeline.add_component("retriever", retriever)
rag_pipeline.add_component("prompt_builder", prompt_builder)
rag_pipeline.add_component("llm", generator)
## Connect components to each other
rag_pipeline.connect("retriever", "prompt_builder.documents")
rag_pipeline.connect("prompt_builder", "llm")
现在,提出您的问题,并使用 Amazon Bedrock 模型了解 Amazon Bedrock 服务!
question = "What is Amazon Bedrock??"
response = rag_pipeline.run({"retriever": {"query": question}, "prompt_builder": {"question": question}})
print(response["llm"]["replies"][0])
示例结果
Amazon Bedrock is a fully managed service that makes high-performing foundation models (FMs) from leading AI startups and Amazon available for your use through a unified API. You can choose from a wide range of foundation models to find the model that is best suited for your use case. Amazon Bedrock also offers a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI. Using Amazon Bedrock, you can easily experiment with and evaluate top foundation models for your use cases, privately customize them with your data using techniques such as fine-tuning and Retrieval Augmented Generation (RAG), and build agents that execute tasks using your enterprise systems and data sources.
With Amazon Bedrock's serverless experience, you can get started quickly, privately customize foundation models with your own data, and easily and securely integrate and deploy them into your applications using AWS tools without having to manage any infrastructure.
请记住,生成模型不是确定性的,您收到的响应可能会有所不同。
您可以尝试的其他问题
- 如何设置 Amazon Bedrock?
- 如何为 Amazon Titan 模型构建提示?
后续步骤
作为下一步,您可以随时通过索引其他文件或用您自己的数据替换现有文件来增强您的文档存储。
在此演示中,我们应用了 BM25 方法来生成文本向量。如果您想进一步改进应用程序,请选择一个 Embedder,并使用选定的嵌入模型为每个文件生成密集嵌入,然后再将其集成到文档存储中。
感谢您的关注!通过订阅我们的新闻通讯或加入我们的 Discord 社区,随时了解 Haystack 的最新动态。
