

使用 HyDE 优化检索
了解如何轻松将 HyDE 整合到 Haystack RAG pipeline 中以优化检索
2024 年 2 月 28 日假设文档嵌入 (HyDE) 是一种在论文“Precise Zero-Shot Dense Retrieval without Relevance Labels”中提出的技术,它通过根据给定查询生成“虚假”假设文档来改进检索,然后使用这些“虚假”文档的嵌入在相同的嵌入空间中检索相似的文档。
在本文中,我们将通过创建一个实现 HyDE 的自定义组件来了解如何在 Haystack 中实现和集成它。
要了解 HyDE 的工作原理以及其适用场景,请查看我们的指南:假设文档嵌入 (HyDE)
构建一个生成假设文档嵌入的 Pipeline
首先,让我们构建一个简单的 pipeline 来生成这些假设文档。为此,我们将使用以下 Haystack 组件:
-
PromptBuilder和OpenAIGenerator来查询指令遵循语言模型并生成假设文档。 -
SentenceTransformersDocumentEmbedder将假设文档编码为向量嵌入。 -
OutputAdapter用于调整Generator的输出,使其与SentenceTransformersDocumentEmbedder的输入兼容,后者期望List[Document]
要使用
OpenAIGenerator,您需要设置您的OPENAI_API_KEYexport OPENAI_API_KEY="secret_string"
我们首先构建一种查询指令遵循语言模型以生成假设文档的方法。
from haystack.components.generators.openai import OpenAIGenerator
from haystack.components.builders import PromptBuilder
generator = OpenAIGenerator(model="gpt-3.5-turbo",
generation_kwargs={"n": 5, "temperature": 0.75, "max_tokens": 400},
)
template="""Given a question, generate a paragraph of text that answers the question.
Question: {{question}}
Paragraph:"""
prompt_builder = PromptBuilder(template=template)
这将输出一个包含 5 个假设文档的列表,这与作者在论文中进行实验时使用的数量相同。然后,我们使用 SentenceTransformersDocumentEmbedder 将这些假设文档编码为嵌入。
但是,SentenceTransformersDocumentEmbedder 期望的输入是 List[Document] 对象,因此我们需要调整 OpenAIGenerator 的输出,使其与 SentenceTransformersDocumentEmbedder 的输入兼容。为此,我们使用带有 custom filter 的 OutputAdapter。
from haystack import Document
from haystack.components.converters import OutputAdapter
from haystack.components.embedders import SentenceTransformersDocumentEmbedder
from typing import List
adapter = OutputAdapter(
template="{{answers | build_doc}}",
output_type=List[Document],
custom_filters={"build_doc": lambda data: [Document(content=d) for d in data]}
)
embedder = SentenceTransformersDocumentEmbedder(model="sentence-transformers/all-MiniLM-L6-v2")
embedder.warm_up()
我们现在可以创建一个自定义组件 HypotheticalDocumentEmbedder,它接受 documents 并返回一个 hypotethetical_embeddings 列表,该列表是“假设”(虚假)文档嵌入的平均值。
from numpy import array, mean
from haystack import component
@component
class HypotheticalDocumentEmbedder:
@component.output_types(hypothetical_embedding=List[float])
def run(self, documents: List[Document]):
stacked_embeddings = array([doc.embedding for doc in documents])
avg_embeddings = mean(stacked_embeddings, axis=0)
hyde_vector = avg_embeddings.reshape((1, len(avg_embeddings)))
return {"hypothetical_embedding": hyde_vector[0].tolist()}
现在我们可以将所有这些组件添加到 pipeline 中并生成假设文档嵌入。
from haystack import Pipeline
hyde = HypotheticalDocumentEmbedder()
pipeline = Pipeline()
pipeline.add_component(name="prompt_builder", instance=prompt_builder)
pipeline.add_component(name="generator", instance=generator)
pipeline.add_component(name="adapter", instance=adapter)
pipeline.add_component(name="embedder", instance=embedder)
pipeline.add_component(name="hyde", instance=hyde)
pipeline.connect("prompt_builder", "generator")
pipeline.connect("generator.replies", "adapter.answers")
pipeline.connect("adapter.output", "embedder.documents")
pipeline.connect("embedder.documents", "hyde.documents")
query = "What should I do if I have a fever?"
result = pipeline.run(data={"prompt_builder": {"question": query}})
下面是我们创建的 pipeline 的图形表示:
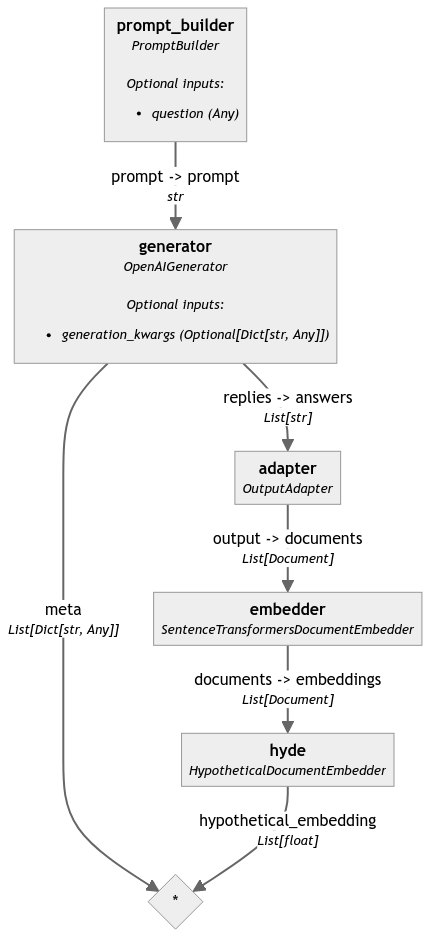
构建一个完整的 HyDE 组件
可选地,我们也可以创建一个 HypotheticalDocumentEmbedder,它封装了我们上面看到的整个逻辑。这样,我们就可以使用这个组件来改进检索。
该组件可以执行几项操作:
- 允许用户选择生成假设文档的 LLM
- 允许用户使用
nr_completions定义应创建的文档数量 - 允许用户定义他们想要用来生成 HyDE 嵌入的嵌入模型。
from haystack import Pipeline, component, Document, default_to_dict, default_from_dict
from haystack.components.converters import OutputAdapter
from haystack.components.embedders.sentence_transformers_document_embedder import SentenceTransformersDocumentEmbedder
from haystack.components.generators.openai import OpenAIGenerator
from haystack.components.builders import PromptBuilder
from typing import Dict, Any, List
from numpy import array, mean
from haystack.utils import Secret
@component
class HypotheticalDocumentEmbedder:
def __init__(
self,
instruct_llm: str = "gpt-3.5-turbo",
instruct_llm_api_key: Secret = Secret.from_env_var("OPENAI_API_KEY"),
nr_completions: int = 5,
embedder_model: str = "sentence-transformers/all-MiniLM-L6-v2",
):
self.instruct_llm = instruct_llm
self.instruct_llm_api_key = instruct_llm_api_key
self.nr_completions = nr_completions
self.embedder_model = embedder_model
self.generator = OpenAIGenerator(
api_key=self.instruct_llm_api_key,
model=self.instruct_llm,
generation_kwargs={"n": self.nr_completions, "temperature": 0.75, "max_tokens": 400},
)
self.prompt_builder = PromptBuilder(
template="""Given a question, generate a paragraph of text that answers the question.
Question: {{question}}
Paragraph:
"""
)
self.adapter = OutputAdapter(
template="{{answers | build_doc}}",
output_type=List[Document],
custom_filters={"build_doc": lambda data: [Document(content=d) for d in data]},
)
self.embedder = SentenceTransformersDocumentEmbedder(model=embedder_model, progress_bar=False)
self.embedder.warm_up()
self.pipeline = Pipeline()
self.pipeline.add_component(name="prompt_builder", instance=self.prompt_builder)
self.pipeline.add_component(name="generator", instance=self.generator)
self.pipeline.add_component(name="adapter", instance=self.adapter)
self.pipeline.add_component(name="embedder", instance=self.embedder)
self.pipeline.connect("prompt_builder", "generator")
self.pipeline.connect("generator.replies", "adapter.answers")
self.pipeline.connect("adapter.output", "embedder.documents")
def to_dict(self) -> Dict[str, Any]:
data = default_to_dict(
self,
instruct_llm=self.instruct_llm,
instruct_llm_api_key=self.instruct_llm_api_key,
nr_completions=self.nr_completions,
embedder_model=self.embedder_model,
)
data["pipeline"] = self.pipeline.to_dict()
return data
@classmethod
def from_dict(cls, data: Dict[str, Any]) -> "HypotheticalDocumentEmbedder":
hyde_obj = default_from_dict(cls, data)
hyde_obj.pipeline = Pipeline.from_dict(data["pipeline"])
return hyde_obj
@component.output_types(hypothetical_embedding=List[float])
def run(self, query: str):
result = self.pipeline.run(data={"prompt_builder": {"question": query}})
# return a single query vector embedding representing the average of the hypothetical document embeddings
stacked_embeddings = array([doc.embedding for doc in result["embedder"]["documents"]])
avg_embeddings = mean(stacked_embeddings, axis=0)
hyde_vector = avg_embeddings.reshape((1, len(avg_embeddings)))
return {"hypothetical_embedding": hyde_vector[0].tolist()}
使用 HypotheticalDocumentEmbedder 进行检索
最后一步,让我们看看如何在新组件中用于检索 pipeline。首先,我们可以创建一个包含一些数据的文档存储。
from datasets import load_dataset, Dataset
from haystack import Pipeline, Document
from haystack.components.embedders import SentenceTransformersDocumentEmbedder
from haystack.components.preprocessors import DocumentCleaner, DocumentSplitter
from haystack.components.writers import DocumentWriter
from haystack.document_stores.in_memory import InMemoryDocumentStore
embedder_model = "sentence-transformers/all-MiniLM-L6-v2"
def index_docs(data: Dataset):
document_store = InMemoryDocumentStore()
pipeline = Pipeline()
pipeline.add_component("cleaner", DocumentCleaner())
pipeline.add_component("splitter", DocumentSplitter(split_by="sentence", split_length=10))
pipeline.add_component("embedder", SentenceTransformersDocumentEmbedder(model=embedder_model))
pipeline.add_component("writer", DocumentWriter(document_store=document_store, policy="skip"))
pipeline.connect("cleaner", "splitter")
pipeline.connect("splitter", "embedder")
pipeline.connect("embedder", "writer")
pipeline.run({"cleaner": {"documents": [Document.from_dict(doc) for doc in data["train"]]}})
return document_store
data = load_dataset("Tuana/game-of-thrones")
doc_store = index_docs(data)
现在我们已经填充了包含数据的 InMemoryDocumentStore,让我们看看如何使用 HypotheticalDocumentEmbedder 作为检索文档的方法 👇
from haystack.components.retrievers.in_memory import InMemoryEmbeddingRetriever
def retriever_with_hyde(doc_store):
hyde = HypotheticalDocumentEmbedder(instruct_llm="gpt-3.5-turbo", nr_completions=5)
retriever = InMemoryEmbeddingRetriever(document_store=doc_store)
retrieval_pipeline = Pipeline()
retrieval_pipeline.add_component(instance=hyde, name="query_embedder")
retrieval_pipeline.add_component(instance=retriever, name="retriever")
retrieval_pipeline.connect("query_embedder.hypothetical_embedding", "retriever.query_embedding")
return retrieval_pipeline
retrieval_pipeline = retriever_with_hyde(doc_store)
query = "Who is Araya Stark?"
retrieval_pipeline.run(data={"query_embedder": {"query": query}, "retriever": {"top_k": 5}})
总结
如果您看到了这里,您就知道了 HyDE 技术的使用方法以及如何轻松地将其集成到 Haystack 中。要了解有关 Haystack 的更多信息,请加入我们的 Discord 或注册我们的月度通讯。
