

混合文档检索
为什么只用一个检索器,而不是两个?
2023年8月22日文档检索是从语料库中响应输入提取相关文档的艺术。就像当今许多与语言相关的任务一样,它可以从编码器模型生成的密集、语义嵌入中受益匪浅。这些模型已学会将文档嵌入到捕捉其内容的抽象向量空间中,使用户能够自由地使用自然语言表达查询,而不是尝试匹配文档中包含的确切关键字。
然而,在许多情况下,更基础的、基于关键字的方法可以优于语义方法。例如,BM25 等基于关键字的方法已被证明在域外设置中表现更好。
这是因为密集编码器模型需要使用数据进行训练,如果这些数据与手头的用例差异太大,它们可能会表现不佳。因此,在实践中,对于高度技术性或“小众”用例,关键字方法可以比未经微调的编码器模型产生更好的结果。
由于这两种方法都有其优缺点,因此最好将它们结合起来。您只需要两个检索器,并且有一种方法可以合并它们的输出。我们还建议在它们之上使用一个排序器。正如您将看到的,Haystack 可以轻松地将所有这些组件模块化且可重用地组合在一起。
回顾:什么是文档检索,我们为什么关心它?
在大型 NLP 系统中,我们经常处理海量文档集合。现在,当我们向这样的系统传递查询时,会发生什么?运行计算密集型语言模型——例如生成式 AI 或抽取式问答中使用的模型——处理整个语料库是不可行的。这样做将浪费资源和时间。解决方案?检索器。
检索器利用不同的文档搜索技术从数据库中提取正确的文档。在文档搜索中,每个文档都表示为一个向量。因此,检索模块只需要处理每个文档的一个嵌入。这是一种非常高效的方式,可以预先选择正确的文档以供后续处理。
检索器本身就很有用,因为它们驱动着大多数搜索应用程序。但它们最常在复合系统或管道的上下文中讨论。作为预选机制,检索器会响应查询提取相关文档。然后,它们将这些文档传递给下游任务,例如抽取式 QA、生成式 AI(在所谓的RAG 场景中)或摘要。
有哪些类型的检索器?
检索器大致可分为两类:一方面是稀疏的、基于关键字的方法(类似于 Tf-Idf),另一方面是密集的、基于嵌入的方法,它使用 Transformers。
稀疏方法的特点
稀疏检索器产生的向量长度等于词汇表的大小。由于语料库中的每个文档只包含语料库中所有单词的一小部分,因此这些向量通常是稀疏的:长,有很多零,只有少数非零值。如今最常用的稀疏检索算法是 BM25,它是经典 Tf-Idf 的改进版本。
稀疏嵌入技术在定义上是词汇性的:它们只能表示和匹配词汇表中存在的单词。它们不需要任何训练,因此它们是语言和领域无关的。
密集方法的特点
与稀疏方法最大的区别在于,密集检索器需要数据和训练。在训练过程中,语言模型会从数据本身学习如何最好地将文档嵌入为向量。
密集检索器产生的向量比其稀疏对应项短。这些压缩向量主要由标量值组成,它们表示语义特征而不是词汇出现。模型在训练过程中获得的特征比稀疏特征更难解释。
由于密集检索器模型已学会表示其训练数据,因此它们在任何超出该数据域的用例上都可能表现不佳。例如,在维基百科文章上训练的嵌入模型可能无法妥善处理推文:使用的语言差异太大。同样,在金融数据上训练的模型也无法很好地处理医疗报告。
虽然总是可以微调现有模型,但这需要数据、资源和专业知识。
合并密集和稀疏检索器
为了弥补两种检索器的缺点(或者更积极地利用两者的优点),我们可以在管道中简单地使用两个检索器并合并它们的输出。在 Haystack 这样的模块化框架中,可以轻松设置这样的混合检索管道。
Haystack 中的混合检索管道
Haystack 使用模块化管道和节点来确保轻松定制。基本的检索器管道包括输入(查询)、检索器节点、可选的附加节点和输出。
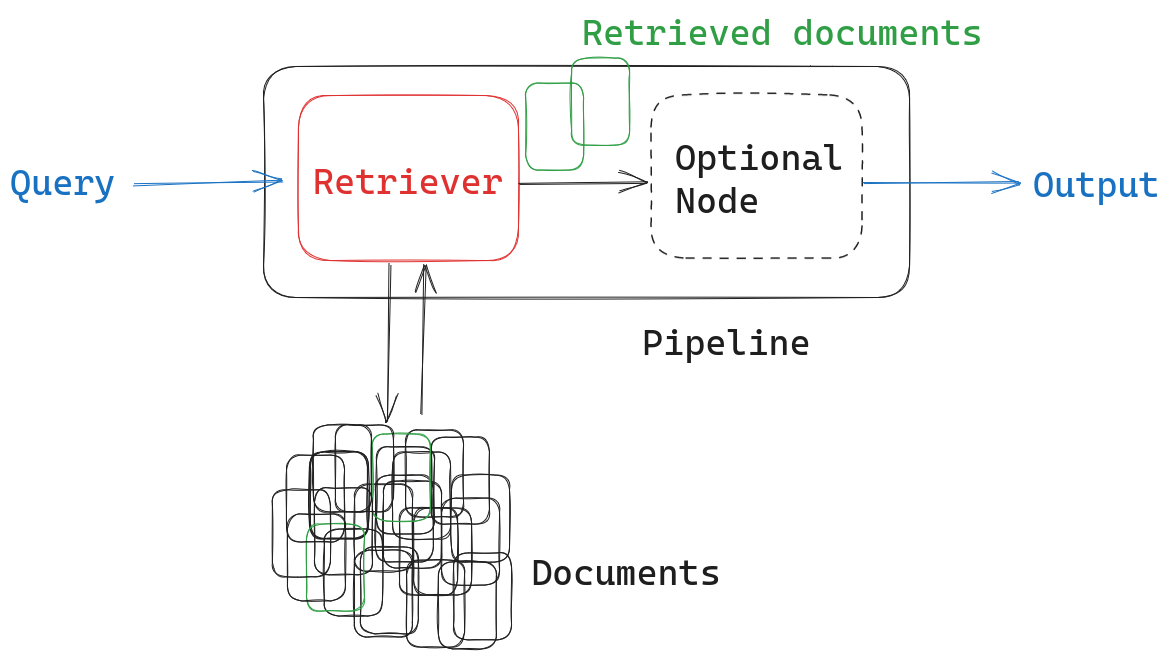
但是,我们可以轻松地自定义管道,使其包含两个检索器节点而不是一个。我们只需要记住以有意义的方式合并两种方法检索到的文档。为此,我们将首先使用JoinDocuments 节点
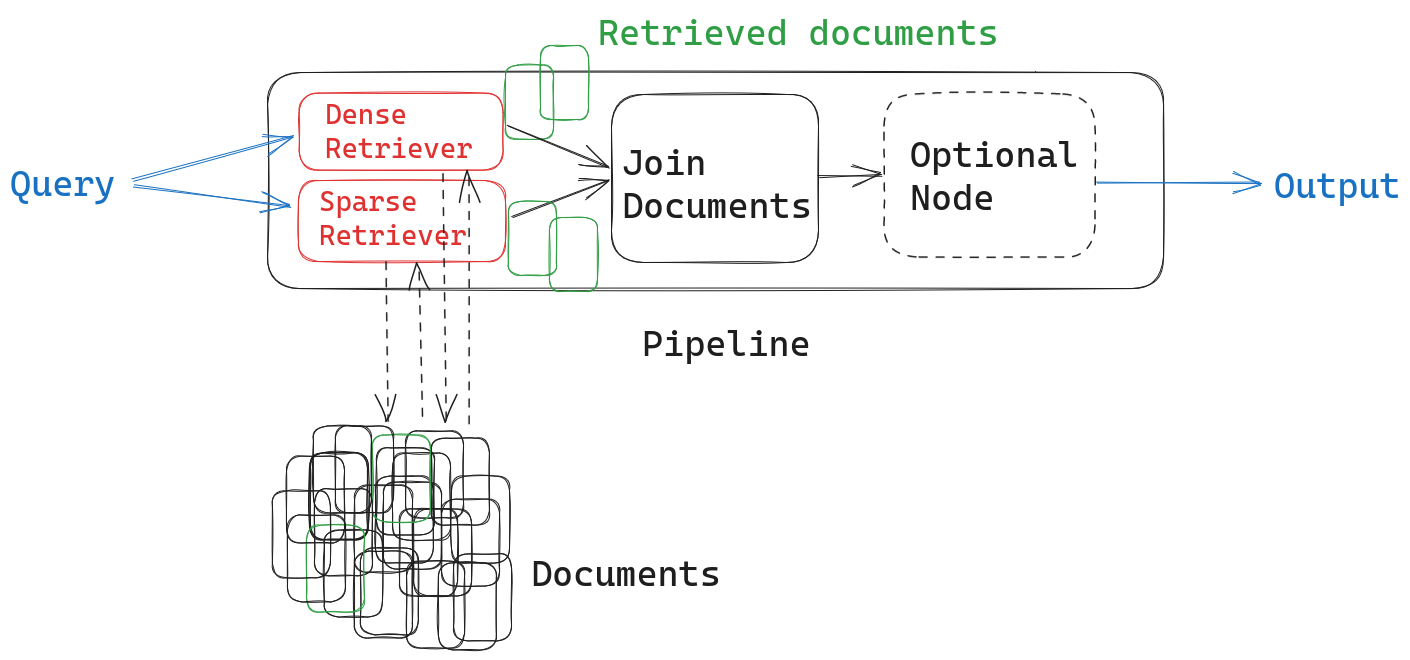
两种检索器都会返回带有相关性分数的结果排序列表(请注意,由于它们使用不同的评分技术,因此在混合检索设置中,分数实际上没有意义)。您可以使用不同的方法来合并这些结果列表。您使用哪种方法,以及是否在 JoinDocuments 节点之上添加另一个模块,取决于您的用例。
-
连接:所有文档(不重复)都会简单地附加到最终结果列表中。如果您打算使用所有结果并且不关心它们的顺序,则此方法就足够了。例如,在抽取式问答管道中可能会出现这种情况。连接也可以与强大的排序模型结合使用——稍后将对此进行更多介绍。
-
倒数排名融合 (RRF):此公式对两种检索器返回的文档进行重新排序,优先处理同时出现在两个结果列表中的文档。其目的是将最相关的文档排在列表顶部。如果结果的顺序很重要,或者您只想将部分结果传递给下一个节点,它会很有用。
-
合并:文档根据检索器返回的分数进行排名。如果您想优先考虑一个检索器的结果而不是另一个检索器的结果,并且检索器的相关性分数是可比的,那么此方法很有用。例如,如果您想合并来自两个不同密集检索器的文档,因为它们从不同的文档存储区返回文档。此选项不适用于混合检索。
根据您的应用程序,现在可以选择在合并文档后添加一个中间排名步骤。这是对两种不同检索器返回的文档进行排序的最复杂的方法。例如,如果您的管道在下一个节点使用生成式 LLM 或摘要器,您可以重新排序您的文档,以确保最相关的文档排在最前面以获得更好的结果。
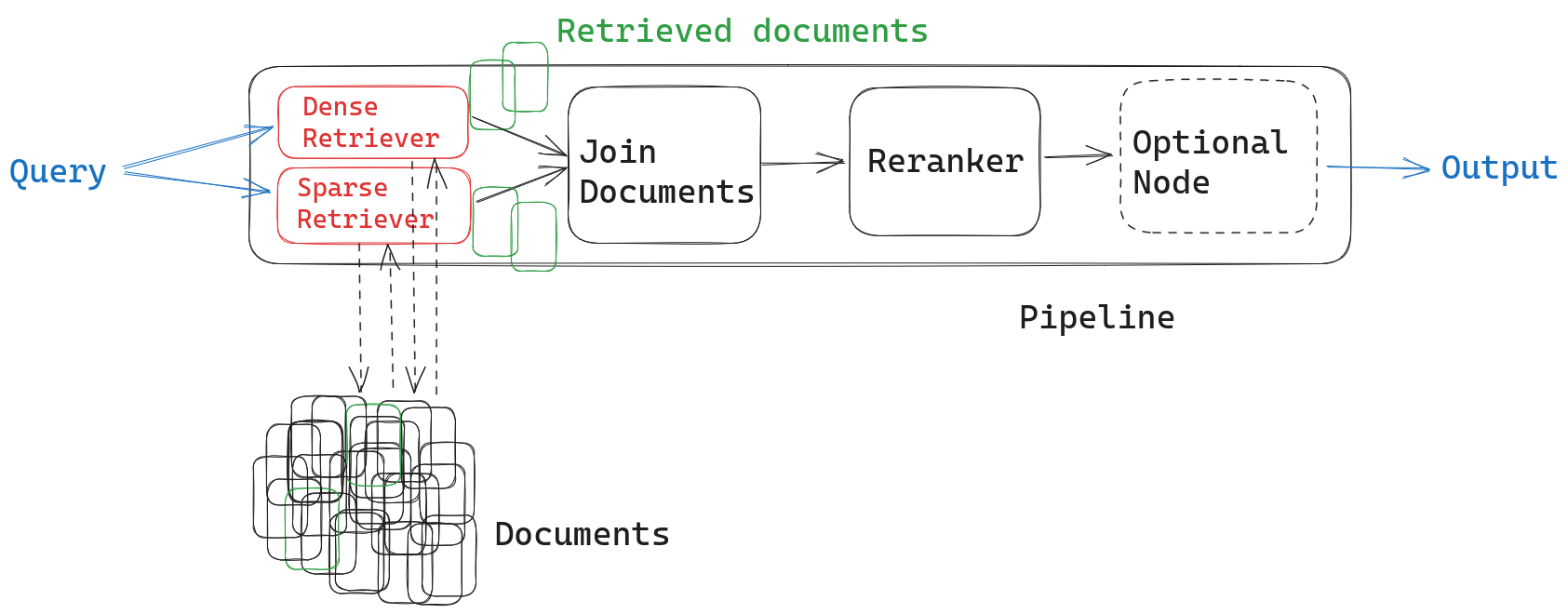
添加SentenceTransformersRanker 节点可以产生最相关的结果,同时也会增加一些延迟。它使用一个强大的交叉编码器,该编码器经过训练,可以确定文档与给定查询的相关性——类似于密集检索器的嵌入模型,但架构略有不同。
与用于检索的嵌入模型不同,排名器只能有效地处理少量文档,因此它特别适合作为检索器之后的评分机制。它不仅可以使两种检索器的结果以更有意义的顺序排列,还可以标准化文档的相关性分数,从而可以使用这些分数进行进一步的下游任务。
通过 Haystack 实现卓越搜索
为了获得混合检索的实践经验,请查看来自我们社区成员 Nicola 的教程。在 Colab 或您的 IDE 中进行操作,看看如何仅用几行代码就能构建一个混合检索管道!
Haystack 是开发人员构建强大但易于定制的自然语言搜索系统的首选框架,该系统利用来自任何来源的最先进语言模型。
加入我们友好的 Discord 社区,以获得有关 Haystack 和一般开源 NLP 的问题帮助,以及关于最新 LLM 的有趣讨论。让我们一起创造一些令人惊叹的东西!🚀
