

如何在 Python 中构建语义搜索引擎
使用开源工具以最有效的方式搜索您的海量文档集合
2022 年 11 月 23 日语义搜索的任务是根据自然语言提出的查询,从文档集合(也称为“语料库”)中检索文档。语义搜索由最新的 Transformer 语言模型提供支持,可让您在几秒钟内从文档集合中访问最佳匹配项,其依据是含义而非关键字匹配。语义搜索本身很有用,同时它也是许多复杂任务(如问答或文本摘要)的基础。
在过去的十年左右,Python 已成为机器学习(ML)和自然语言处理(NLP)的主要语言。在本文中,我们将展示如何使用我们开源的 Haystack 框架,在您选择的文档集合之上设置一个 Python 语义搜索引擎。借助 Haystack 的模块化设置和高质量预训练语言模型的可用性,您可以在不到二十分钟的时间内设置自己的 语义搜索 系统。
语义搜索的复习
与所有 基于 Transformer 的语言模型一样,语义搜索中使用的模型将文本(文档和查询)编码为高维向量或嵌入。然后,我们可以使用余弦相似度等相似性度量来理解两个向量(及其关联文本)在含义上有多接近。含义相似的文本彼此更接近,而不相关的文本则更远。虽然人类难以理解,但 基于向量的表示 非常适合计算机表示含义。
如果看一个例子,我们就能清楚地看到 语义搜索 在基于关键字的方法上的优越性。考虑查询“为什么我无法提交更改”(这是新手 Git 用户的一个长期问题)和“为什么我无法进行更改”(这是犹豫不决的人遇到的问题)之间的区别。“to”这个介词完全改变了查询的含义,而这仅凭关键字匹配是无法检测到的。语义语言模型(如 Google 使用的)会将这两个查询嵌入到向量空间的不同位置。

语义搜索非常适合区分此类细微差别。以下是一些语义搜索将特别有用的场景:
- 当您的应用程序正在搜索大量或模糊的语料库时。许多异构语料库给简单的关键字匹配带来问题。想象一下比较不同航空公司之间的奖励计划。每 家 公司 都有 不同的 术语来描述其客户货币和回扣计划。其中许多术语借鉴了像里程、积分或奖励这样的常见概念。语义搜索引擎可以轻松地捕获这些术语的相似性,而精确的文本匹配则不能。
- 当您的用户通过关键字找不到他们想要的内容时。 在关键字匹配系统中,良好的结果取决于语料库和查询之间的精确匹配。当用户无法找到高质量的搜索结果时,他们常常痛苦地迭代搜索词,寻找正确的组合来解锁语料库。这是一种糟糕的用户体验,可以被更舒适、更自然的语义搜索模型所取代。
- 当您想为用户提供更直观的搜索界面时。 语义搜索在筛选文档时更为舒适和愉快。人类的思维以人类的语言进行,而大多数人在不必将自己的语言适应计算机时会感觉更好。
现在,让我们看看 Haystack 和 Python 如何仅用几行代码就能构建语义搜索系统。
Haystack: Python 中的应用 NLP
Haystack 是我们用于应用 NLP 的框架,它采用模块化、混合搭配的方法来构建 NLP 系统。如今,性能最高的语言模型非常庞大。在本地 PC 上自己训练这种语言模型是不切实际、不经济的,而且坦率地说,通常是不可能的。然而,得益于 Hugging Face 模型中心 等集中式平台,预训练模型可以被所有人共享和重用。
由于预训练模型随处可用,Haystack 框架提供了实际应用它们的架构:Python 库附带了几个 现成的管道,您只需要插入适合您的语言模型即可。这使得快速构建原型系统变得容易,并可以使用不同的模型。同时,Haystack 提供了我们期望从 Python 库中获得的所有灵活性,使得配置和自定义您自己的管道变得极其容易。
我们的管道本质上是由边连接的节点。一个节点可以包含一个特定的语言模型,该模型在将输入传递给下一个节点之前会对其进行转换。一旦您决定了最适合您用例的管道设置,您就可以轻松地迭代不同的语言模型,以找到能为您提供最佳结果的组合。请注意,每当您更改模型组合时,都需要从头开始初始化管道。
构建语义搜索引擎:先决条件
要构建一个语义搜索原型,请提前考虑三个方面:您想搜索哪些文档、您的管道设计以及使用哪些语言模型(通常,您会有一些模型想要相互比较)。
在本指南的上下文中,假设您有一些园艺工作要做,并且您已经获得了一个 电子手册语料库,应该可以帮助您找到不同任务的最佳工具。不幸的是,文档太多,无法手动查看。如果您对园艺术语不太熟悉,基于关键字的搜索可能只会取得适度的成功。
您可以尝试不同的语义搜索系统管道设计。首先,尝试使用基础的、现成的 DocumentSearch 管道,它只包含一个节点:检索器,它从您的文档集合中提取最佳匹配项。
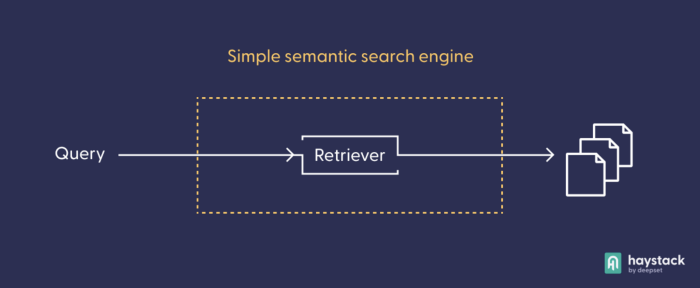
检索器根据查询选择最佳文档。在使用基于 Transformer 的检索模型之前,您需要索引您的文档;也就是说,预处理它们,并让检索模型将它们转换为向量表示,以便以后进行比较。在更复杂的管道架构中,检索器通常充当一个“筛子”,将少量预选文档呈现给下一个节点,从而减轻计算成本更高的模型处理大量文本的负担。
使用 Haystack Python 框架构建您的语义搜索系统
我们将使用 FAISS 文档存储 作为我们的数据库,它针对处理向量表示进行了优化。请确保安装了启用了 FAISS 支持的 Haystack(我们使用版本 1.11)。
pip install git+https://github.com/deepset-ai/haystack.git
pip install 'farm-haystack[faiss]'
然后,您可以开始读取和转换文件,将它们存储为本地的 .txt 文档,位于 datapath 下。如果您想使用我们在此项目中使用的 .txt 文件,可以从 这个 Google Drive 文件夹 下载。Haystack 的 convert_files_to_docs 函数会自动识别文件的格式,并将其转换为 Document 类的对象,然后可以将其读入文档存储。
from haystack.utils import convert_files_to_docs
all_docs = convert_files_to_docs(dir_path=datapath, split_paragraphs = "True")
现在,导入 FAISSDocumentStore 类,初始化文档存储,并添加文档。
from haystack.document_stores.faiss import FAISSDocumentStore
document_store = FAISSDocumentStore(faiss_index_factory_str="Flat", similarity="cosine")
document_store.write_documents(all_docs)
接下来,导入检索器类,并使用您想用于此任务的检索模型对其进行初始化。将 top_k 参数(检索器返回的文档数量)设置为 3。
from haystack.nodes import EmbeddingRetriever
model = 'sentence-transformers/multi-qa-mpnet-base-dot-v1'
retriever = EmbeddingRetriever(document_store=document_store, use_gpu=True, embedding_model=model, top_k=3)
现在,您需要通过运行检索器模型来更新文档存储中的文档。这也被称为索引。由于 Transformer 模型需要处理数据库中的所有文档,因此此步骤可能需要几分钟时间。
document_store.update_embeddings(retriever)
在索引了您的文档之后,终于可以设置管道了,导入类并使用检索器对其进行初始化。
from haystack.pipelines import DocumentSearchPipeline
semantic_search_pipeline = DocumentSearchPipeline(retriever=retriever)
您的 Python 语义搜索引擎已启动并运行
现在您的文档已存储并索引在文档存储中,并且您的管道已设置并连接到它,是时候提问了。请记住,由于您使用的是文档搜索管道,因此结果将是文档而不是答案。您可以从以下内容开始:
question = "What's a good machine for cutting grass?"
prediction = semantic_search_pipeline.run(query=question)
prediction 变量存储了一个字典。快速查看其内容。
print(prediction.keys())
>>> dict_keys(['documents', 'root_node', 'params', 'query', 'node_id'])
documents 键是最有趣的:它包含根据模型匹配您查询的文档。查看每个结果的前 100 个字符。
for i, pred in enumerate(prediction['documents']):
print(i, pred.content[:100] + '\n')
>>> 0 Fast, clean and dependable mowing. Land Pride Flail Mowers are the perfect choice for schools and ot
>>> 1 All-Flex Mowers. Our name says it all! Maintaining a large area of grass in a picturesque setting is
>>> 2 - Steep Slopes 0° to 31° - High production mowing of roadways and parks - Steering wheel steered for
这些看起来很棒!显然,语言模型可以理解“割草”与“修剪”这个动作非常相似。如果您还记得底层模型是一个未针对园艺特定主题(或当前文本)进行微调的通用语言模型,那么这些模型的威力就显而易见了。现在尝试一个不同的查询:
question = "What are the best tools for digging a ditch?"
prediction = semantic_search_pipeline.run(query=question)
再次打印前三个结果。
>>> 0 Double Pocket Chart Stand with Storage Assembly Instructions Contents: A. Bottom Side Pole (4) B. Mi
>>> 1 Ideal for ditching, road grading and all-around farm use. RBT40 SERIES 65 - 100 HP -- 84" 96" 108" Ca
>>> 2 Small farms and food plots ... just right for the Land Pride disc. Land Pride Disc Harrows break up th
这些结果确实看起来很相关——但顺序可以改进。毕竟,第二个结果听起来是理想的匹配。您可以将检索模型替换为 sentence-transformers/multi-qa-mpnet-base-dot-v1 模型,它更适合此 非对称语义搜索 任务。但是,在本教程中,我们将向您展示一种改进语义搜索引擎的不同方法。
扩展您的 Python 语义搜索引擎
作为使用更复杂模型的替代方法,您可以扩展您的管道,通过设置一个自定义设计,该设计除了检索器之外还包含一个 排序器节点。排序器使用自己的基于 Transformer 的语言模型来重新排序从检索器接收的文档。
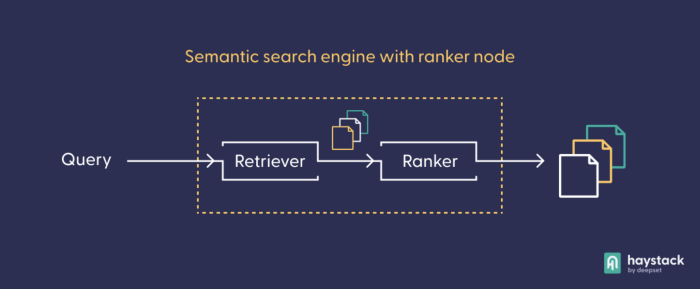
首先,您需要导入两个额外的类——通用管道和排序器节点——并实例化它们。
from haystack import Pipeline
from haystack.nodes import SentenceTransformersRanker
pipeline = Pipeline()
ranker_model = "cross-encoder/ms-marco-MiniLM-L-12-v2"
ranker = SentenceTransformersRanker(model_name_or_path=ranker_model, top_k=3)
接下来,将这两个模块——检索器和排序器——添加到您的管道对象中。每当您向管道添加节点时,都需要为其指定一个名称,以便您可以引用它。您还需要通过指定每个节点的输入源来告诉管道节点如何相互连接。默认情况下,第一个输入始终被指定为 Query。
pipeline.add_node(component=retriever, name='Retriever', inputs=['Query'])
pipeline.add_node(component=ranker, name='Ranker', inputs=['Retriever'])
再次打印前三个文档的第一部分。
>>> 0 Ideal for ditching, road grading and all-around farm use. RBT40 SERIES 65 - 100 HP -- 84" 96" 108" Ca
>>> 1 Small farms and food plots ... just right for the Land Pride disc. Land Pride Disc Harrows break up th
>>> 2 Double Pocket Chart Stand with Storage Assembly Instructions Contents: A. Bottom Side Pole (4) B. Mi
将排序器添加到您的语义搜索引擎确实可以改进您的结果,尤其是在您对检索器的结果不满意的情况下。从这里开始,您的创造力将无止境。例如,检索器-排序器设置可以与 摘要节点 结合使用,在一个流行的 自定义管道设置 中。当然,我们不能不提到语义搜索在大多数开放域 问答(QA)应用中的关键作用。
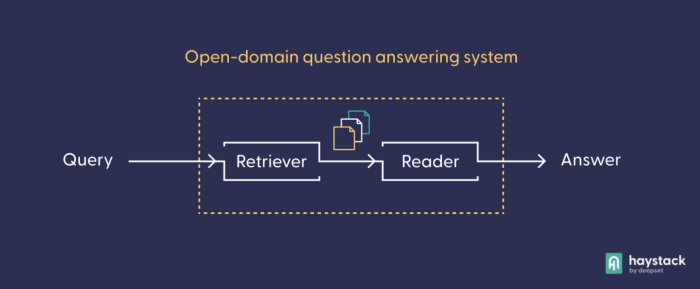
由于问答模型的计算成本很高,因此需要安装一个粗糙的“筛子”来从大型语料库中提取查询的最佳答案候选。像您之前使用的检索模型这样的语义搜索模型就具有这种特性,因此它们是所有开放域问答系统的组成部分。在问答管道中,读取器节点包含实际的 QA 模型,它只“阅读”检索器从大型语料库中预先选择的文档。
加入 Haystack 社区
对于希望实现语义搜索系统的 Python 程序员来说,Haystack 是首选框架。此外,任何想要在其产品(无论是应用程序、网站还是其他产品)中使用最新的 NLP 模型的人,都可以通过 Haystack 模块化和面向应用的特性轻松实现。
如果您想调整您的语义搜索系统并使用不同的数据库作为文档存储,请查看我们的 文档。
您有更多问题,或者只是想看看在应用 NLP 领域其他人都在做什么?我们在 Discord 上有一个充满活力的 NLP 社区,对所有人开放。认识其他开源爱好者,并直接与我们的团队成员交流。
想为您的管道添加更多节点,微调您自己的模型,或创建新的数据集?为什么不看看 GitHub 上的 Haystack 仓库 — 顺便给我们点个赞?
