

Haystack 中增强 RAG 管道:介绍 DiversityRanker 和 LostInTheMiddleRanker
最新的 Ranker 如何优化检索增强生成(RAG)管道中的 LLM 上下文窗口利用率
2023 年 8 月 29 日几年前,自然语言处理(NLP)和长篇问答(LFQA)的最新进展听起来就像是科幻小说中的情节。谁能想到,如今我们拥有能够像专家一样精确地回答复杂问题,同时还能从海量数据源中即时合成答案的系统?LFQA 是一种检索增强生成(RAG)的类型,近年来取得了显著的进步,它利用了大型语言模型(LLM)的最佳检索和生成能力。
但是,如果我们能进一步优化这个设置呢?如果我们能优化 RAG 选择和利用信息的方式以提高其性能呢?本文将介绍两个旨在改进 RAG 的创新组件,并结合 LFQA 中的具体示例,这些示例基于最新的研究和我们的经验——DiversityRanker 和 LostInTheMiddleRanker。
将 LLM 的上下文窗口想象成一顿美食盛宴,每一段都是一道独特、风味十足的食材。正如一道美食杰作需要多样化、高质量的食材一样,LFQA 问答也需要一个充满高质量、多样化、相关且不重复的段落的上下文窗口。
在 LFQA 和 RAG 的复杂世界中,充分利用 LLM 的上下文窗口至关重要。任何浪费的空间或重复的内容都会限制我们可以提取和生成的答案的深度和广度。这是一个微妙的平衡,需要恰当地布置上下文窗口中的内容。本文将介绍掌握这种平衡的全新方法,这将增强 RAG 提供精确、全面答案的能力。
让我们一起探索这些激动人心的进展,以及它们如何改进 LFQA 和 RAG。
背景
Haystack 是一个开源框架,为实际的 NLP 构建者提供端到端的解决方案。它支持各种用例,从问答和语义文档搜索一直到 LLM 代理。其模块化设计允许集成最先进的 NLP 模型、文档存储以及当今 NLP 工具箱所需的其他各种组件。
Haystack 的关键概念之一是管道(pipeline)的概念。管道代表了特定组件执行的一系列处理步骤。这些组件可以执行各种文本处理,允许用户通过定义数据如何在管道中流动以及执行其处理步骤的节点的顺序来轻松创建强大且可自定义的系统。
管道在基于 Web 的长篇问答中起着至关重要的作用。它始于 WebRetriever 组件,该组件从 Web 中搜索并检索与查询相关的文档,自动将 HTML 内容剥离为纯文本。但是,一旦我们获取了与查询相关的文档,如何最大限度地利用它们呢?如何填充 LLM 的上下文窗口以最大化答案的质量?如果这些文档尽管高度相关,却重复且数量众多,有时甚至会溢出 LLM 的上下文窗口呢?
这就是我们今天要介绍的组件——DiversityRanker 和 LostInTheMiddleRanker 发挥作用的地方。它们旨在解决这些挑战并改进 LFQA/RAG 管道生成的答案。
DiversityRanker 增强了为 RAG 管道上下文窗口选择的段落的多样性。LostInTheMiddleRanker 通常位于管道中的 DiversityRanker 之后,有助于缓解模型在长上下文的中间访问相关信息时观察到的 LLM 性能下降问题。以下各节将深入探讨这两个组件,并展示它们在实际用例中的有效性。
DiversityRanker
DiversityRanker 是一个新颖的组件,旨在增强 RAG 管道中为上下文窗口选择的段落的多样性。它的工作原理是,多样化的文档集可以提高 LLM 生成更广泛、更深入答案的能力。

DiversityRanker 使用句子转换器(sentence transformers)来计算文档之间的相似度。句子转换器库提供了强大的嵌入模型,用于创建句子、段落甚至整个文档的有意义的表示。这些表示,或称为嵌入,捕捉文本的语义内容,使我们能够衡量两段文本的相似程度。
DiversityRanker 使用以下算法处理文档
-
它首先使用句子转换器模型计算每个文档和查询的嵌入。
-
然后,它选择与查询语义上最接近的文档作为第一个选定的文档。
-
对于剩余的每个文档,它会计算与已选定文档的平均相似度。
-
然后,它选择平均而言与已选定文档最不相似的文档。
-
这个选择过程一直持续到所有文档都被选定,从而得到一个文档列表,其排序从对整体多样性贡献最大的文档到贡献最小的文档。
一个需要注意的技术细节:DiversityRanker 使用贪婪的局部方法来选择排序中的下一个文档,这可能找不到最理想的整体文档排序。DiversityRanker 比相关性更注重多样性,因此它应该放在管道中 TopPSampler 或其他更注重相关性的相似度 Ranker 组件之后。通过在选择最相关文档的组件之后使用它,我们确保从一组已经相关的文档中选择多样化的文档。
LostInTheMiddleRanker
LostInTheMiddleRanker 优化了所选文档在 LLM 上下文窗口中的布局。该组件是一种绕过最近研究 [1] 中发现的问题的方法,该研究表明 LLM 在长上下文的中间关注相关段落时存在困难。LostInTheMiddleRanker 会交替地将最佳文档放置在上下文窗口的开头和结尾,从而使 LLM 的注意力机制更容易访问和使用它们。为了理解 LostInTheMiddleRanker 如何排序给定文档,请想象一个简单的示例,其中文档由 1 到 10 的单个数字按升序组成。LostInTheMiddleRanker 将这十个文档按以下顺序排序:[1 3 5 7 9 10 8 6 4 2]。
尽管这项研究的作者专注于问答任务——从文本中提取答案的相关跨度——但我们推测,在生成答案时,LLM 的注意力机制在关注上下文开头和结尾的段落时也会更容易。
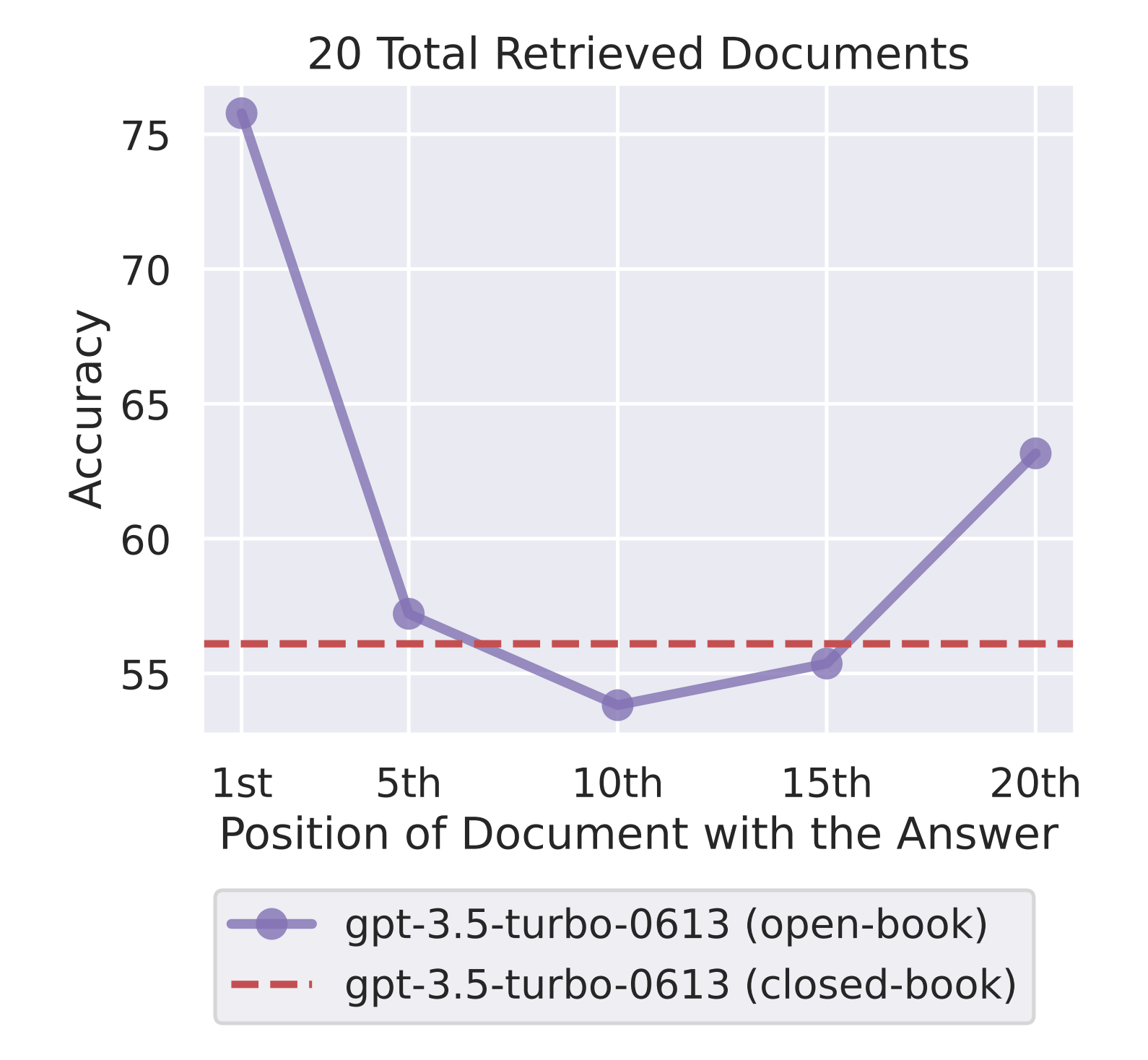
LostInTheMiddleRanker 最好作为 RAG 管道中的最后一个 Ranker,因为给定文档已经根据相似度(相关性)进行了选择,并按多样性进行了排序。
在管道中使用新的 Ranker
在本节中,我们将探讨 LFQA/RAG 管道的实际用例,重点介绍如何集成 DiversityRanker 和 LostInTheMiddleRanker。我们还将讨论这些组件如何相互以及与其他管道中的组件进行交互。
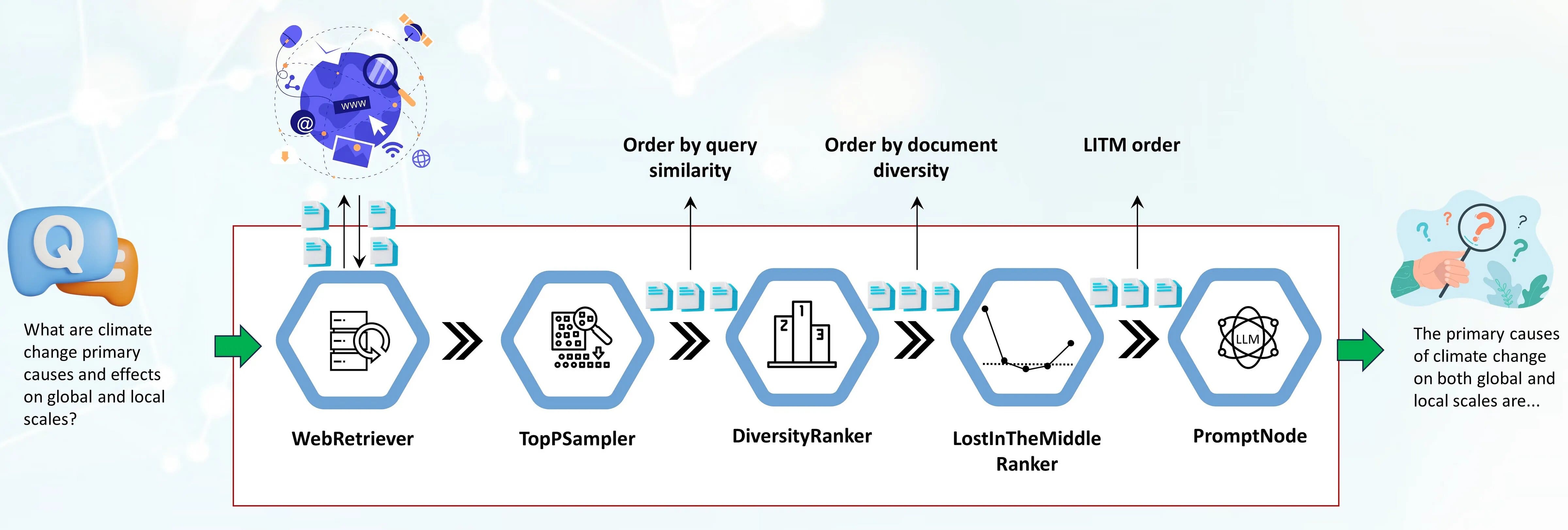
管道中的第一个组件是 WebRetriever,它使用编程搜索引擎 API(SerperDev、Google、Bing 等)从 Web 中检索与查询相关的文档。检索到的文档首先会被剥离 HTML 标签,转换为纯文本,并可以选择预处理成更短的段落。然后,它们依次传递给 TopPSampler 组件,该组件根据与查询的相似度选择最相关的段落。
在 TopPSampler 选择了一组相关的段落后,它们会被传递给 DiversityRanker。DiversityRanker 则根据段落的多样性对段落进行排序,减少了 TopPSampler 排序文档的重复性。
然后,选定的文档会被传递给 LostInTheMiddleRanker。如前所述,LostInTheMiddleRanker 将最相关的段落放置在上下文窗口的开头和结尾,同时将排名最差的文档推到中间。
最后,合并后的段落被传递给 PromptNode,PromptNode 根据这些选定的段落来调整 LLM 的回答。
新的 Ranker 已合并到 Haystack 的主分支中,并将包含在 2023 年 8 月底发布的 1.20 版本中。我们在项目的示例文件夹中包含了一个新的 LFQA/RAG 管道演示。
该演示展示了如何轻松地将 DiversityRanker 和 LostInTheMiddleRanker 集成到 RAG 管道中,以提高生成答案的质量。
案例研究
为了演示包含这两个新 Ranker 的 LFQA/RAG 管道的有效性,我们将使用一组半打(6个)需要详细答案的问题。这些问题包括:“导致文艺复兴的关键事件和影响是什么;这些发展如何塑造了现代西方文化?”、“在全球和地方尺度上,气候变化的主要原因是什么?”等等。为了很好地回答这些问题,LLM 需要广泛的历史、政治、科学和文化资源,这使得它们非常适合我们的用例。
比较带有两个新 Ranker(优化管道)和没有 Ranker 的 RAG 管道(非优化管道)生成的答案,需要进行涉及人工专家判断的复杂评估。为了简化评估并主要评估 DiversityRanker 的效果,我们计算了注入 LLM 上下文的上下文文档的平均成对余弦距离。我们将两个管道的上下文窗口大小限制为 1024 个词。通过运行这些示例 Python 脚本 [2],我们发现优化后的管道在注入 LLM 上下文的文档的成对余弦距离方面平均增加了 20-30% [3]。这种成对余弦距离的增加本质上意味着使用的文档更加多样化(且重复性更低),从而为 LLM 提供了更广泛、更丰富的段落范围来提取答案。我们将在我们未来的文章中对 LostInTheMiddleRanker 及其对生成答案的影响进行评估。
结论
我们探讨了 Haystack 用户如何通过使用两个创新 Ranker:DiversityRanker 和 LostInTheMiddleRanker 来增强他们的 RAG 管道。
DiversityRanker 确保 LLM 的上下文窗口填满了多样化、不重复的文档,为 LLM 合成答案提供了更广泛的段落范围。同时,LostInTheMiddleRanker 优化了最相关段落在上下文窗口中的放置,使模型更容易访问和利用最佳支持文档。
我们的小型案例研究通过计算优化 RAG 管道(带有两个新 Ranker)和非优化管道(未使用 Ranker)中注入 LLM 上下文的文档的平均成对余弦距离,证实了 DiversityRanker 的有效性。结果表明,优化后的 RAG 管道将平均成对余弦距离增加了约 20-30%。
我们已经证明了这些新的 Ranker 如何能够增强长篇问答和其他 RAG 管道。通过继续投资和扩展这些以及类似的想法,我们可以进一步提高 Haystack RAG 管道的功能,让我们更接近于创造出看起来更像魔法而非现实的 NLP 解决方案。
参考文献
[1] “Lost in the Middle: How Language Models Use Long Contexts” 访问 https://arxiv.org/abs/2307.03172
[2] 脚本:https://gist.github.com/vblagoje/430def6cda347c0b65f5f244bc0f2ede
[3] 脚本输出(答案):https://gist.github.com/vblagoje/738253f87b7590b1c014e3d598c8300b
