
使用 fastRAG 和 Haystack 进行 CPU 优化嵌入模型
了解如何使用 CPU 上的优化嵌入模型来降低延迟,并提高检索和索引的吞吐量
2024 年 8 月 1 日检索增强生成 (RAG) 流水线的一个主要且关键的组成部分是嵌入过程,它通过将原始文本转换为机器可读的向量表示,为高效信息检索奠定了基础。嵌入模型将文本数据编码为密集向量,捕捉语义和上下文含义。这些模型用于为查询(用于检索)和文档(用于索引和重新排序)创建嵌入。因此,通过量化优化这些模型可以改进我们的 RAG 应用,提供
- 更高的吞吐量:有助于减少创建或更新向量存储所需的时间。
- 更低的延迟:改善实时体验,因为创建查询嵌入和重新排序文档是根据用户输入在线完成的。
- 降低内存和成本要求:通过量化到
int8进行优化可以减小内存占用,并降低运行此类模型的成本。
这就是像英特尔实验室的 fastRAG 这样的专业框架发挥作用的地方,它们提供针对特定硬件和用例量身定制的增强功能,并结合 Haystack 提供的广泛功能集。
fastRAG:英特尔实验室的高效 RAG 框架
fastRAG 是英特尔实验室为高效和优化的 RAG 流水线开发的研究框架。它包含了最先进的大型语言模型 (LLM) 和信息检索功能。fastRAG 完全兼容 Haystack,并包含新颖高效的 RAG 模块,这些模块专为在 Intel 硬件上有效部署而设计,包括客户端和服务器 CPU (Xeon) 以及 Intel Gaudi AI 加速器。
fastRAG GitHub 存储库提供了有关框架中每个组件的广泛文档、全面的示例以及用于优化后端和易于安装的说明。该框架利用流行的深度学习框架(如 PyTorch)的优化扩展。
其中一个扩展是 Optimum Intel,这是一个开源库,扩展了 Hugging Face Transformers 库,并利用 Intel® Advanced Vector Extensions 512 (Intel® AVX-512)、Vector Neural Network Instructions (VNNI) 和 Intel® Advanced Matrix Extensions (Intel® AMX) 在 Intel CPU 上加速模型。AMX 加速推理已在 PyTorch 2.0 和 Intel Extension for PyTorch (IPEX) 中引入。
Intel 和 deepset 是 Open Platform for Enterprise AI (OPEA) 的关键成员,这是 LF AI & Data Foundation 最近宣布的一个项目。OPEA 旨在通过推动跨多元化异构生态系统的互操作性来加速企业安全、经济高效的生成式 AI (GenAI) 部署,并从 RAG 开始。
优化过程:量化
优化过程包括使用校准数据集量化模型,并利用 IPEX 等优化后端来支持 Intel Xeon CPU。量化通过将权重和激活从浮点(例如 32 位)转换为较低位表示(例如 8 位整数)来减小模型大小。这使得模型更小、更快、更具成本效益,而精度损失可忽略不计。对 BGE-large 的基准测试结果表明,在使用该模型的 int8 版本时,索引过程可能提速 10 倍。
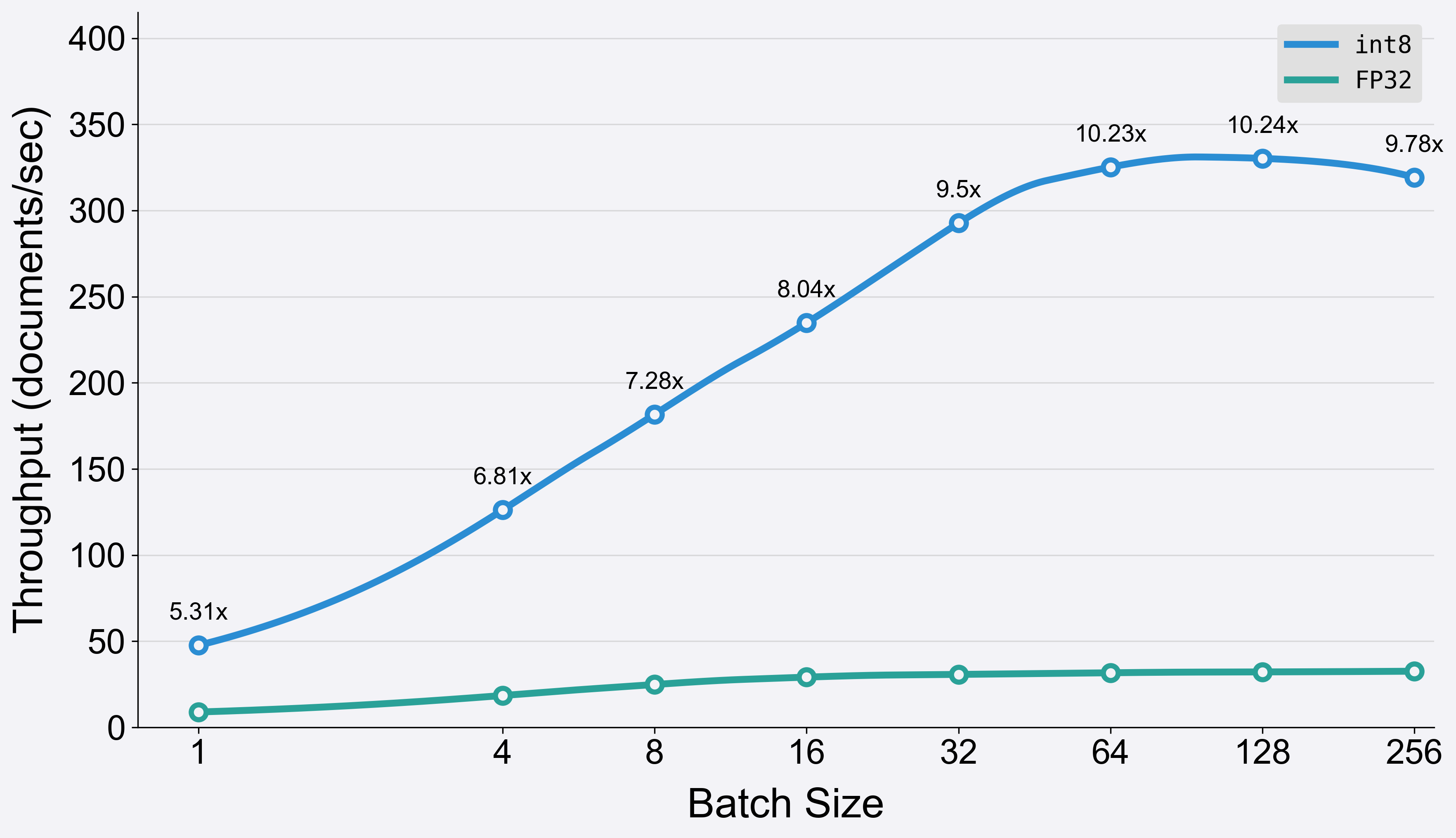
请注意,基准测试结果仅关注 BGE-large 模型版本编码过程所花费的时间。为更清晰地比较模型的编码效率,已将标记化所需的时间排除在这些测量之外。
提供了从头开始量化模型的综合指南。此外,英特尔的 Hugging Face 模型中心提供三个量化的 BGE 嵌入模型。
组件
fastRAG 已支持作为 Haystack 的集成,通过 IPEX 支持扩展了 Haystack 的文档和文本嵌入器。此外,fastRAG 还包含两个双编码器相似度排序器
-
IPEXSentenceTransformersDocumentEmbedder 和 IPEXSentenceTransformersTextEmbedder - 通过 IPEX 使用
int8量化嵌入模型的嵌入器组件,可以嵌入Document和文本输入。 - BiEncoderSimilarityRanker - 一个双编码器相似度排序器,它根据查询和嵌入器重新排序文档列表。双编码器模型用于独立编码文档和查询,比交叉编码器更有效。
-
IPEXBiEncoderSimilarityRanker - 一个基于 IPEX 的 BiEncoderSimilarityRanker,用于与
int8量化嵌入模型一起使用。
在此处查看 fastRAG 组件的完整列表。
精度相同,速度提升 9 倍
在优化模型时,保持具有竞争力的检索精度很重要。我们使用 MTEB 的重新排序和检索子任务,以及三个 BGE 双编码器嵌入模型,评估了优化(量化和校准)对性能的影响。对于 BGE-large 模型,如表格所示,优化过程对性能的影响与原始模型相比微乎其微。
| int8 | FP32 | % 差异 | |
|---|---|---|---|
| 重新排序 | 0.5997 | 0.6003 | -0.108% |
| 检索 | 0.5346 | 0.5429 | -1.53% |
其他 BGE 模型的结果可以在这里找到。
让我们比较一下使用两种不同模型对随机文本进行编码作为段落
-
BAAI/bge-large-en-v1.5 (
fp32) 配合 Haystack 的SentenceTransformersDocumentEmbedder -
Intel/bge-large-en-v1.5-rag-int8-static (
int8) 配合 fastRAG 的IPEXSentenceTransformersDocumentEmbedder
下面的脚本创建随机段落,每个段落用分词器编码后会变成 256 个 token,并使用相同的 fp32 和 int8 版本模型对 16384 个段落进行编码。
import time
from datasets import load_dataset
from haystack import Document
from fastrag.embedders import IPEXSentenceTransformersDocumentEmbedder
from haystack.components.embedders import SentenceTransformersDocumentEmbedder
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("Intel/bge-large-en-v1.5-rag-int8-static")
def generate_text_for_fixed_length(seq_length):
text = ""
while True:
# Tokenize the current text
token_ids = tokenizer(text)["input_ids"]
# Check if the tokenized sequence has reached the desired length
if len(token_ids) == seq_length:
break
elif len(token_ids) > seq_length:
text = text[:-1]
# Add a random character to the text
text += random.choice(string.ascii_letters + string.digits + string.punctuation + " ")
return text
seq_length = 256
generated_texts = []
for _ in tqdm(range(1000), desc="Generating texts"):
generated_texts.append(generate_text_for_fixed_length(seq_length))
generated_texts = generated_texts * 20
docs = [Document(content=doc) for doc in generated_texts]
BATCH_SIZE_LIST = [1, 4, 8, 16, 32, 64, 128, 256]
for BATCH_SIZE in BATCH_SIZE_LIST:
print("Running with BATCH_SIZE:", BATCH_SIZE)
ipex_doc_embedder = IPEXSentenceTransformersDocumentEmbedder(
model="Intel/bge-large-en-v1.5-rag-int8-static",
batch_size=BATCH_SIZE
)
haystack_doc_embedder = SentenceTransformersDocumentEmbedder(
model="BAAI/bge-large-en-v1.5",
batch_size=BATCH_SIZE
)
ipex_doc_embedder.warm_up()
haystack_doc_embedder.warm_up()
# Measure runtime for SentenceTransformersDocumentEmbedder
start_time = time.time()
documents_with_embeddings = haystack_doc_embedder.run(docs[:16384])
end_time = time.time()
haystack_doc_embedder_runtime = end_time - start_time
# Measure runtime for IPEXSentenceTransformersDocumentEmbedder
start_time = time.time()
documents_with_embeddings = ipex_doc_embedder.run(docs[:16384])
end_time = time.time()
ipex_doc_embedder_runtime = end_time - start_time
print("Runtime for SentenceTransformersDocumentEmbedder:", haystack_doc_embedder_runtime)
print("Runtime for IPEXSentenceTransformersDocumentEmbedder:", ipex_doc_embedder_runtime)
运行时结果表明,在使用第 4 代 Intel Xeon CPU (8480+) 的单插槽和 56 个核心运行时,使用 fastRAG 组件的设置(如上述脚本所示)可以将嵌入过程的速度提高 5.25 倍至 9.3 倍。我们也可以将其转换为吞吐量(越高越好),并查看速度提升的差异。
💡 与之前基准测试结果的速度提升差异是由于 Haystack 组件中的额外处理,主要是标记化过程,该过程在之前的基准测试中已被排除。
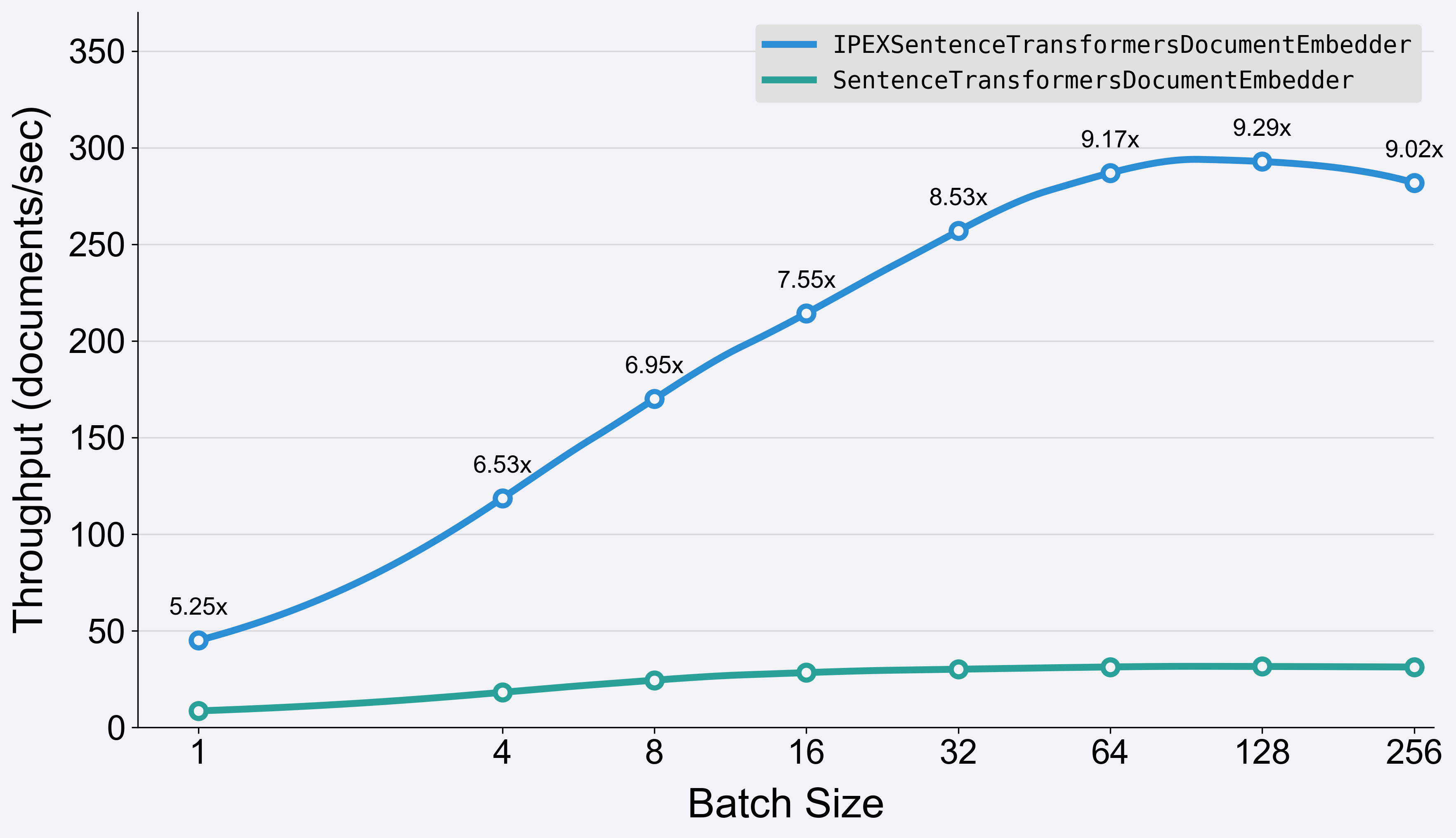
IPEXSentenceTransformersDocumentEmbedder 和 SentenceTransformersDocumentEmbedder 的 BGE-large 模型 int8 和 FP32 版本之间的吞吐量比较💡 量化
int8模型的性能高度依赖于数据的结构。为了获得最佳性能,建议使用静态形状,即相同长度的分词序列。此外,批处理在使用 CPU 后端时非常有效,也可以与动态形状结合使用。这取决于根据数据和硬件调整设置。
💡 我们在运行实验时遵循了此处提供的说明,包括使用
numactl将进程限制在单个插槽上运行,以及使用 TCMalloc。我们建议阅读 IPEX 文档网站上提供的性能调优指南和启动脚本使用。
阅读 Intel fastRAG 团队的 博客,其中包含其他评估和性能基准测试,以获取更多信息。
带有优化嵌入模型的 RAG
在本节中,我们将探讨如何在 RAG 流水线中使用优化模型。我们将使用嵌入器模型来比标准的 fp32 Hugging Face 模型更快地创建初始索引。此外,我们将演示一个简单的问答流水线,该流水线使用优化的双编码器排序器。该排序器重新排序检索到的文档,以增强用于 LLM 提示的文档列表,从而提高检索过程的整体性能。
安装
首先,通过 fastRAG 安装 fastRAG、Optimum Intel 和 Haystack
pip install fastrag[intel]
索引数据
我们将从初始化一个内存中的数据存储开始,并从 fastRAG 加载文档嵌入器组件。IPEXSentenceTransformersDocumentEmbedder 可以像任何其他组件一样无缝集成到 Haystack 流水线中。
from haystack import Document
from haystack.document_stores.in_memory import InMemoryDocumentStore
from fastrag.embedders import IPEXSentenceTransformersDocumentEmbedder, IPEXSentenceTransformersTextEmbedder
document_store = InMemoryDocumentStore()
doc_embedder = IPEXSentenceTransformersDocumentEmbedder(model="Intel/bge-small-en-v1.5-rag-int8-static")
doc_embedder.warm_up()
现在,让我们加载一个数据集。我们将使用不需要进一步处理的 bilgeyucel/seven-wonders 数据集
from datasets import load_dataset
from haystack import Document
dataset = load_dataset("bilgeyucel/seven-wonders", split="train")
docs = [Document(content=doc["content"], meta=doc["meta"]) for doc in dataset]
接下来,我们嵌入文档并将它们写入索引
documents_with_embeddings = doc_embedder.run(docs)
document_store.write_documents(documents_with_embeddings["documents"])
RAG 管道
我们继续初始化组件,以构建一个代表简单问答 RAG 示例的流水线,其中包括嵌入器、检索器、重新排序器、提示模板和生成器。值得注意的是,IPEXSentenceTransformersTextEmbedder 和 IPEXBiEncoderSimilarityRanker 可以与 Haystack 流水线中的其他组件无缝集成。
在 📚 教程:创建您的第一个带检索增强的 QA 流水线 中了解如何使用 Haystack 创建 RAG 流水线。
from haystack.components.retrievers.in_memory import InMemoryEmbeddingRetriever
from fastrag.rankers import IPEXBiEncoderSimilarityRanker
query_embedder = IPEXSentenceTransformersTextEmbedder(model="Intel/bge-small-en-v1.5-rag-int8-static")
retriever = InMemoryEmbeddingRetriever(document_store, top_k=100)
reranker = IPEXBiEncoderSimilarityRanker("Intel/bge-large-en-v1.5-rag-int8-static", top_k=5)
我们创建了一个简单的 RAG 提示模板
from haystack.components.builders import PromptBuilder
template = """
You are a helpful AI assistant. You are given contexts and a question.
You must answer the question using the information given in the context.
Context:
{% for document in documents %}
{{ document.content }}
{% endfor %}
Question: {{question}}
Answer:
"""
prompt_builder = PromptBuilder(template=template)
我们使用 HuggingFaceTB/SmolLM-1.7B-Instruct 模型(使用本地 Hugging Face 模型 SmolLM-1.7B-Instruct)初始化一个 HuggingFaceLocalGenerator 来生成答案
from haystack.components.generators import HuggingFaceLocalGenerator
generator = HuggingFaceLocalGenerator(model="HuggingFaceTB/SmolLM-1.7B-Instruct",
task="text-generation",
generation_kwargs={
"max_new_tokens": 100,
"do_sample": False,
})
最后,我们创建流水线
from haystack import Pipeline
pipe = Pipeline()
pipe.add_component("retriever", retriever)
pipe.add_component("embedder", query_embedder)
pipe.add_component("reranker", reranker)
pipe.add_component("prompt_builder", prompt_builder)
pipe.add_component("llm", generator)
pipe.connect("embedder", "retriever")
pipe.connect("retriever", "reranker.documents")
pipe.connect("reranker", "prompt_builder.documents")
pipe.connect("prompt_builder", "llm")
尝试流水线
让我们用一个实际问题来测试流水线
question = 'What does Rhodes Statue look like?'
response = pipe.run({'embedder': {'text': question},
'reranker': {'query': question},
'prompt_builder': {'question': question}})
print(response['llm']['replies'][0])
>>> The statue was a Colossus of Rhodes, a statue of the Greek sun god Helios that stood in the city of Rhodes and was one of the Seven Wonders of the Ancient World. It is said to have stood about 100 feet (30 meters) tall, making it the tallest statue of its time. The statue was built by Chares of Lindos between 280 and 240 BC. It was destroyed by an earthquake in 226
摘要
在这个简短的博客中,我们强调了 CPU 优化嵌入模型在准确性和性能方面的重要优势,并演示了如何将这些组件无缝集成到您的 Haystack 流水线中。fastRAG 是这些进步的前沿,它是一个致力于将基于 Intel 的优化集成到 Haystack 中的研究库。
fastRAG 团队提供了关于量化过程的深入信息以及在第 4 代 Xeon 处理器上进行的广泛基准测试。要深入了解优化,请阅读这篇详细的 博客文章,并加入我们的 Discord 社区 探索 Haystack。

